1.基础环境搭建
1.1运行环境说明
1.1.1硬软件环境
主机操作系统:Windows 64位,四核8线程,主频3.2G,8G内存
虚拟软件:VMware Workstation Pro
虚拟机操作系统:CentOS7 64位,单核,2G内存
1.1.2集群网络环境
集群包含三个节点,节点之间可以免密码SSH访问,节点IP地址和主机名分布如下:
| 序号 |
IP地址 |
机器名 |
核数/内存 |
用户名 |
| 1 |
192.168.1.61 |
hadoop1 |
1核/2G |
hadoop |
| 2 |
192.168.1.62 |
hadoop2 |
1核/1G |
hadoop |
| 3 |
192.168.1.63 |
hadoop3 |
1核/1G |
hadoop |
1.1.3安装使用工具
1.1.3.1Linux文件传输工具
使用的WinScp,该工具顶部为工具的菜单和快捷方式,中间部分左面为本地文件目录,右边为远程文件目录,可以通过拖拽等方式实现文件的下载与上传,如下图所示:

1.1.3.2Linux命令行执行工具
使用的XShell提供了远程命令执行,如下图所示:
1.2搭建主节点机器环境
1.2.1下载安装虚拟机 VMware Workstation 12 Pro、安装CentOS7


1.2.2 设置系统环境
1.2.2.1设置机器名
以 root 用户登录,使用#vi /etc/sysconfig/network 打开配置文件,设置机器名称,新机器名在重启后生效。
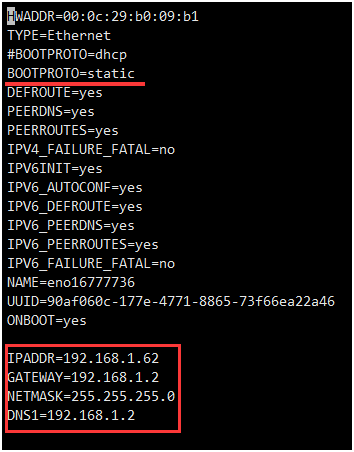
1.2.2.2设置静态ip
cd /etc/sysconfig/network-scripts/
sudo vi ifcfg-eno16777736

BOOTPROTO=static #dhcp改为static(修改)
IPADDR=192.168.1.61 #静态IP(增加)
GATEWAY=192.168.1.2 #默认网关,虚拟机安装的话,通常是2,也就是VMnet8的网关设置(增加)
NETMASK=255.255.255.0 #子网掩码(增加)
DNS1=192.168.1.2 #DNS 配置
重启网络服务:
service network restart
查看网络
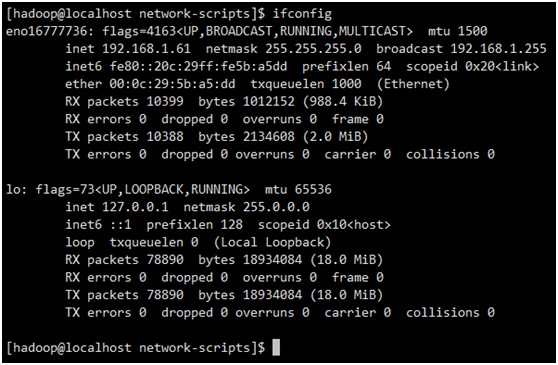
ifconfig
1.2.2.3设置host映射文件
sudo vi /etc/hosts
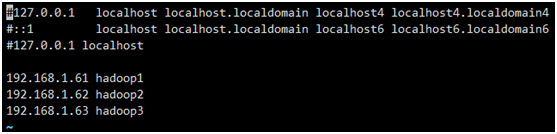
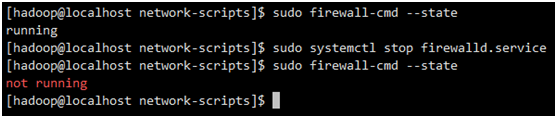
1.2.2.4关闭防火墙
sudo firewall-cmd --state #查询防火墙状态
sudo systemctl stop firewalld.service #关闭防火墙
1.2.2.5关闭SElinux
使用getenforce命令查看是否关闭

如果不是disabled,修改/etc/selinux/config 文件,将SELINUX=enforcing改为SELINUX=disabled,执行该命令后重启机器生效。
1.2.3 配置运行环境
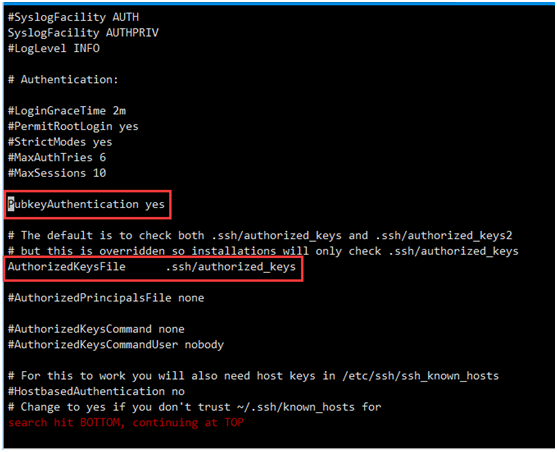
1.2.3.1修改SSH配置文件
sudo vi /etc/ssh/sshd_config
开放如下配置:
PubkeyAuthentication yes
AuthorizedKeysFile .ssh/authorized_keys
配置后重启服务
service sshd restart
1.2.3.2增加hadoop组和用户
使用如下命令增加hadoop 组和hadoop 用户(密码)
#groupadd -g 1000 hadoop
#useradd -u 2000 -g hadoop hadoop
#passwd hadoop
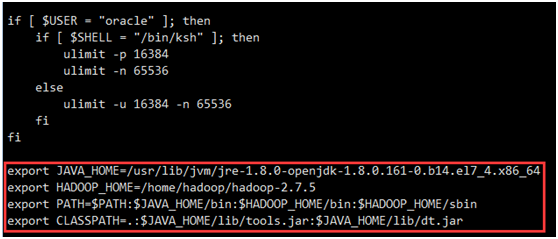
1.2.3.3JDK安装及配置
yum install java-1.8.0-openjdk
使用root用户配置/etc/profile文件
生效该配置
source /etc/profile
验证
java -version
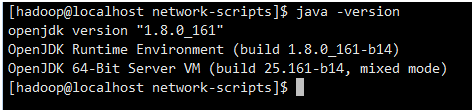
1.2.3.4Scala安装及配置
下载Scala安装包
http://www.scala-lang.org/download/2.10.4.html
用WinScp上传到/home/hadoop/
解压缩 scala-2.10.4.tgz
tar -zxf scala-2.10.4.tgz

使用root用户配置/etc/profile文件

生效该配置
source /etc/profile
验证
scala -version
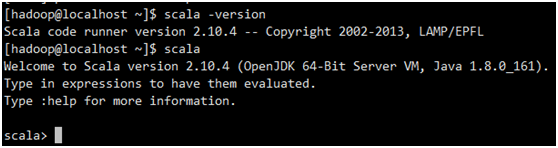
1.3搭建从节点机器环境
1.3.1 克隆主节点机器

1.3.2 配置从节点机器名和静态ip
以 root 用户登录,使用#vi /etc/sysconfig/network 打开配置文件,设置机器名称,新机器名在重启后生效。
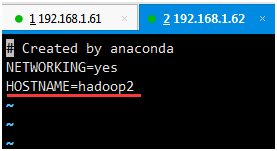
cd /etc/sysconfig/network-scripts/
sudo vi ifcfg-eno16777736
1.3.3 配置SSH免密登录
1.使用hadoop用户登录在三个节点中使用如下命令生成私钥和公钥:
cd ~/.ssh/
ssh-keygen -t rsa
2.进入/home/hadoop/.ssh目录
在三个节点中分别把公钥命名为authorized_keys_hadoop1,authorized_keys_hadoop2,authorized_keys_hadoop3,使用命令如下:
cd /home/hadoop/.ssh
cp id_rsa.pub authorized_keys_hadoop1
3.把两个从节点(hadoop2、hadoop3)的公钥使用scp命令传送到hadoop1节点的/home/hadoop/.ssh文件夹中
scp authorized_keys_hadoop2 hadoop@hadoop1:/home/hadoop/.ssh
scp authorized_keys_hadoop3 hadoop@hadoop1:/home/hadoop/.ssh
4.把三个节点的公钥信息保存到authorized_key文件中
使用$cat authorized_keys_hadoop1 >> authorized_keys 命令
5.把该文件分发到其他两个从节点上
使用scp authorized_keys hadoop@hadoop2:/home/hadoop/.ssh把密码文件分发出去。



6. 在三台机器中使用如下设置authorized_keys读写权限
chmod 400 authorized_keys
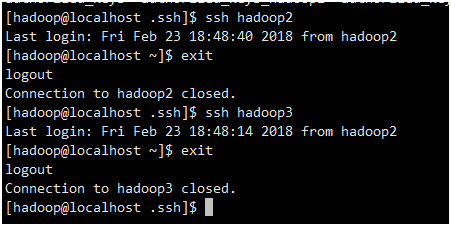
7. 测试ssh免密码登录是否生效
2. Hadoop环境搭建
2.1下载hadoop安装包
下载hadoop安装包
http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.7.5/hadoop-2.7.5.tar.gz
2.2配置hadoop
1.用WinScp上传到/home/hadoop/
解压缩 hadoop-2.7.5.tar.gz
tar -zxf hadoop-2.7.5.tar.gz
使用root用户配置/etc/profile文件

- 修改配置文件(hadoop2.7.1/etc/hadoop/)目录下,core-site.xml, hdfs-site.xml,mapred-site.xml,yarn-site.xml, hadoop-env.sh。
(1)core-site.xml 配置:
<configuration>
<!-- 指定hadoop运行时产生文件的存储路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/hdfs/tmp</value>
</property>
<!-- 指定HDFS(namenode)的通信地址 -->
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop1:9000</value>
</property>
<!-- 允许通过httpfs方式访问hdfs的主机名或者域名 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<!-- 允许访问的客户端的用户组 -->
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
(2)hdfs-site.xml配置:
<configuration>
<!-- 设置namenode的http通讯地址 -->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop1:50070</value>
</property>
<!-- 设置secondarynamenode的http通讯地址 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop1:50090</value>
</property>
<!-- 设置namenode存放的路径 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/hdfs/name</value>
</property>
<!-- 设置datanode存放的路径 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/hdfs/data</value>
</property>
<!-- 设置hdfs副本数量 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- 设置webhdfs -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<!-- 设置permissions -->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
(3)mapred-site.xml配置:
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
<configuration>
<!-- 框架MR使用YARN -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop1:19888</value>
</property>
</configuration>
(4)yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- 设置 resourcemanager 在哪个节点 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop1</value>
</property>
<!-- 设置 resourcemanager.scheduler 在哪个节点 -->
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop1:18030</value>
</property>
<!-- 设置 resourcemanager.webapp 在哪个节点 -->
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop1:8088</value>
</property>
<!-- 设置 resourcemanager.resource-tracker 在哪个节点 -->
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop1:18025</value>
</property>
<!-- 设置 resourcemanager.admin 在哪个节点 -->
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop1:18141</value>
</property>
<!-- 设置 nodemanagerr 内存大小
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1024</value>
</property>
-->
<!-- 设置 nodemanagerr CPU核数
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>1</value>
</property>
-->
<!-- reducer取数据的方式是mapreduce_shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- -->
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
(5)hadoop-env.sh配置:
JAVA_HOME 显式配置一下

(6)slaves配置:
2.3发送至集群其他节点
scp -r hadoop-2.7.5 hadoop@hadoop2:/home/hadoop/
scp -r hadoop-2.7.5 hadoop@hadoop3:/home/hadoop/
2.4运行hadoop
2.4.1 初始化HDFS系统
在hadop2.7.5目录下执行命令:
bin/hdfs namenode -format
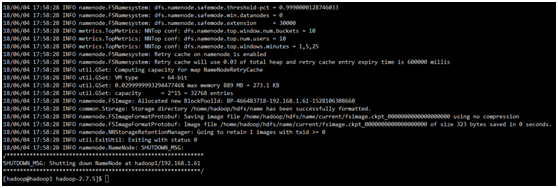
2.4.2 开启NameNode和DateNode守护进程
sbin/start-dfs.sh

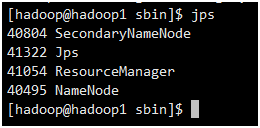
2.4.3 使用jps命令查看进程信息
Hadoop1:
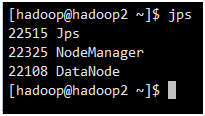
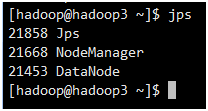
Hadoop2、Hadoop3:
web页面查看:192.168.1.61:50070
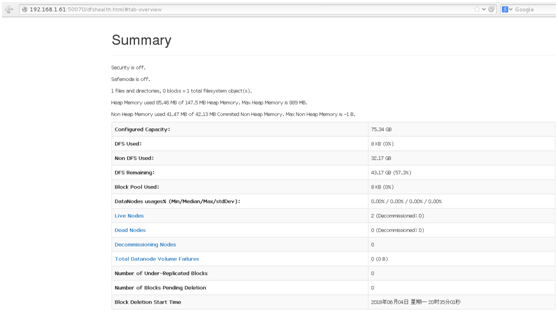
192.168.1.61:8088
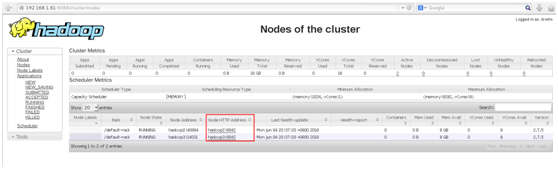
3. Spark环境搭建
3.1下载spark安装包
下载spark安装包
http://spark.apache.org/downloads.html
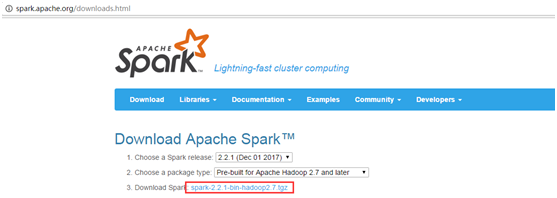
3.2配置spark
1.用WinScp上传到/home/hadoop/
解压缩 spark-2.2.1-bin-hadoop2.7.tgz
tar -zxf spark-2.2.1-bin-hadoop2.7.tgz

使用root用户配置/etc/profile文件

2.修改配置文件(spark-2.2.1/conf)目录下,slaves,spark-env.sh.
(1)打开配置文件conf/slaves
cd /home/hadoop/spark-2.2.1/conf
sudo vi slaves
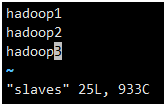
加入slave配置节点
hadoop1
hadoop2
hadoop3
(2) 打开配置文件conf/spark-env.sh
cd /home/hadoop/spark-2.2.1/conf
cp spark-env.sh.template spark-env.sh
sudo vi spark-env.sh
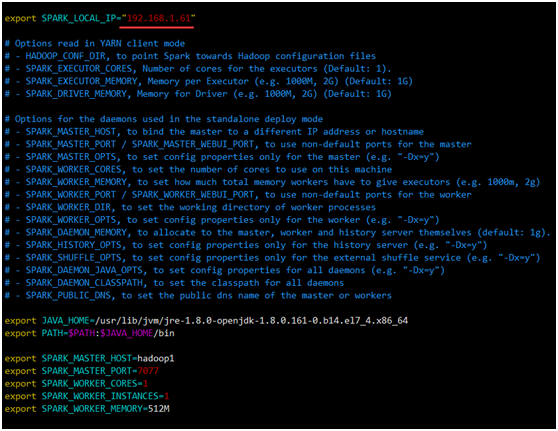
加入Spark环境配置内容,设置hadoop1为Master节点
export SPARK_MASTER_HOST=hadoop1
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_CORES=1
export SPARK_WORKER_INSTANCES=1
export SPARK_WORKER_MEMORY=512M
3.向从节点分发Spark程序
cd /home/hadoop/
scp -r spark-2.2.1 hadoop@hadoop2:/home/hadoop/
scp -r spark-2.2.1 hadoop@hadoop3:/home/hadoop/
4.将从节点 /home/hadoop/spark-2.2.1/conf/ spark-env.sh 中的 SPARK_LOCAL_IP 改为从节点IP
3.3运行spark
3.3.1启动spark
cd /home/hadoop/spark-2.2.1/sbin
./start-all.sh

3.3.2验证启动
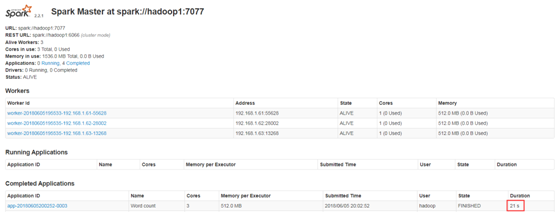
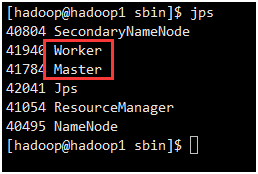
此时在hadoop1上面运行的进程有:Worker和Master
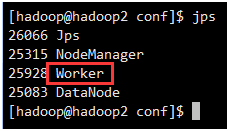
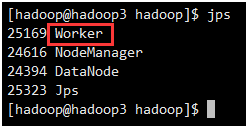
此时在hadoop2和hadoop3上面运行的进程有只有Worker
web页面:192.168.1.61:8080
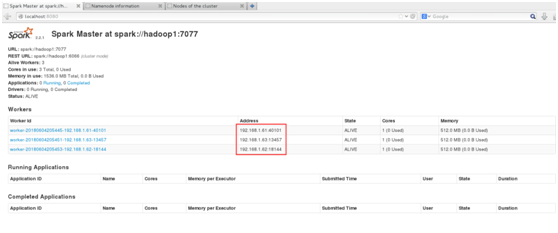
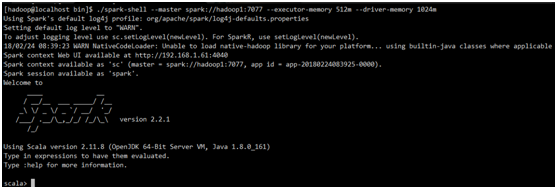
3.3.3验证客户端连接
进入hadoop1节点,进入spark的bin目录,使用spark-shell连接集群
cd /home/hadoop/spark-2.2.1/bin
spark-shell --master spark://hadoop1:7077 --executor-memory 1024m
4. 分别使用Hadoop 和Spark实现词频统计任务
4.1文件内容级输出期望
用Java编写程序,进行wordcount,输入文件用的是一篇介绍云计算的英文文章,命名为cloudComputing.txt
期望输出:文中词语使用频率。意义为:单词的key值 单词的出现次数,并且按照频次由高到低进行显示。
4.2 Hadoop使用java编写程序实现词频统计
步骤:
1.打开eclipse,创建java工程。导入hadoop包和相关配置文件。
2.进入/hadoop安装目录下/share/hadoop/
(1) 、把hdfs文件夹下的jar包和hdfs/lib目录下的jar包导入工程)。
(2) 、把mapreduce文件夹下的jar包和mapreduce/lib目录下的jar包导入工程。
(3) 、把yarn文件夹下的jar包和yarn/lib目录下的jar包导入工程。
(4) 、把common文件夹下的jar包和common/lib下的jar包导入工程。
(5) 、把hadoop安装目录下/etc/hadoop中core-site.xml和hdfs-site.xml文件配置到java工程的src目录下。
3.编写代码程序
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
publicclass WordCount {
/**
* 建立Mapper类TokenizerMapper继承自泛型类Mapper
* Mapper类:实现了Map功能基类
* Mapper接口:
* WritableComparable接口:实现WritableComparable的类可以相互比较。所有被用作key的类应该实现此接口。
* Reporter 则可用于报告整个应用的运行进度,本例中未使用。
*
*/
publicstaticclass TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
/**
* IntWritable, Text 均是 Hadoop 中实现的用于封装 Java 数据类型的类,这些类实现了WritableComparable接口,
* 都能够被串行化从而便于在分布式环境中进行数据交换,你可以将它们分别视为int,String 的替代品。
* 声明one常量和word用于存放单词的变量
*/
privatefinalstatic IntWritable one =new IntWritable(1);
private Text word =new Text();
/**
* Mapper中的map方法:
* void map(K1 key, V1 value, Context context)
* 映射一个单个的输入k/v对到一个中间的k/v对
* 输出对不需要和输入对是相同的类型,输入对可以映射到0个或多个输出对。
* Context:收集Mapper输出的<k,v>对。
* Context的write(k, v)方法:增加一个(k,v)对到context
* 编写Map和Reduce函数.这个Map函数使用StringTokenizer函数对字符串进行分隔,通过write方法把单词存入word中
* write方法存入(单词,1)这样的二元组到context中
*/
publicvoid map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr =new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
publicstaticclass IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result =new IntWritable();
/**
* Reducer类中的reduce方法:
* void reduce(Text key, Iterable<IntWritable> values, Context context)
* 中k/v来自于map函数中的context,可能经过了进一步处理(combiner),同样通过context输出
*/
publicvoid reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum =0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
publicstaticvoid main(String[] args) throws Exception {
/**
* Configuration:map/reduce的j配置类,向hadoop框架描述map-reduce执行的工作
*/
Configuration conf =new Configuration();
String[] otherArgs =new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length !=2) {
System.err.println("Usage: wordcount <in><out>");
System.exit(2);
}
Job job =new Job(conf, "word count"); //设置一个用户定义的job名称
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class); //为job设置Mapper类
job.setCombinerClass(IntSumReducer.class); //为job设置Combiner类
job.setReducerClass(IntSumReducer.class); //为job设置Reducer类
job.setOutputKeyClass(Text.class); //为job的输出数据设置Key类
job.setOutputValueClass(IntWritable.class); //为job输出设置value类
FileInputFormat.addInputPath(job, new Path(otherArgs[0])); //为job设置输入路径
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));//为job设置输出路径
System.exit(job.waitForCompletion(true) ?0 : 1); //运行job
}
}
4.将java文件打包成jar文件DemoWordCount.jar。
5.将DemoWordCount.jar上传到
/home/hadoop/hadoop-2.7.5/share/hadoop/mapreduce

6.Hadoop执行DemoWordCount.jar 统计cloudComputing.txt词频
(1)
# 在hdfs的根目录下建立input、output目录 bin/hdfs dfs -mkdir /input bin /hdfs dfs -mkdir /output # 查看HDFS根目录下的目录结构 bin/hdfs dfs -ls /
结果如下:

(2)
# 上传 bin/hdfs dfs -put /home/hadoop/cloudComputing.txt /input # 查看 bin/hdfs dfs -ls /input
结果如下:

(3)
# 将运行结果保存在/output/cloudComputing目录下 bin/hadoop jar ~/hadoop-2.7.5/share/hadoop/mapreduce/DemoWordCount.jar wordcount /input/cloudComputing.txt /output/cloudComputing # 查看/output/cloudComputing目录下的文件 bin/hdfs dfs -ls /output/cloudComputing
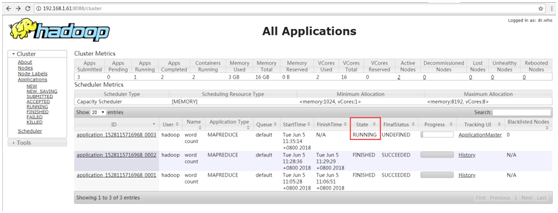
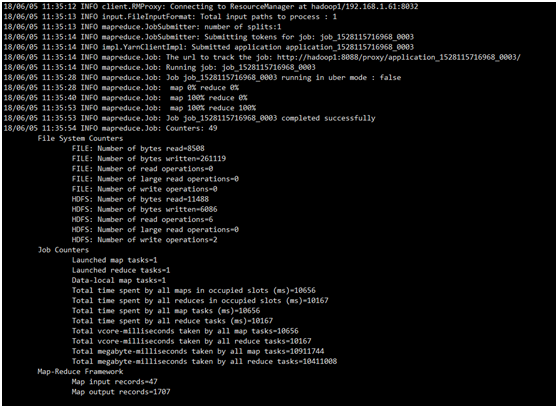
(4)
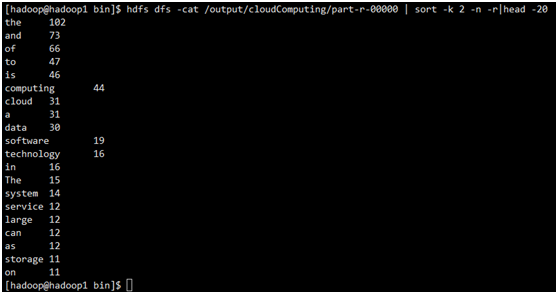
# 查看运行结果 bin/hdfs dfs -cat /output/cloudComputing/part-r-00000 | sort -k 2 -n -r|head -20 #sort中 -k 2 表示用以tab为分隔符的第二个字段来排序 -n表示用数字形式排序 -r表示从大到小排序 显示结果前20行。
结果如下:
C++ 实现:
wordcount_map.cpp
#include <iostream>
#include <string>
using namespace std;
int main(int argc, char** argv)
{
string key;
string value = "1";
while(cin >> key)
{
cout<< key << "\t" << value <<endl;
}
return 0;
}
wordcount_reduce.cpp
#include <iostream>
#include <string>
#include <map>
using namespace std;
int main(int argc, char** argv)
{
string key;
string value;
map<string, int> word2count;
map<string, int>::iterator it;
while(cin >> key)
{
cin >> value;
it = word2count.find(key);
if(it != word2count.end())
{
it->second++;
}
else
{
word2count.insert(make_pair(key, 1));
}
}
for(it = word2count.begin(); it != word2count.end(); it++)
{
cout<< it->first << "\t" << it->second << endl;
}
return 0;
}
编译成可执行文件:
g++ -o mapperC wordcount_map.cpp
g++ -o reduceC wordcount_reduce.cpp
然后,调用 hadoop-streaming-2.7.5.jar
hadoop jar ~/hadoop-2.7.5/share/hadoop/tools/lib/hadoop-streaming-2.7.5.jar -input /input/cloudComputing.txt -output /output/cloudComputing -mapper ~/mapperC -reducer ~/reduceC -file ~/mapperC -file ~/reduceC

4.3 Spark使用scala编写程序实现词频统计
使用 Scala 编写的程序需要使用 sbt 进行编译打包。
(1)安装sbt
下载sbt-launch.jar。并拷贝到/usr/local/sbt
(2)在/usr/local/sbt 中创建 sbt 脚本,添加如下内容:
#!/bin/bash
SBT_OPTS="-Xms512M -Xmx1536M -Xss1M -XX:+CMSClassUnloadingEnabled -XX:MaxPermSize=256M"
java $SBT_OPTS -jar `dirname $0`/sbt-launch.jar "$@"
(3)保存后,为 ./sbt 脚本增加可执行权限。
chmod u+x ./sbt
(4)最后运行如下命令
./sbt sbt-version

(5)编写Scala应用程序
cd ~ # 进入用户主文件夹
mkdir ./sparkapp # 创建应用程序根目录
mkdir -p ./sparkapp/src/main/scala # 创建所需的文件夹结构
vim WordCount.scala
/* wordcount.scala */
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object WordCount {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("Word count")
val sc = new SparkContext(conf) //初始化 SparkContext,SparkContext 的参数 SparkConf 包含了应用程序的信息
val dataFile = sc.textFile("hdfs://hadoop1:9000/input/cloudComputing.txt")
val outputFile = "/home/hadoop/spark.wordcount.out"
val words = dataFile.flatMap(_.split(" "))
val pairs = words.map(word => (word,1))
val wordcount = pairs.reduceByKey(_ + _).map(pair=>(pair._2,pair._1)).sortByKey(false).map(pair=>(pair._2,pair._1))
wordcount.collect.foreach(pair =>println("key:" + pair._1, " value:" + pair._2))
wordcount.saveAsTextFile(outputFile)
sc.stop()
}
}
该程序依赖SparkAPI,因此我们需要通过sbt进行编译打包。在./sparkapp 中新建文件 WordCount.sbt,添加内容如下,声明该独立应用程序的信息以及与 Spark 的依赖关系:
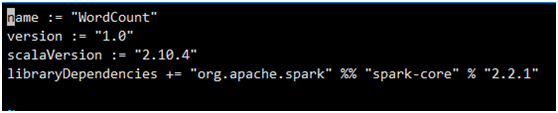
文件WordCount.sbt 需要指明 Spark 和 Scala 的版本。
(6)使用sbt打包Scala程序
为保证 sbt 能正常运行,先执行如下命令检查整个应用程序的文件结构:
cd ~/sparkapp
find .

接着,/usr/local/sbt/sbt package 打包成JAR
生成jar包的位置:
/home/hadoop/sparkapp/target/scala-2.10/ wordcount_2.10-1.0.jar
(7)通过 spark-submit 运行程序
最后将生成的 jar 包通过 spark-submit 提交到 Spark 中运行了,命令如下:
sbin/spark-submit --master spark://hadoop1:7077 --class "WordCount" --executor-memory 512m ~/sparkapp/target/scala-2.10/wordcount_2.10-1.0.jar 200