前一篇博客总结了如何在Windows 7上利用Vmware Workstation搭建Ubuntu kylin 14.04的hadoop集群。Hadoop集群搭建成功,距离Spark集群就只有一步之遥了。因为Spark框架本身就可以建立在Hadoop的hdfs基础之上。
搭建Spark集群,首先要安装Scala,因为Spark本身就是使用Scala语言开发的。不同的Spark 包,使用的Scala语言版本可能有所差异。而同一个Spark版本,可能因为打包时基于的hadoop版本不同,而又有不同的版本,例如在Spark的Apache官网上,当选择Spark 1.6.3版本时,打包的Hadoop版本有2.3,2.4和2.6三个:
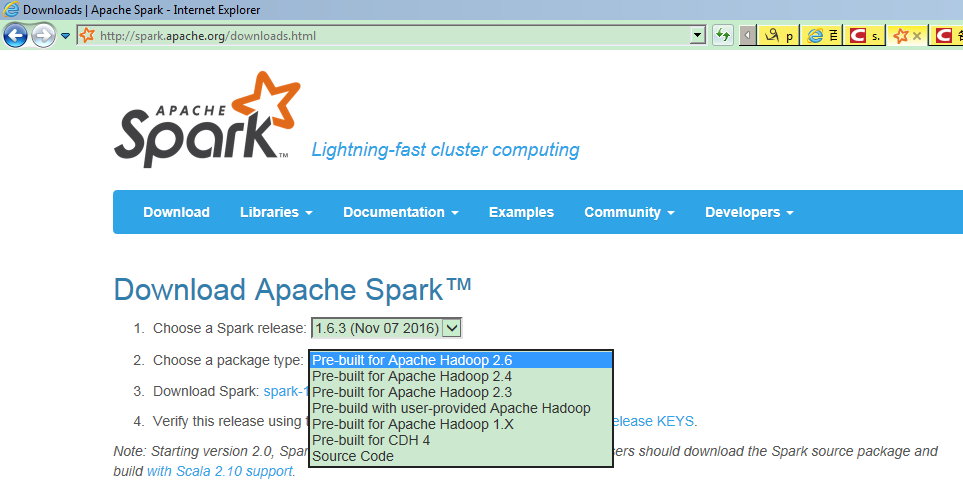
选择最新的Spark2.2版本,使用的Hadoop版本有2.7及以后和2.6两种:
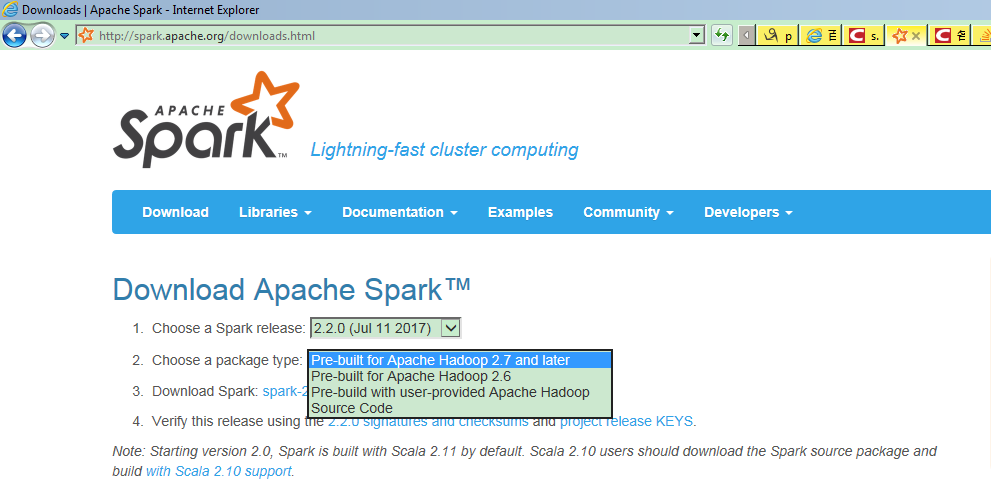
所以前面搭建hadoop集群时,选择的hadoop版本是2.7.4,而不是其它更新的版本,就是为了与这个Spark的package中的hadoop版本相兼容。
同样,不同Spark版本使用的Scala语言版本有有所差异,可以在Spark package下载后从其jars目录中包含的scala的相关包的版本看出来,也可以根据Spark官网的指示,如上图所说,从Spark 2.0开始,Spark is built with Scala 2.11 by default:
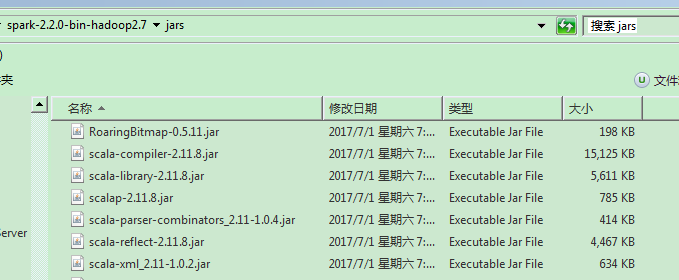
所以,选择安装的Scala版本为2.11.11。
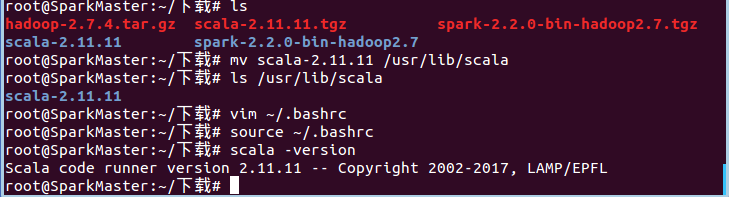
首先,在SparkMaster完成Scala语言的安装。下载Scala-2.11.11.tgz,解压后部署到/usr/lib/scala目录,并修改~/.bashrc配置文件,添加SCALA_HOME变量,并把${SCALA_HOME}/bin加入到PATH中。安装完成之后,命令终端输入scala -version,应正确显示scala的版本:
接下来安装Spark,下载Spark-2.2.0-bin-hadoop2.7.tgz,解压后部署安装到/usr/local/scala目录,并修改~/.bashrc配置文件,增加SPARK_HOME环境变量,并把
${SPARK_HOME}/bin加入到PATH中。然后配置Spark,进入 ${SPARK_HOME}/conf 目录:
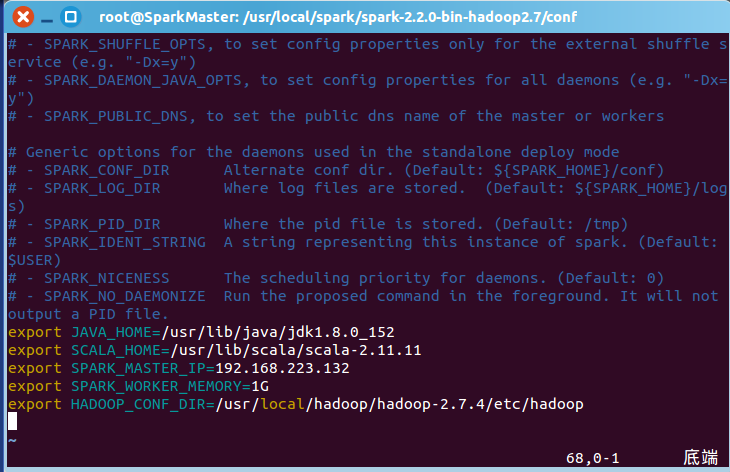
修改spark-env.sh.template,加入JAVA_HOME,SPARK_HOME,SPARK_MASTER_IP,SPARK_WORKER_MEMORY和HADOOP_CONF_DIR五个环境变量,另存为spark-env.sh:
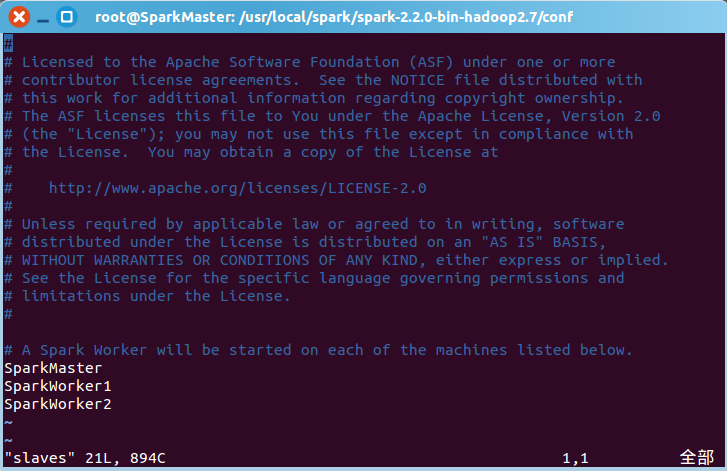
然后修改slaves.template,加入SparkMaster,SparkWorker1和SparkWorker2,配置集群总共有三个worker节点,另存为slaves:
SparkMaster配置完成后,可以用scp命令把Scala和Spark的安装部署文件直接传输到SparkWorker1和SparkWorker2:
scp -r /usr/lib/scala root@SparkWorker1:/usr/lib/scala
scp -r /usr/local/spark root@SparkWorker2:/usr/local/spark
传输完成后,登录SparkWorker1检查,Scala和Spark文件夹都已成功复制过去:
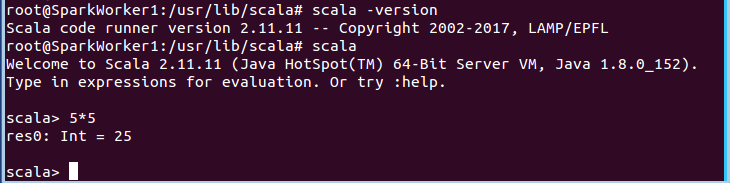
同样修改SparkWorker1的配置文件~/.bashrc,增加环境变量及修改PATH,然后命令行输入scala -version,验证Scala 版本,输入Scala,进入scala REPL,输入5*5,检查Scala及Spark复制安装正确:
同样可以用scp命令从SparkMaster复制Scala和Spark的安装部署到SparkWorker2,并修改配置文件,验证Scala及Spark安装配置正确。
接下来就可以启动Spark集群了。首先要启动Hadoop集群。到${HADOOP_HOME}/sbin目录下,,/start-all.sh即可启动Hadoop集群。
hadoop集群启动完成后,在SparkMaster上,jps可以查看到启动的进程,有NameNode和DataNode:

而在SparkWorker1和SparkWorker2上,则只有DataNode的进程:

Hadoop集群成功启动后,转到${SPARK_HOME}/sbin目录,执行./start-all.sh,启动Spark集群。启动成功后,在SparkMaster上,会多了一个Worker进程:
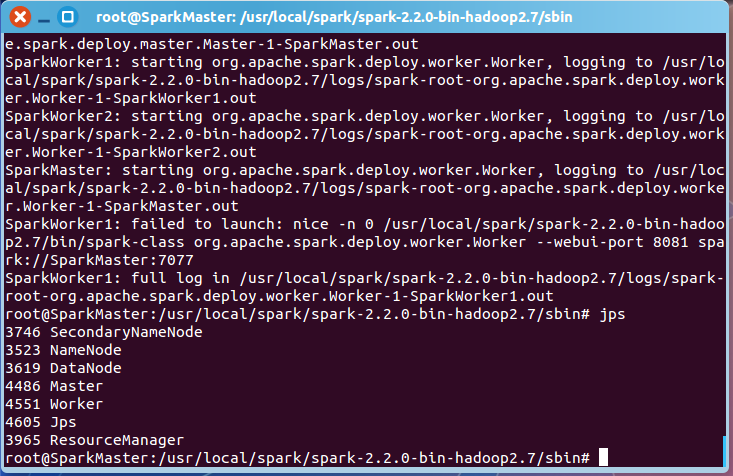
同样,在SparkWorker1和SparkWorker2上,也出现了Spark的Worker进程,表明Spark集群启动成功:

也可以到Spark集群的Web界面去查看相应的Spark集群信息,网址为http://SparkMaster:8080:
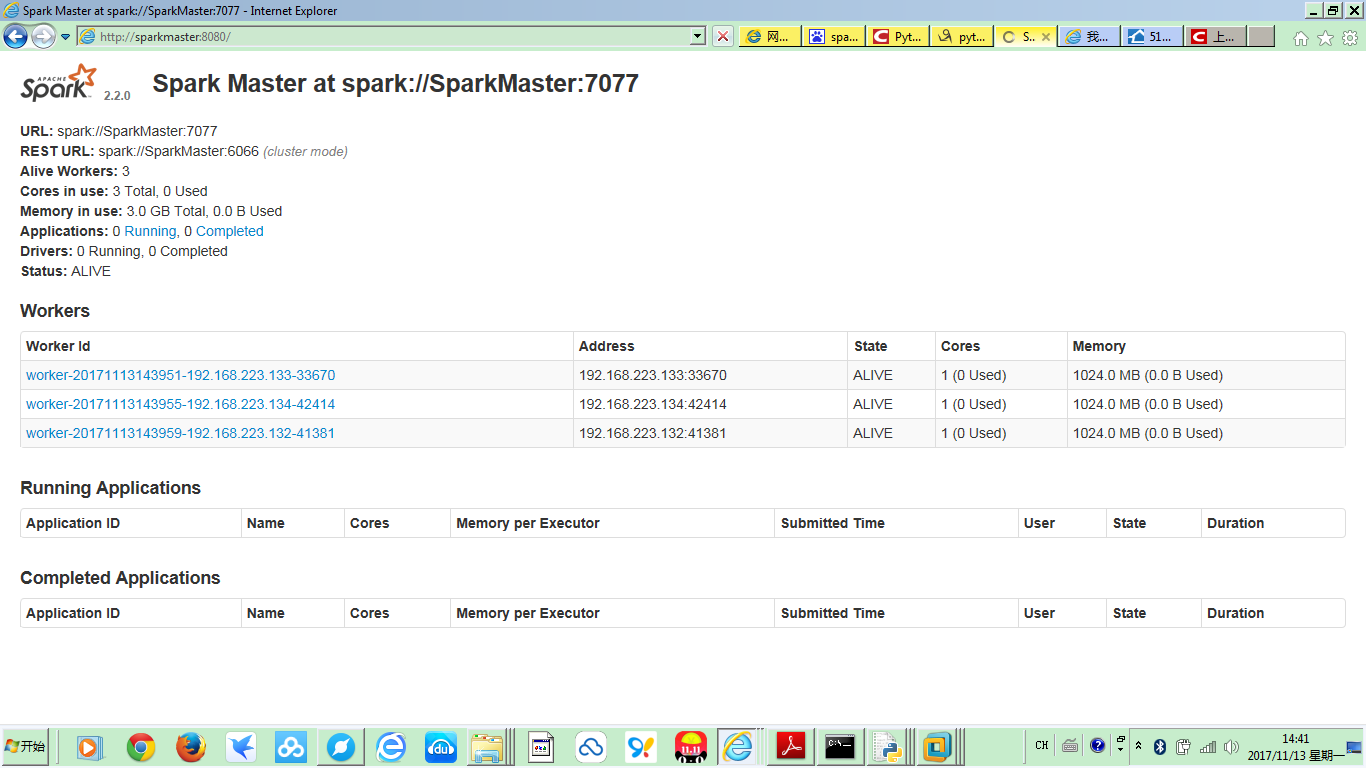
可以看到,Spark集群成功启动,共有三个Worker。
还可以在SparkMaster上启动Spark Shell,转到${SPARK_HOME}/bin,执行spark-shell:
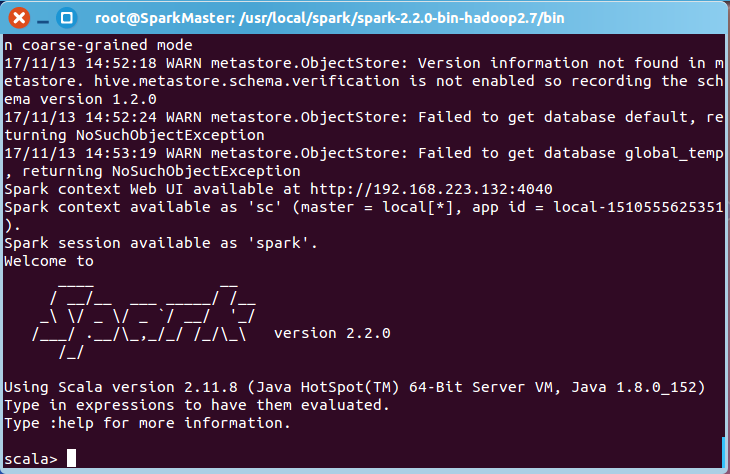
这时可以从Spark Shell的Web UI中获取更多Spark Job和Spark Environment的信息,访问地址为:http://SparkMaster:4040:

