Hadoop
问题1:
Hadoop Slave节点 NodeManager 无法启动
解决方法:
yarn-site.xml
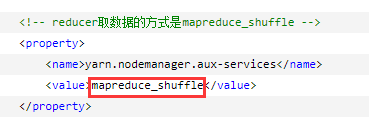
reducer取数据的方式是mapreduce_shuffle
问题2:
启动hadoop,报错Error JAVA_HOME is not set and could not be found
解决方法:
因为JAVA_HOME环境没配置正确,还有一种情况是即使各结点都正确地配置了JAVA_HOME,但在集群环境下还是报该错误。
解决方法是 在 hadoop-env.sh中 显示地重新声明一遍JAVA_HOME。
问题3:
hadoop 执行start-dfs.sh后,datenode没有启动
解决方法:
上网查了下,有些文章说的解决办法是删掉数据文件,格式化,重启集群,但这办法实在太暴力,根本无法在生产环境实施,所以还是参考另一类文章的解决办法,修改clusterID:
step1:
查看hdfs-site.xml,找到存namenode元数据和datanode元数据的路径:
step2:
打开namenode路径下的current/VERSION文件
打开datanode路径下的current/VERSION文件
step3:
将data节点的 clusterID 修改成和 name 节点的 clusterID 一致,重启集群即可。
Spark
问题1:
Spark 集群启动后,Slave节点 Worker 进程一段时间后自动结束
解决方法:
修改各节点 /etc/hostname 文件中的主机名:
与 /etc/sysconfig/network 中的主机名保持一致。

重启机器。
问题2:
Spark只启动了Master,Worker没启动
解决方法:
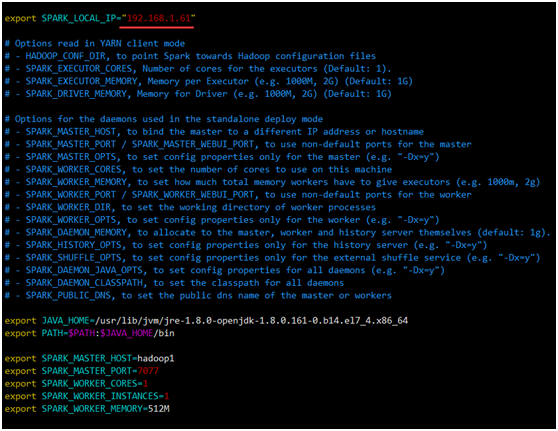
各节点 /home/hadoop/spark-2.2.1/conf/ spark-env.sh 中的 SPARK_LOCAL_IP 改为该节点自己的 IP。
问题3:
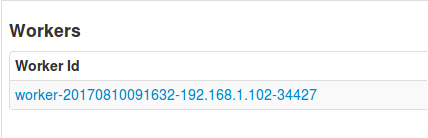
Spark集群启动后,Slave节点上有Worker进程,但打开webui,Workers列表却只显示有Master节点
解决方法:
关闭机器的防火墙
CentOS 7 默认采用新防火墙firewall,不再用iptables(service iptables status 查看防火墙状态 ,chkconfig iptables off 关闭防火墙)
systemctl stop firewalld.service #停止firewall systemctl disable firewalld.service #禁止firewall开机启动 firewall-cmd --state #查看默认防火墙状态(关闭后显示notrunning,开启后显示running)
问题4:
Spark shell退出操作以及出现问题的解决方法
解决方法:
退出的正确操作是:
:quit