本集群总共有三台主机,一台master,两台slave
-
Hadoop有一个节点无法启动
在按照教程子雨大数据之Spark入门教程(Python版)搭建Hadoop集群时,运行jps命令,发现master和其中一个slave能正常工作,运行./bin/yarn node -list发现只有一个alive节点
再次申明:本文只是针对搭建集群中有一个节点无法启动,而不是所有的节点
进一步观察,发现运行jps命令后,未启动节点的nodemanager不能正常启动
根据网上相关的建议在datanode上查看log文件(文件会在启动Hadoop集群时显示其所在目录),发现datanode连接不到主机,进一步查看其连接的主机IP地址,发现同伴将主机IP地址写错了\吐血
将host文件主机的IP地址改正后,重启即可正常运行
-
Incompatible clusterIDs in /usr/local/hadoop/tmp/dfs/data
这个错误出现了两次
第一次是同伴在第一次运行hadoop时,根据上述教程运行了bin/hdfs namenode -format这个命令
还有一次是另一个同伴将从节点关机重启后,master的clusterID就和slaves的不一样了。
解决方式有两种:
第一种:把配置文件hdfs.site.xml中dfs.datanode.data.dir在本地系统的路径下的current/VERSION(一般$HADOOP/tmp/dfs/data/current文件夹下)中的clusterID改为与namenode一样。重启即可!
第二种:重装一遍hadoop集群,删除tmp和log文件夹后重新向slaves节点发送一遍hadoop文件夹
注意:这会删除HDFS中原有的所有数据,慎重使用
-
Exception: Python in worker has different version 3.4 than that in driver 3.5, PySpark cannot run with different minor versions.Please check environment variables PYSPARK_PYTHON and PYSPARK_DRIVER_PYTHON are correctly set
问题原因:如上图所示,spark会在每个worker节点上运行python程序,所以要保证每个worker节点上python版本一致
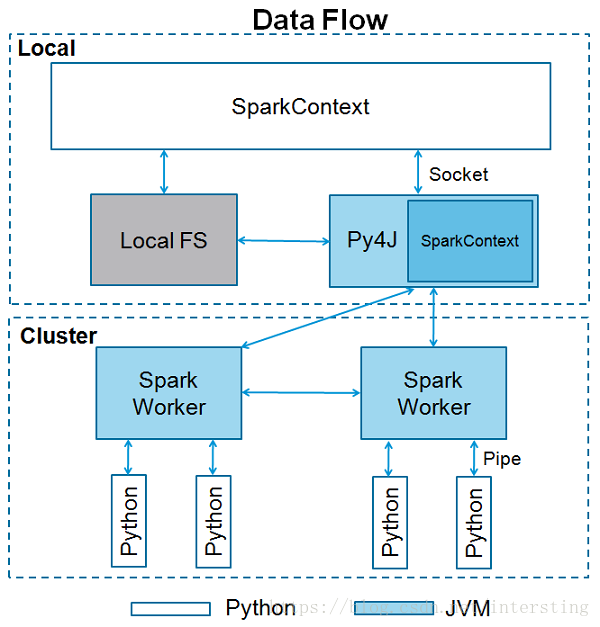
解决方式:
import os
os.environ["PYSPARK_PYTHON"] = /usr/bin/python3.5
-
there appears to be a gap in the edit log. we expected txitd 1, but got txid 2070
根据网上经验来看,最后那串数字有很多种,但是感觉应该都能用同一种方法
原因:namenode元数据被破坏,需要修复
恢复一下namenode
hadoop namenode –recover 先选择Y,再选择c,然后再重启一遍hadoop