目录标题
虚拟机:Centos 7 64位
三个节点:server1、server2、server3
由于最近老是要重复搭建环境,所以我决定这个搭建完做一个克隆
在搭建完java环境,SSH免密之后分别做一个克隆,叫做server1、server2、server3。
然后这次开始我也不创建新用户了,直接在root上执行操作
Hadoop集群的搭建不会讲的特别详细,因为我只是想要做个克隆才重新搭建
详见我的博客:Hadoop集群搭建(超详细)(伪分布式配置)
网络配置
-
修改网络配置文件
vi /etc/sysconfig/network-scripts/ifcfg-ens33 如果在输入上述命令后出现空白,请Esc :q!退出后检查命令有没有输错 BOOTPROTO=static ONBOOT=yes IPADDR=192.168.100.31 //IP地址 server1:31、server2:32、server3:33 NETMASK=255.255.255.0 //子网掩码 GATEWAY=192.168.100.2 //网关 DNS1=8.8.8.8 Esc :x -
重启网络
systemctl restart network
测试网络
ping www.baidu.com
ping 192.168.100.31 //IP地址
ping 192.168.100.2 //网关
修改主机名 & 主机映射
-
修改主机名
hostnamectl set-hostname server1 //server2、server3 reboot //重启 -
主机映射
vi /etc/hosts 192.168.100.31 server1 192.168.100.32 server2 192.168.100.33 server3 -
测试
ping server2 或:ping 192.168.100.32 ping server1 ping server3
关闭防火墙
二选一都可以关闭防火墙,建议第二种。
iptables -F //顺序不能颠倒,不然防火墙就是你以为关了但其实没关,怎么debug也没用
iptables -X
iptables -Z
iptables -L
iptables-save
setenforce 0
vi /etc/selinux/config
SELINUX=Enfocing--->SELINUX=disabled
systemctl stop firewalld.service //停止firewall
systemctl disable firewalld.service //禁止firewall开机启动
挂载–更换yum源–安装vim,gcc
-
本地安装仓库,挂载(本地仓库可以不建立,后续的EPEL也是一个仓库)
mkdir /root/bak mv /etc/yum.repos.d/*.repo /root/bak mkdir /mnt/cd mount /dev/cdrom /mnt/cd vi /etc/yum.repos.d/local.repo [centos7] name=centos7 baseurl=file:///mnt/cd gpgcheck=0 enabled=1挂载成功:

-
下载安装相应的插件
yum clean all //yum会把下载的软件包和header存储在cache中,而不自动删除。这个命令可全部清除 yum repolist //查看所拥有的仓库 yum install wget yum install vim //方便之后对各种文件的编辑 yum install gcc //C语言 yum install lrzsz //这个就是rz命令,用于上传外部文件 -
换源
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup //备份 下载新的CentOS-Base.repo 到/etc/yum.repos.d/(二选一) wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo //这个在我机子下载不了 curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo //推荐用这个 wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo //添加EPEL yum clean all yum makecache //清理缓存并生成新的缓存换源成功!换成国内的源后续的下载安装的速度会更快

安装Java环境
-
下载安装jdk(注意:版本要在1.8以上)
yum install java-1.8.0-openjdk java-1.8.0-openjdk-devel -
查看安装位置(除去路径末尾的 “/bin/javac”,剩下的就是正确的路径了)
rpm -ql java-1.8.0-openjdk-devel | grep '/bin/javac' -
配置环境变量
vi ~/.bashrc export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.242.b08-0.el7_7.x86_64 export CLASSPATH=${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar export PATH=${PATH}:${JAVA_HOME}/bin source ~/.bashrc //配置生效 -
检查一下是否正确
echo $JAVA_HOME # 检验变量值 java -version $JAVA_HOME/bin/java -version # 与直接执行 java -version 一样
SSH无密码登录节点配置
-
一般默认安装SSH,先检验。
rpm -qa | grep ssh 包含了 SSH client 跟 SSH server,则不需要再安装。 否则需要安装: sudo yum install openssh-clients sudo yum install openssh-server -
测试SSH是否可用
ssh localhost 记得exit

-
server1上执行
cd ~/.ssh # 如果没有该目录,先执行一次ssh localhost rm ./id_rsa* # 删除之前生成的公匙(如果有执行,没有也可执行一次,以防万一) ssh-keygen -t rsa # 一直按回车就可以 cat ./id_rsa.pub >> ./authorized_keys //让master节点能无密码SSH登录 chmod 600 ./authorized_keys #修改文件权限为只读,此操作必须执行不然不能成功 ssh localhost //尝试是否无密码SSH登录本机 exit -
server2节点
ssh localhost exit cd ~/.ssh # 如果没有该目录,先执行一次ssh localhost rm ./id_rsa* # 删除之前生成的公匙(如果有执行,没有也可执行一次,以防万一) ssh-keygen -t rsa # 一直按回车就可以 -
server3节点
ssh localhost exit cd ~/.ssh # 如果没有该目录,先执行一次ssh localhost rm ./id_rsa* # 删除之前生成的公匙(如果有执行,没有也可执行一次,以防万一) ssh-keygen -t rsa # 一直按回车就可以 -
然后回到server1节点上
vi ./authorized_keys -
server2、server3节点
cat ./id_rsa.pub -
将server2,server3里的内容手动复制到server1的./authorized_keys 中,保存Esc :x
server1节点:
将server1节点上的authoized_keys远程传输到server2和server3的~/.ssh/目录下
scp ~/.ssh/authorized_keys root@server2:~/.ssh/ #在线复制给server2 scp ~/.ssh/authorized_keys root@server3:~/.ssh/ #在线复制给server3server2,3节点
ls ~/.ssh //查看是否已复制 chmod 600 ./authorized_keys #修改文件权限为只读,此操作必须执行不然不能成功SSH免密码登录就搞定了!
测试一下:
ssh server1 exit
ssh server2 exit
ssh server3 exit
可以在这里进行server1,server2,server3的克隆
先创建快照:
关闭Linux,右键创建快照:快照名称:server1 /server2 /server3
之后需要克隆:右键管理–克隆–选择相应的快照–创建完整克隆–填写名称位置
安装hadoop-2.7.7(先在server1上执行就可以了)
-
通过命令rz将hadoop-2.7.7的安装包放进去
rz -
解压缩
sudo tar -zxf hadoop-2.7.7.tar.gz -C /home/ //注意对应自己hadoop压缩包所在的位置 cd /home/ sudo chown -R root hadoop-2.7.7 # 修改文件权限 -
检查是否安装成功
cd /home/hadoop-2.7.7 ./bin/hadoop version -
配置PATH环境
vi ~/.bashrc 加入这一行,根据自己的路径 export PATH=$PATH:/home/hadoop-2.7.7/bin:/home/hadoop2.7.7/sbin source ~/.bashrc #使配置生效 hadoop version
配置hadoop集群环境(先在server1上执行就可以了)
先进入到相应的路径
cd /home/hadoop-2.7.7/etc/hadoop
-
文件Slaves
vi slaves 删除localhost 添加: server2 server3 -
文件 core-site.xml 改为下面的配置:
vi core-site.xml <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://192.168.100.31:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/home/hadoop-2.7.7/tmp</value> <description>Abase for other temporary directories.</description> </property> </configuration> -
文件 hdfs-site.xml,dfs.replication 一般设为 3,如果只有一个 slave 节点,则 dfs.replication 的值设为 1:
vi hdfs-site.xml <configuration> <property> <name>dfs.namenode.secondary.http-address</name> <value>192.168.100.31:50090</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/home/hadoop-2.7.7/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/home/hadoop-2.7.7/tmp/dfs/data</value> </property> </configuration> -
文件 mapred-site.xml (默认文件名为 mapred-site.xml.template),然后配置修改如下:
vi mapred-site.xml.template <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>192.168.100.31:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>192.168.100.31:19888</value> </property> </configuration> -
文件 yarn-site.xml:
vi yarn-site.xml <configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>192.168.100.31</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration> -
将配置好的hadoop复制到各节点
server1节点:
cd /home/ sudo rm -r ./hadoop-2.7.7/tmp # 删除 Hadoop 临时文件 sudo rm -r ./hadoop-2.7.7/logs/* # 删除日志文件 tar -zcf ~/hadoop-2.7.7.master.tar.gz ./hadoop-2.7.7 # 先压缩再复制 cd ~ //显示没有权限就在前面加一个sudo scp ./hadoop-2.7.7.master.tar.gz server2:/home/ scp ./hadoop-2.7.7.master.tar.gz server3:/home/server2、3节点:
sudo tar -zxf hadoop-2.7.7.master.tar.gz -C /home/ sudo chown -R root /home/hadoop-2.7.7 vi ~/.bashrc 加入这一行,根据自己的路径 export PATH=$PATH:/home/hadoop-2.7.7/bin:/usr/local/hadoop2.7.7/sbin source ~/.bashrc #使配置生效 -
首次运行需要实例化
cd /home/hadoop-2.7.7/ ./bin/hdfs namenode -format # 首次运行需要执行初始化,之后不需要 开启集群:./sbin/start-all.sh
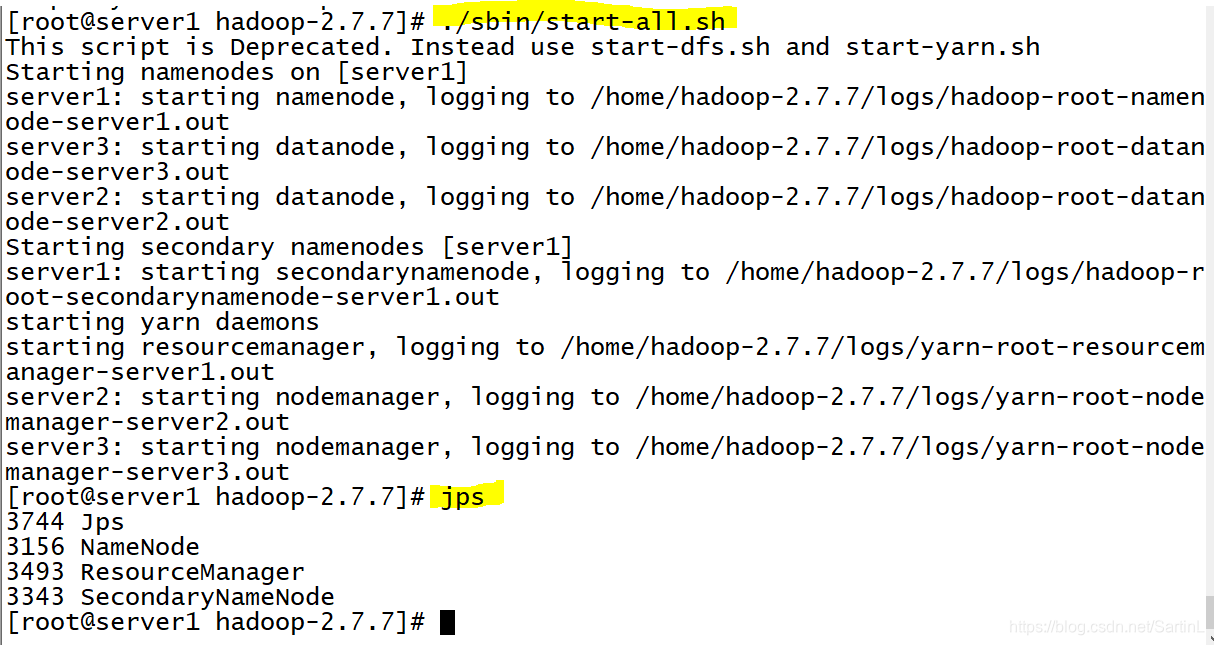
如果是在hadoop集群下去搭建基于zookeeper的Spark环境的话,我建议在使用zookeeper和spark前可以先开启hadoop集群环境
原因我在后面涉及到时会提到
安装下载zookeeper并配置环境(三台机子都要执行)
-
下载zookeeper,用过清华大学的开源网站下载
https://mirrors.huaweicloud.com/ 华为的开源网
https://mirrors.tuna.tsinghua.edu.cn/ 清华的开源网
wget https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/zookeeper-3.6.0/apache-zookeeper-3.6.0-bin.tar.gz //我的不管用,所以用下面那个 curl -o /home/apache-zookeeper-3.6.0-bin.tar.gz https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/zookeeper-3.6.0/apache-zookeeper-3.6.0-bin.tar.gz 复制给server2,server3 scp ./apache-zookeeper-3.6.0-bin.tar.gz server2:/home/ scp ./apache-zookeeper-3.6.0-bin.tar.gz server3:/home/ -
解压并配置文件(三个机子都要执行)
tar xzvf apache-zookeeper-3.6.0-bin.tar.gz 赋予权限 sudo chown -R root /home/apache-zookeeper-3.6.0-bin 配置文件 cd /home/apache-zookeeper-3.6.0-bin/conf cp zoo_sample.cfg zoo.cfg vi zoo.cfg dataDir=/home/apache-zookeeper-3.6.0-bin/data dataLogDir=/home/apache-zookeeper-3.6.0-bin/logs 在clientPort=2181下添加 # server.1 这个1是服务器的标识,可以是任意有效数字,标识这是第几个服务器节点,这个标识要写到dataDir目录下面myid文件里 # 指名集群间通讯端口和选举端口 server.1=server1:2888:3888 server.2=server2:2888:3888 server.3=server3:2888:3888 -
创建两个文件(三个机子都要执行)
cd /home/apache-zookeeper-3.6.0-bin mkdir data mkdir logs -
在三台机子上分别配置id
cd /home/apache-zookeeper-3.6.0-bin server1: echo "1" > data/myid server2: echo "2" > data/myid server3: echo "3" > data/myid 检查一下 cd /home/apache-zookeeper-3.6.0-bin/data cat myid -
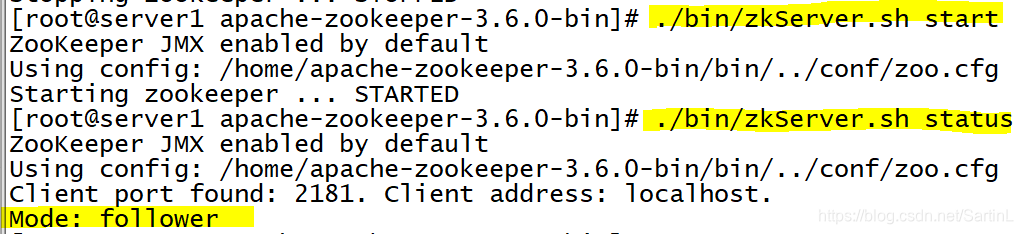
启动zookeeper(同样三台机子都要启动)
cd /home/apache-zookeeper-3.6.0-bin ./bin/zkServer.sh start 查看是否启动成功(机子的状态) ./bin/zkServer.sh status 查看的同时可以看到该机子是leader还是followerserver1
server2

server3
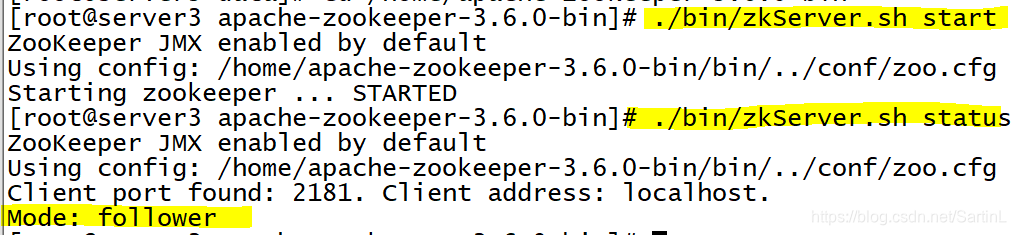
-
可以正常启动后我们可以尝试一下转换leader
zookeeper采用的是投票机制,在你关闭当前leader的机子时它会自动去找另一个机子作为leader
先关闭当前leader的机子(根据自己的机子情况,他不是按顺序选择leader的,它是随机的)
./bin/zkServer.sh stop
./bin/zkServer.sh start
查看状态
./bin/zkServer.sh status
然后再去查看其他两台机子的状态
./bin/zkServer.sh status
然后你可以发现leader又在这两台机子间
例如:我把原本是leader的server2关掉之后,server3就变成了leader

zookeeper的环境搭建好之后就开始搭建Spark
安装Spark
-
从官网上下载相应的压缩包
官网:spark.apache.org
或者直接用清华的开源网站去下载
看网速吧,有时候先从网站上下载会比较慢,当然你可以用迅雷,不过我还是比较喜欢用wget直接去下载开源网站上的,个人觉得比较快
curl -o /home/spark-2.4.5-bin-hadoop2.7-tgz https://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-2.4.5/spark-2.4.5-bin-hadoop2.7.tgz -
rz上传后解压缩
cd /home/ sudo tar -zxf spark-2.4.5-bin-hadoop2.7.tgz //注意对应自己spark压缩包所在的位置 sudo chown -R root ./spark-2.4.5-bin-hadoop2.7 vi ~/.bashrc 记得修改位置 #spark export SPARK_HOME=/home/spark-2.4.5-bin-hadoop2.7 export PATH=$PATH:$SPARK_HOME/bin source ~/.bashrc -
然后通过ls就可以查看里面相应的文件了
-
cd进入到conf文件夹下修改两个配置文件
cd /home/spark-2.4.5-bin-hadoop2.7/conf cp spark-env.sh.template spark-env.sh //拷贝 //然后打开 vi spark-env.sh //里面的配置可以自己去了解 //在末尾加入 因为是基于zookeeper的,配置如下:(以上的配置是不基于zookeeper,单独基于hadoop) # 配置JDK安装位置 # JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.242.b08-0.el7_7.x86_64 # 配置hadoop配置文件的位置 # HADOOP_CONF_DIR= # 配置zookeeper地址 export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.242.b08-0.el7_7.x86_64 export HADOOP_INSTALL=/home/hadoop-2.7.7 export HADOOP_CONF_DIR=$HADOOP_INSTALL/etc/hadoop SPARK_LOCAL_DIRS=/home/spark-2.4.5-bin-hadoop2.7 //也可以只填下面这两个 SPARK_WORKER_CORES="1" SPARK_DAEMON_JAVA_OPTS=" -Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=server1:2181,server2:2181,server3:2181 -Dspark.deploy.zookeeper.dir=/spark"cp slaves.template slaves //设置Worker节点 vi slaves //输入 server1 server2 server3然后传给server2、server3server1 若显示没有权限就在前面加一个sudo scp spark-2.4.5-bin-hadoop2.7.tgz server2:/home/ scp spark-2.4.5-bin-hadoop2.7.tgz server3:/home/ 然后在server2、server3上重复上述操作server2,server3节点上sudo chown -R root /home/spark-2.4.5-bin-hadoop2.7 vi ~/.bashrc 加入这一行,根据自己的路径 export SPARK_HOME=/home/spark-2.4.5-bin-hadoop2.7 export PATH=$PATH:$SPARK_HOME/bin source ~/.bashrc #使配置生效 .......看上面操作
启动Spark
-
进入到Spark目录下
//启动Spark集群前要先启动Hadoop集群(只要在server1) cd /home/hadoop-2.7.7 ./sbin/start-all.sh ./sbin/start-dfs.sh 启动zookeeper(三个机子都要启动) cd /home/apache-zookeeper-3.6.0-bin ./bin/zkServer.sh start //再启动Spark集群(只要在server1启动) cd /home/spark-2.4.5-bin-hadoop2.7 ./sbin/start-all.sh //基本和hadoop是一样的 或是分开启动:(上面开启了,这里就不执行,二选一) ./sbin/start-master.sh ./sbin/start-slaves.sh 要实现高可用,同时还要在server2和server3上的spark目录下启动master cd /home/spark-2.4.5-bin-hadoop2.7 ./sbin/start-master.sh都开启之吼,查看jps
server1
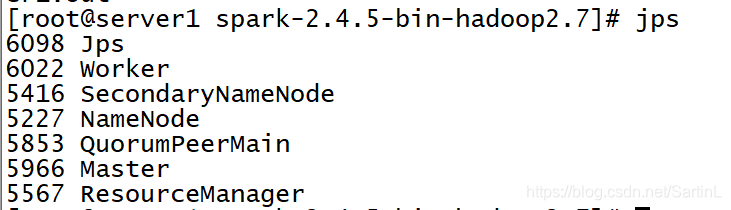
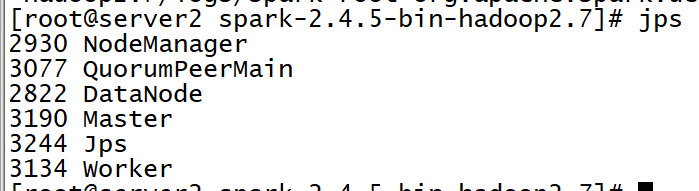
server2
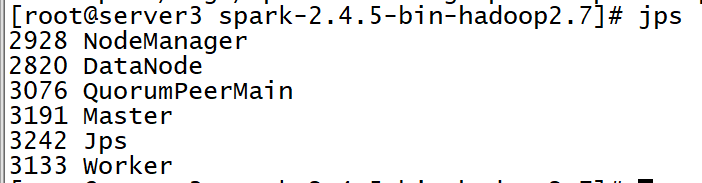
server3
-
可以查看运行了几个JAVA
ps aux|grep java
运行案例
不同于单独的spark运行案例,基于zookeeper的spark运行需要把三个机子都写上
为了防止其中一台机子停了可以去找其他机子运行
在spark目录下
cd /home/spark-2.4.5-bin-hadoop2.7
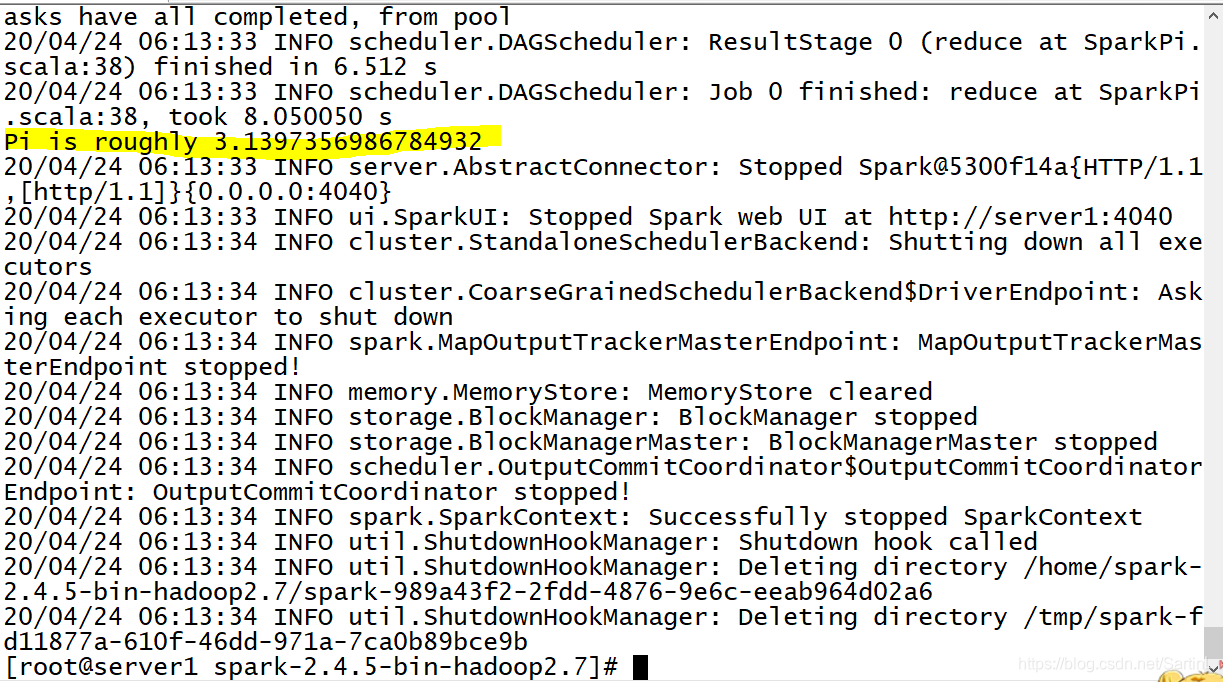
./bin/run-example --master spark://server1:7077,server2:7077,server3:7077 SparkPi(Spark例子的名称)
运行结果:
在Shell里使用scala
例子
在根目录下创建一个helloworld.txt的文件
并填入10行左右的英文内容(可上网随机找一篇英文文章,自己分一下行)
vim helloworld.txt
Hooray! It's snowing! It's time to make a snowman.James runs out.
He makes a big pile of snow. He puts a big snowball on top.
He adds a scarf and a hat. He adds an orange for the nose.
He adds coal for the eyes and buttons.In the evening, James opens the door.
What does he see? The snowman is moving! James invites him in.
The snowman has never been inside a house. He says hello to the cat.
He plays with paper towels.A moment later, the snowman takes James's hand and goes out.
They go up, up, up into the air! They are flying! What a wonderful night!
The next morning, James jumps out of bed.
He runs to the door.He wants to thank the snowman. But he's gone.
保存后拷贝到另外两台机子上
scp helloworld.txt server2:~/
scp helloworld.txt server3:~/
那以后是不是每次有文件都需要拷贝呢?
这里就涉及到了我建议基于hadoop集群环境的原因:
hadoop可以在master工作,但是其他节点同样一起工作
拷贝完之后进去到shell进行操作(在server1进入即可)
进入到spark目录下
cd /home/spark-2.4.5-bin-hadoop2.7
./bin/spark-shell --master spark://server1:7077,server2:7077,server3:7077
然后就进入到了scala的操作环境(同时可以通过网页去访问到我们的工作进程)
var textfile = sc.textFile("file:///root/helloworld.txt")
统计行数
textfile.count()
得到第一行的内容
textFile.first()
查找某一个字符串并统计所在行数
var myrdd = textfile.filter(line => line.contains("He"))
myrdd.count()
var myrdd = textfile.filter(line => line.contains("**")) **填内容
myrdd.count()
统计每个单词出现的次数,通过空格来分割出每一个单词
textfile.flatMap(line=>line.split(" ")).map(word=>(word,1)).reduceByKey(_+_)
要定义
val count = textfile.flatMap(line=>line.split(" ")).map(word=>(word,1)).reduceByKey(_+_)
统计
count.collect()
退出shell
:quit
运行结果:
scala> var textfile = sc.textFile("file:///root/helloworld.txt")
textfile: org.apache.spark.rdd.RDD[String] = file:///root/helloworld.txt MapPartitionsRDD[1] at textFile at <console>:24
scala> textfile.count()
res0: Long = 10
scala> textfile.first()
res1: String = "Hooray! It's snowing! It's time to make a snowman.James runs out. "
scala> var myrdd = textfile.filter(line => line.contains("He"))
myrdd: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[2] at filter at <console>:25
scala> myrdd.count()
res2: Long = 6
scala> val count = textfile.flatMap(line=>line.split(" ")).map(word=>(word,1)).reduceByKey(_+_)
count: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[4] at reduceByKey at <console>:25
关闭集群
./bin/zkServer.sh stop(记得三个机子)
./sbin/syop-master.sh (server2,server3)
./sbin/stop-all.sh //记得关闭位置是不一样
./sbin/stop-all.sh //关闭hadoop
