1.解压
root@master ~]# tar zxvf spark-2.0.2-bin-hadoop2.7.tgz
mv spark-2.0.2-bin-hadoop2.7 /opt/spark2.配置环境变量
vim .bashrc
export SPARK_HOME=/opt/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbinsource ~/.bashrc
3.spark配置
3.1配置slaves
[root@master ~]# cd /opt/spark/
root@master spark]# cp ./conf/slaves.template ./conf/slaves
vi ./conf/slaves
slave
3.2配置spark-env.sh
cp ./conf/spark-env.sh.template ./conf/spark-env.sh添加
export SPARK_DIST_CLASSPATH=$(/opt/hadoop/hadoop-2.9.0/bin/hadoop classpath)
export HADOOP_CONF_DIR=/opt/hadoop/hadoop-2.9.0/etc/hadoop
export SPARK_MASTER_IP=192.168.61.1653.3分发
scp -rp /opt/spark/* slave:/opt/spark/4.启动Spark集群
[root@master ~]# /opt/spark/sbin/start-master.sh
starting org.apache.spark.deploy.master.Master, logging to /opt/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-master.out
[root@master ~]# jps
21636 ResourceManager
21398 SecondaryNameNode
22955 Master
23086 Jps
15663 DecryptStart
21135 NameNode起slaves时报错
[root@master ~]# /opt/spark/sbin/start-slaves.sh
slave: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-slave.out
slave: failed to launch org.apache.spark.deploy.worker.Worker:
slave: JAVA_HOME is not set
slave: full log in /opt/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-slave.outspark-env.sh里添加JAVA_HOME
root@slave ~]# vi /opt/spark/conf/spark-env.sh
export JAVA_HOME=/opt/java/jdk1.8.0_171source后重新启动
[root@slave ~]# jps
49078 DataNode
49242 NodeManager
50826 Jps
50686 Worker5.查看集群状态
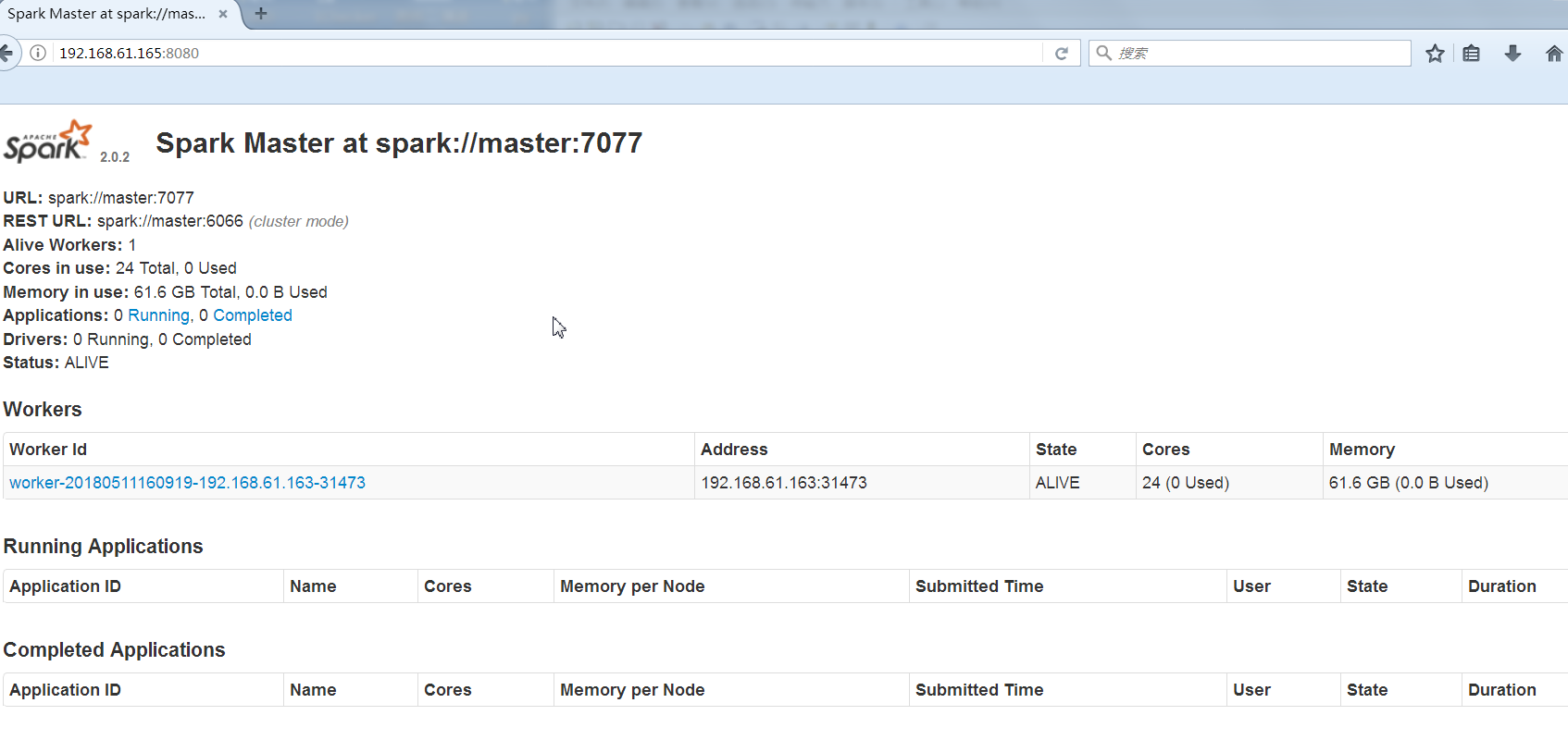
spark集群的web页面:http://192.168.61.165:8080/
wordcount
[root@master ~]# spark-shell
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel).
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/spark/jars/slf4j-log4j12-1.7.16.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hadoop/hadoop-2.9.0/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
18/05/11 16:17:09 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
18/05/11 16:17:11 WARN spark.SparkContext: Use an existing SparkContext, some configuration may not take effect.
Spark context Web UI available at http://192.168.61.165:4040
Spark context available as 'sc' (master = local[*], app id = local-1526026631170).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.0.2
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_171)
Type in expressions to have them evaluated.
Type :help for more information.
scala> val f=sc.textFile("hdfs://master:9000/input/hadoop-env.sh")
f: org.apache.spark.rdd.RDD[String] = hdfs://master:9000/input/hadoop-env.sh MapPartitionsRDD[1] at textFile at <console>:24
scala> val c=f.flatMap(line => line.split(" ")).map(word => (word,1)).reduceByKey(_+_)
c: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[4] at reduceByKey at <console>:26
scala> c.collect
res2: Array[(String, Int)] = Array((HADOOP_SECURE_DN_PID_DIR=${HADOOP_PID_DIR},1), (protocol,2), (Unless,1), (this,6), (starting,1), (under,4), (remote,1), (therefore,1), (HADOOP_PORTMAP_OPTS="-Xmx512m,1), (extra,1), (express,1), (Java,2), (only,2), (NOTE:,1), (This,2), (WITHOUT,1), ("AS,1), (export,20), (HADOOP_CLIENT_OPTS="-Xmx512m,1), (Jsvc,2), (IS",1), (any,1), (implementation,2), (ANY,1), (amount,1), (2.0,1), (HADOOP_JAAS_DEBUG=true,1), (file,3), (invormation,1), (ports.,2), (are,4), (-Dsun.security.spnego.debug",1), (representing,1), (licenses,1), (specified,2), (can,1), (commands,1), (when,3), (heap,2), (Apache,2), (When,1), (language,1), (HADOOP_OPTS,3), (done,1), (as,2), (potential,1), (permissions,1), (WARRANTIES,1), (there,1), (override,1), (multiple,1), ($HADOOP_SECONDARYNAM...
scala>