一 隐马尔可夫模型的基本概念
(1)隐马尔可夫模型的定义
隐马尔可夫模型是关于时序的概率模型,描述由一个隐藏的马尔可夫链随机生成不可观测的状态随机序列,再由各个状态生成一个观测而产生观测随机序列的过程。隐藏的马尔可夫链随机生成的状态的序列,称为状态序列(state sequence);每个状态生成一个观测,而由此产生的观测的随机序列,称为观测序列(observation sequence)。序列的每一个位置又可以看作是一个时刻。
隐马尔科夫链简单说来,就是把时间线看做一条链,每个节点只取决于前N个节点。
隐马尔可夫模型由初始概率分布、状态转移概率分布以及观测概率分布确定。
隐马尔可夫模型的形式定义如下:
设是所有可能的状态的集合,
是所有可能的观侧的集合,N是可能的状态数,M是可能的观测数.
,
是长度为
的状态序列,
是对应的观测序列.
,
隐马尔可夫模型由初始状态概率向量、状态转移概率矩阵
和观测概率矩阵
决定。
和
决定状态序列,
决定观测序列。隐马尔可夫模型
可以用三元符号表示,即
,
,
称为隐马尔可夫模型的三要素。
状态转移概率矩阵与初始状态概率向量
确定了隐藏的马尔可夫链,生成不可观测的状态序列。观测概率矩阵
确定了如何从状态生成观测,与状态序列综合确定了如何产生观测序列。
是状态转移概率矩阵:
其中 是在时刻
处于状态
的条件下在时刻
+1转移到状态
的概率。
是观测概率矩阵:
其中 是在时刻
处于状态
的条件下生成观测
的概率。
是初始状态概率向量:
= (
)
其中 =
是时刻
处于状态
的概率。
隐马尔可夫模型的例子:


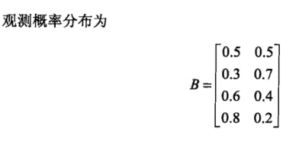
(2)观测序列的生成过程

(3)隐马尔可夫模型的3个基本问题
(1)概率计算问题。给定模型和观测序列
,计算在模型l
之下观测序列
出现的概率。
(2)学习问题。己知观测序列,估计模型参数
,使得在该模型下观测序列概率
最大。即用极大似然估计的方法估计参数。
(3)预测问题。也称为解码(decoding)问题。己知模型和观测序列,求对给定观测序列条件概率
最大的状态序列
,即给定观测序列,求最有可能的对应的状态序列。
二 概率计算算法
(1)观测序列概率的前向算法
前向概率定义:给定隐马尔可夫模型,定义到时刻
部分观测序列为
且状态为
的概率为前向概率,记作
可以递推地求得前向概率及观测序列概率
观测序列概率的前向算法:
输入:HMM的参数,观测序列
;
输出:观测序列概率.
(1)初值
(2)递推:对,
(3)终止
=
(2)观测序列概率的后向算法
后向概率定义:给定隐马尔可夫模型,定义到时刻
状态为
的条件下,从
到
的部分观测序列为
的概率为后向概率,记作
可以递推地求得前向概率及观测序列概率
观测序列概率的后向算法:
输入:HMM的参数,观测序列
;
输出:观测序列概率.
(1)初值
,
(2)递推:对,
,
(3)终止
=
(3)前向算法和后向算法实例
考虑盒子和球模型,状态集合
,观测序列
{红,白},
A = [0.5,0.2,0.3 B=[0.5,0.5
0.3,0.5,0.2 0.4,0.6
0.2,0.3,0.5] 0.7,0.3]
设T=3,O=(红,白,红),试分别用前向和后向算法计算

from numpy import *
import numpy as np
import matplotlib as plt
import math
class HMM:
def __init__(self, pi, A, B):
self.pi = pi
self.A = A
self.B = B
self.M = B.shape[1]
self.N = A.shape[0]
def forward(hmm, obs):
T = len(obs) # 观察序列长度
N = hmm.N # 隐藏层状态数
alpha = matrix(zeros((N, T))) # 前向概率
alpha[:, 0] = multiply(hmm.pi[:], hmm.B[:, observation.index(obs[0])]) # 初值
for t in range(1, T): # 递推
for n in range(0, N):
alpha[n, t] = sum(alpha[:, t - 1].T * hmm.A[:, n]) * hmm.B[n, observation.index(obs[t])]
prob = sum(alpha[:, T - 1]) # 计算观察序列概率
return prob, alpha
def backward(hmm, obs):
T = len(obs) # 观察序列长度
N = hmm.N # 隐藏层状态数
beta = matrix(zeros((N,T))) # 后向概率
beta[:,T-1] = 1
for t in reversed(range(0,T-1)):
for n in range(0,N):
beta[n,t] = sum(multiply(multiply(hmm.A[n,:].T, hmm.B[:,observation.index(obs[t+1])]), beta[:,t+1]))
prob = sum(multiply(multiply(hmm.pi, hmm.B[:,observation.index(obs[0])]), beta[:,0]))
return prob, beta
if __name__ == "__main__":
# 状态转移概率矩阵
A = matrix([[0.5,0.2,0.3],
[0.3,0.5,0.2],
[0.2,0.3,0.5]])
# 观测概率矩阵
B = matrix([[0.5,0.5],
[0.4,0.6],
[0.7,0.3]])
pi = matrix([0.2,0.4,0.4]).T
hmm = HMM(pi, A, B)
observation = ['red','write']# 所有可能的观测集合
observed = ['red','write','red']# 观测序列
prob, alpha = forward(hmm, observed)
prob, beta = backward(hmm, observed)
print('The forword probability is: \n', alpha)
print('The probability of this observed sequence is %f' % prob)
print('The forword probability is: \n', beta)
print('The probability of this observed sequence is %f' % prob)运行结果:

三 学习算法
隐马尔可夫模型的学习根据训练数据的不同分为监督学习和非监督学习。
监督学习:训练数据包括观测序列和对应的状态序列
非监督学习:训练数据仅有观测序列
(1)监督学习
假设已给训练数据包含S个长度相同的观测序列和对应的状态序列,那么可以利用极大似然估计法来估计隐马尔可夫模型的参数。
1.转移概率的估计
设样本中时刻处于状态
时刻
处于状态j的频数为
,那么状态转移概率
的估计是
2,观测概率的估计
设样本中状态为且观测为
的频数是
,那么状态为
且观测为
的概率
的估计是
3,初始状态概率的估计
为S个样本中初始状态为
的频率。
由于监督学习需要使用训练数据,而人工标注训练数据往往代价很高,所以有时会利用非监督学习的方法。
(2)非监督学习
非监督学习用的是Baum-welch算法,这个算法其实就是EM算法。
现在假设给定的训练数据只包含个长度为
的观测序列
而没有对应的状态序列,然后目标是学习隐马尔可夫模型
的参数。
我们将观测序列数据看做观测数据,状态序列数据看做不可观测的隐数据
,那么隐马尔可夫模型事实上是一个含有隐变量的概率模型
它的参数学习可以由EM算法实现.
推导:
1.确定完全数据的对数似然函数
把所有观测数据写成,所有隐数据写成
,完全数据是
。完全数据的对数似然函数是
。
2.EM算法的E步,求Q函数
其中,是隐马尔可夫模型参数的当前估计值,λ是要极大化的隐马尔可夫模型参数。
于是,函数可以写成
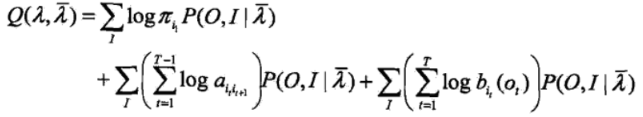
上式中的求和都是对所有训练数据的序列总长度T进行的。
3.EM算法的M步:极大化求模型参数A, B,π



4.Baum-welch模型参数的估计公式

Baum-welch算法
输入:观测数据;
输出:隐马尔可夫模型参数。
过程:


四 预测算法
维特比算法实际是用动态规划解隐马尔可夫模型预侧问题,即用动态规划(dynamic programming)求概率最大路径(最优路径)。一条路径对应着一个状态序列。
根据动态规划原理,最优路径具有这样的特性:如果最优路径在时刻t通过结点,那么这一路径从结点
到终点
的部分路径,对于从
到
的所有可能的部分路径来说,必须是最优的。依据这一原理,我们只需从时刻t=1开始,递推地计算在时刻t状态为i的各条部分路径的最大概率,直至得到时刻t=T状态为i的各条路径的最大概率。时刻t=T的最大概率即为最优路径的概率P*。
最优路径的终结点也同时得到。之后,从终结点
开始,由后向前逐步求得结点
。

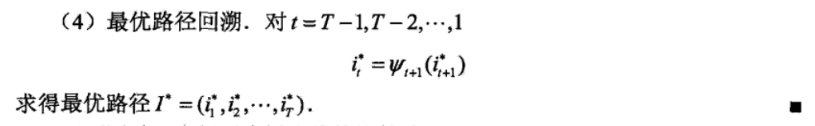
维特比算法的实例:


# -*-coding:utf-8-*-
import numpy as np
# 隐马尔可夫模型λ=(A, B, pai)
# A是状态转移概率分布,状态集合Q的大小N=np.shape(A)[0]
# 从下给定A可知:Q={盒1, 盒2, 盒3}, N=3
A1 = np.array([[0.5, 0.2, 0.3],
[0.3, 0.5, 0.2],
[0.2, 0.3, 0.5]])
# B是观测概率分布,观测集合V的大小T=np.shape(B)[1]
# 从下面给定的B可知:V={红,白},T=2
B1 = np.array([[0.5, 0.5],
[0.4, 0.6],
[0.7, 0.3]])
# pai是初始状态概率分布,初始状态个数=np.shape(pai)[0]
pi1 = np.array([[0.2],
[0.4],
[0.4]])
# 观测序列
Object1 = np.array([[0],
[1],
[0]]) # 0表示红色,1表示白,就是(红,白,红)观测序列
def sum(L):
sumValue = 0.0
for i in range(0, len(L)):
sumValue += L[i]
return sumValue
def max(L):
target = 0
maxValue = L[target]
for i in range(1, len(L)):
if (L[i] > maxValue):
target = i
maxValue = L[i]
return maxValue, target + 1
def printTable(table, type="float"):
if (type == "float"):
for i in range(0, len(table)):
for j in range(0, len(table[i])):
print ("%-16f" % (table[i][j]),)
print ("\n")
elif (type == "int"):
for i in range(0, len(table)):
for j in range(0, len(table[i])):
print ("%-2d" % (table[i][j]),)
print ("\n")
def initTable(x, y, type="float"):
table = []
if (type == "float"):
initValue = 0.0
elif (type == "int"):
initValue = 0
for i in range(0, x):
temp = []
for j in range(0, y):
temp.append(initValue)
table.append(temp)
return np.array(table)
def forwardV(A, B, pi, Object, mod="forward"):
T = len(Object)
NumState = len(A)
NodeTable = initTable(NumState, T)
if (mod == "viterbi"):
NodePath = initTable(NumState, T, type="int")
for i in range(0, NumState):
NodeTable[i][0] = pi[i] * B[i][Object[0]]
for t in range(1, T):
for j in range(0, NumState):
temp = []
for i in range(0, NumState):
temp.append(NodeTable[i][t - 1] * A[i][j] * B[j][Object[t]])
if (mod == "viterbi"):
NodeTable[j][t], NodePath[j][t] = max(temp)
if (mod == "viterbi"):
print (u"viterbi算法结点值记录表:")
printTable(NodeTable)
print (u"viterbi算法路径记录表:")
printTable(NodePath, type="int")
target = 0
maxValue = NodeTable[target][T - 1]
for i in range(1, NumState):
if NodeTable[i][T - 1] > maxValue:
target = i
maxValue = NodeTable[i][T - 1]
print (u"viterbi算法最终状态:", target + 1, "\n")
StateSequeues = [0] * T
StateSequeues[T - 1] = target + 1
for i in range(1, T):
StateSequeues[T - i - 1] = NodePath[StateSequeues[T - i] - 1][T - i]
return StateSequeues
I = forwardV(A1, B1, pi1, Object1, mod="viterbi")
print (u"通过viterbi算法求得最优路径 I=", I, "\n")
运行结果:
