前言
最近NLP课上讲完了隐马尔可夫模型,听得我一脸懵逼。

但是HMM实在是太优美、太好用了,因此决定写一篇博客好好理解一下HMM,同时给其他与我一样有疑难的童鞋们解惑。
一、马尔可夫模型
为了理解隐马尔可夫模型,首先要知道马尔可夫模型怎么来的。
马尔可夫模型是一个随机过程,假设一个系统存在N个状态,记为
s1,s2,...,sN,状态的转移依据时间进行。我们用
qt表示系统在时间t的状态变量(
si中的一个),那么有t时刻,状态取值为
sj,(1≤j≤N)的概率则取决于前t-1个时刻的状态,如下:
p(qt=sj∣qt−1=si,qt−2=sk,...)
简言之就是后面的状态依赖于前面所有已有状态
但是如果每次都考虑前t-1个状态实在太复杂了,并且并不是前面所有的状态都对当前状态有很大影响。因此我们有以下两点假设:
-
若在特定情况下,系统在时间t的状态仅与其在t-1的状态相关,则有
p(qt=sj∣qt−1=si,qt−2=sk,...)=p(qt=sj∣qt−1=si)(1)
不再考虑前面所有状态,改为只考虑前一个状态。这个也被称为离散一阶马尔可夫链
-
若只考虑公式(1)独立于时间的随机过程,假设状态与时间无关,则有
p(qt=sj∣qt−1=si)=aij,1≤i,j≤Naij≥0j=1∑Naij=1
假设了状态的转移不再受时间限制,只依赖前一个状态
如下是一个马尔可夫链的例子:
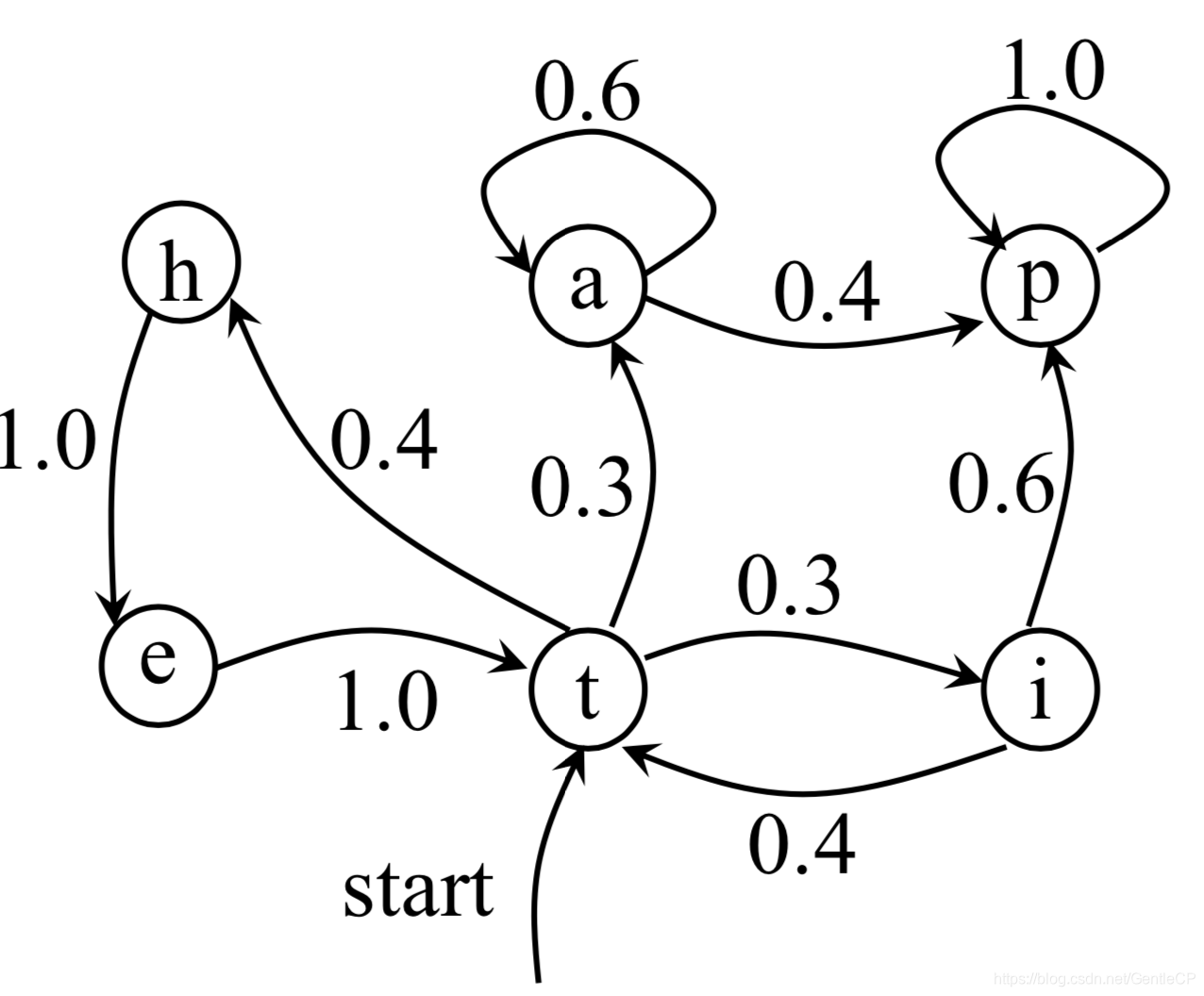
由上图计算从状态t经过状态i转移到状态p的概率,如下:
p(t,i,p)=p(s1=t)×p(s2=i∣s1=t)×p(s3=p∣s2=i)=1.0∗0.3∗0.6=0.18
二、隐马尔可夫模型
2.1 定义
在马尔可夫模型中,每个状态都是一个可观察时间,想象状态t表示(天气晴),i表示(天气阴),p表示(天气雨),则
p(t,i,p)就表示从晴天开始转换到阴天再转换到雨天的概率。注意在马尔可夫模型中,这些状态都是可以直接观察的,但很多情况下我们并不能直接观察到,我们只能通过一些特征去猜测当前的状态值(相当于多了一层随机过程),该模型是一个双重随机过程,其状态转换过程是不可观察的(隐蔽的),能观察的是这些隐蔽状态对应的随机函数。
以天气为例,晴天的结果就是地面是干燥的(随机函数输出),我们通过观测到地面是干燥的,猜测当前的状态可能是晴天。
下面是隐马尔可夫模型的一个图解:
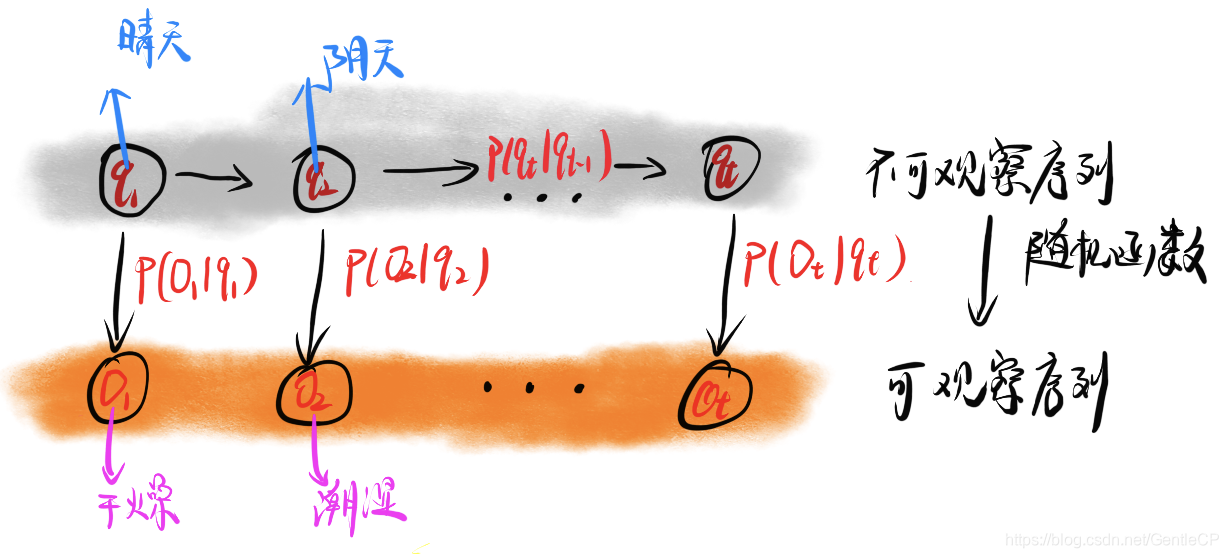
隐马尔可夫序列更符合我们实际应用中遇到的状态转移情况,简言之就是通过观测自然现象,推测实际情况。
因此,我们可以发现一个HMM(隐马尔可夫模型)包含以下几部分:
-
模型中状态的数目N(晴天、阴天、雨天…),内容记为集合
S
-
从每个状态可能输出的不同特征(观测值)的数目M(干燥、潮湿…) ,内容记为集合
K
注意不同的状态可能输出相同的特征(可观察结果)
-
状态转移概率矩阵
A={aij},这个和马尔可夫对应,在图解中就是
qi转移到
qj的概率矩阵,满足:
p(qt=sj∣qt−1=si)=aij,1≤i,j≤Naij≥0j=1∑Naij=1
例如今天下雨,明天则是晴天的概率
-
从状态
sj观察到特征
Ok的概率分布矩阵
B={bj(k)},
bj(k)表示第j个天气对应第k个特征的概率,其中:
bj(k)=P(Ot=vk∣qt=sj),1≤j≤N;1≤k≤Mbj(k)≥0k=1∑Mbj(k)=1
例如如果是雨天,地面会潮湿的概率
-
初始状态概率分布
π={πi},其中:
πi=P(q1=si),1≤i≤Nπ≥0i=1∑Nπi=1
例如起始是晴天还是雨天的概率
由此,我们可以将一个HMM记为五元组
(μ=(S,K,A,B,π))。上面的描述可能有点抽象,我们看一个实际的例子:
2.2 一个HMM例子
-
设状态集合
S={晴天,阴天,雨天}
-
设观测集合
K={干燥、潮湿}
-
状态之间转移概率矩阵
A(我们用表格表示)
| \ |
晴天 |
阴天 |
雨天 |
| 晴天 |
0.4 |
0.5 |
0.1 |
| 阴天 |
0.3 |
0.4 |
0.3 |
| 雨天 |
0.2 |
0.3 |
0.5 |
例如当前是晴天,转移到阴天的概率是0.5
-
状态-特征转移概率矩阵
B
| \ |
干燥 |
潮湿 |
| 晴天 |
0.8 |
0.2 |
| 阴天 |
0.6 |
0.4 |
| 雨天 |
0.3 |
0.7 |
例如晴天导致地面干燥的概率是0.8
-
初始状态概率分布
π
那么我们连续观察三天地面结果,发现地面为“干湿湿”,对应状态序列为“晴阴雨”的概率就可以计算如下:
P(“干干湿”,“晴阴雨”)=P(晴)∗P(干∣晴)∗P(阴∣晴)∗P(干∣阴)∗P(雨∣阴)∗P(湿∣雨)=0.3∗0.8∗0.5∗0.6∗0.3∗0.7=0.01512
同样我们可以计算“晴晴晴”,“晴雨阴”等等所有状态的概率,概率最大者就是状态序列(每天的天气)的变化,这也是下面要讲的序列问题。
三、HMM的三个基本问题
了解了HMM之后,需要知道其三个基本问题:
-
估计问题:给定一个观察序列
O=O1O2...OT和模型
μ=(A,B,π),如何快速计算该序列的概率
P(O∣μ)
计算观测序列产生的概率
-
序列问题:也叫预测问题,给定一个观察序列
O=O1O2...OT和模型
μ=(A,B,π),如何快速有效地选择一定意义下“最优”的状态序列
Q=q1q2...qT,使得该状态序列“最好地解释”观察序列。
例子如上文造成“干干湿”观察序列的最可能天气变化状态序列是什么,计算每个可能状态序列的概率,取概率最大者就是实际天气状态的变化。
-
训练问题或参数估计问题:给定一个观察序列
O=O1O2...OT,如何根据最大似然估计来求模型的参数值?即如何调节模型
μ=(A,B,π)的参数,使得
P(O∣μ)最大?
在实际问题中,HMM需要人为构建,构建的重点便是计算
A,B,π
为了解决上述三个问题,需要理解前向、后向、维特比等系列算法和参数估计,如下内容所示。
3.1 估计问题:求解观察序列的概率
所谓求解观察序列概率,即在确定了模型
μ的情况下,想要知道各个观察序列发生的可能性。比如观测到地面是“干干湿”的概率,需要联想是什么造成了“干干湿”,雨天也有可能发现地面是干的,只不过概率较小罢了。因此,产生“干干湿”的原因可能是一开始是晴天(由
π(晴))确定,然后乘上在“晴天”这一隐藏状态观察到“干”的概率,而第二个“干”则是由下一状态产生的,这个过程涉及到状态的转移和观测结果的生成,如“晴天”转到“晴天”再产生“干”,或者“晴天”转到“雨天”再产生干。
具体的数学推导公式不好理解,这里画一个图来解释
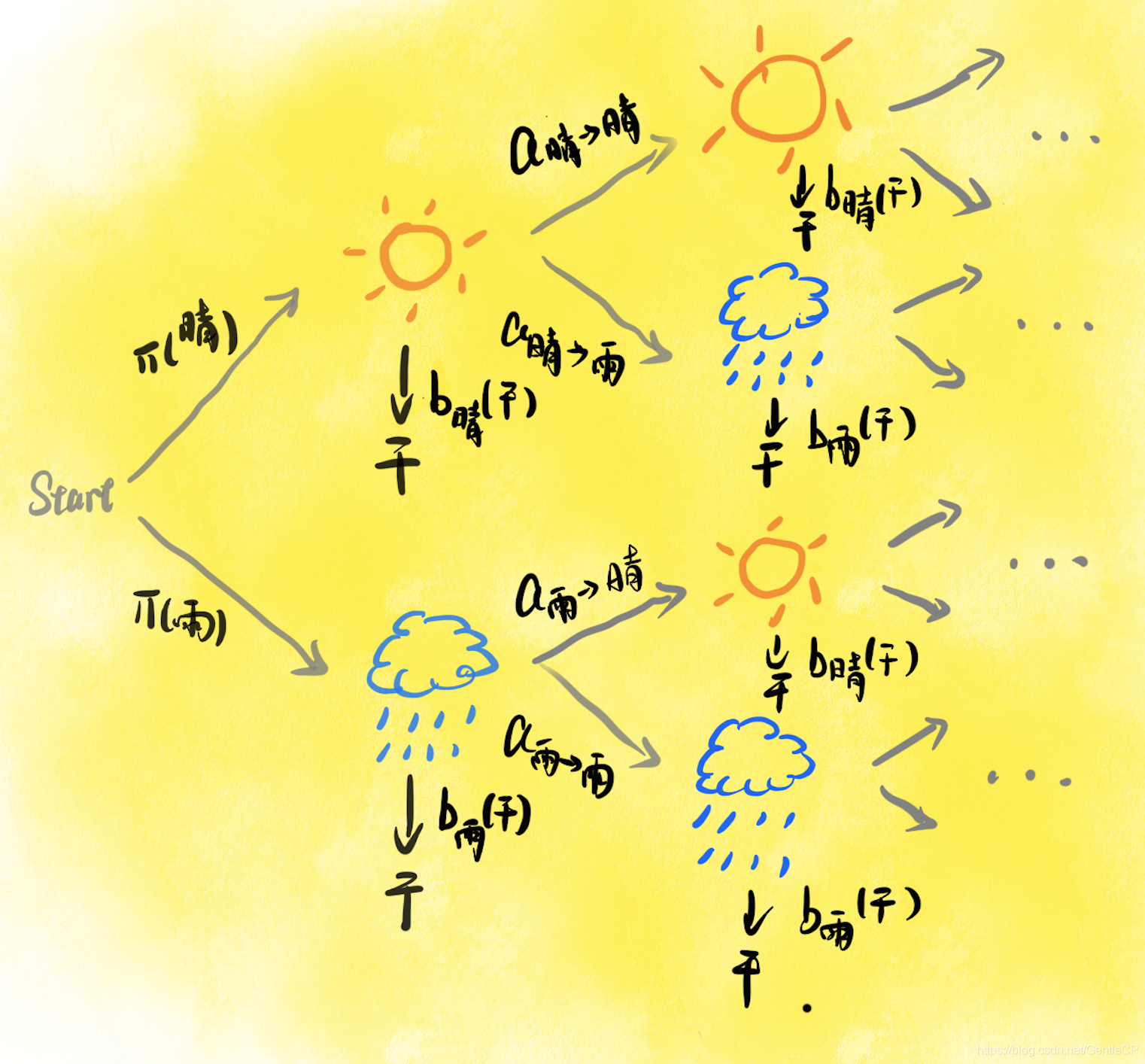
其中
π(晴)表示一开始是晴天的概率,
a晴→晴表示从晴天转移到晴天的概率,
b晴(干)表示在晴天观察到地面干的概率
根据图结果我们可以看出要计算
P(O∣μ),必须枚举所有可能的状态序列Q,假设模型有N个不同状态,时间长度为T,那么可能的状态序列就有
NT个,当N和T稍大一些,指数级的运算就会使计算机不堪重负。而对于这类指数级的计算问题,要想降低其计算成本,容易想到利用动态规划,最终时间复杂度可以压缩到
O(N2T),实现的算法是前后向算法
关于指数级问题联想动态规划不理解的可以参考我这篇文章算法设计与分析:动态规划 - 矩阵链式相乘问题
为了更好地进行描述,我们将状态和时间关系用点和箭头构成网络(也称格架),如下所示:
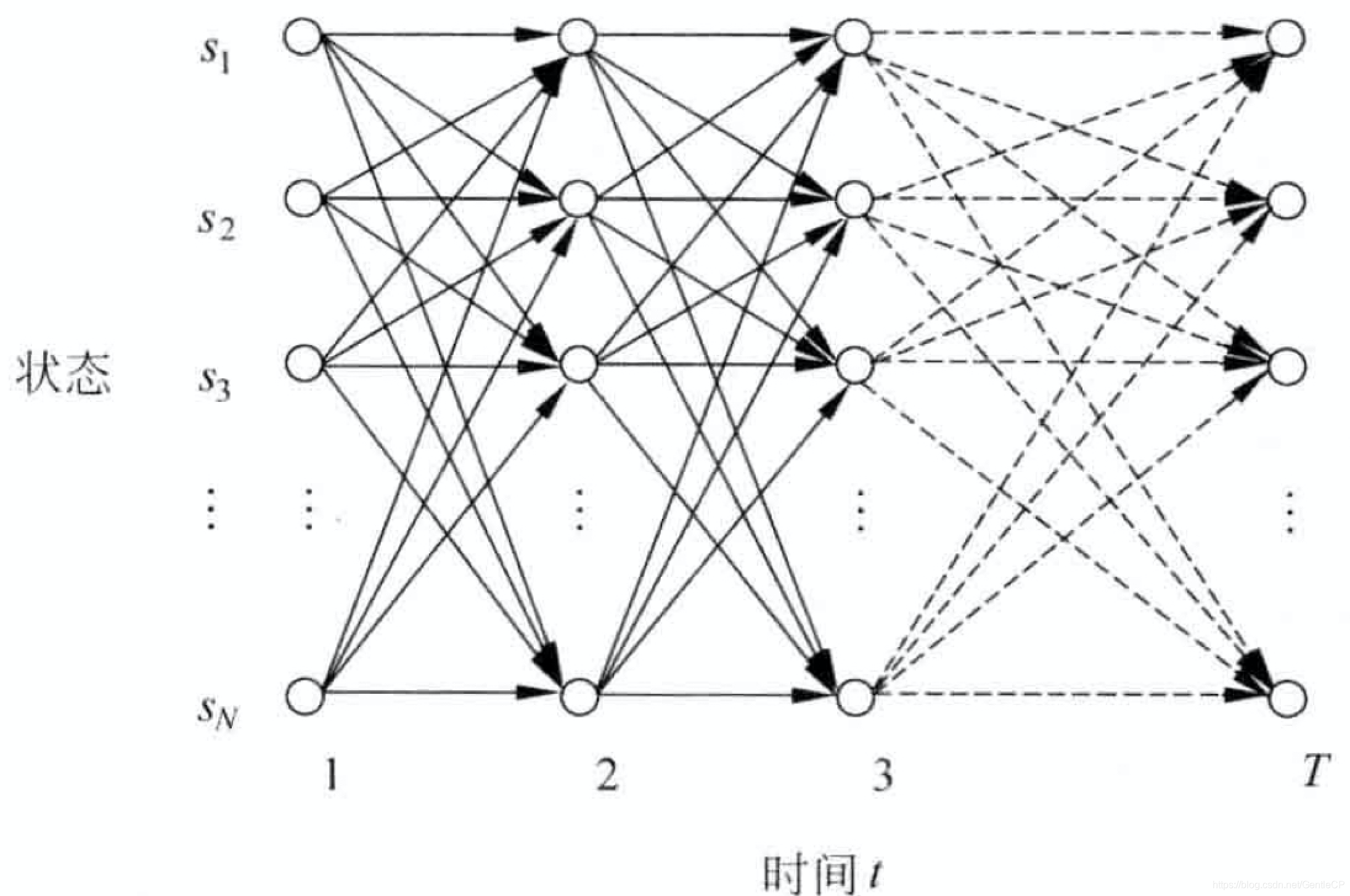
其中,每一个格记录在某一时间结束在一定状态下HMM的所有输出特征的概率,多个格子之间形成路径,较长路径概率可由较短路径计算得到。
你也可以将其想像成一个矩阵,横坐标是状态
si,纵坐标是时间
ti,矩阵存放对应输出特征序列的概率
下面我们介绍一下前向算法,
3.1.1 前向算法
- 前向变量
先定义一个前向变量
αt(i),指在时间t,HMM输出了序列
O1O2...Ot,且位于
si的概率,计算公式如下:
αt(i)=P(O1O2...Ot,qt=si∣μ)
若我们能够快速计算
αt(i),就可以在此基础上计算出
P(O∣μ)(在所有状态下观察到序列
O1O2...OT的概率)
P(O∣μ)=si∑P(O1O2...OT,qT=si∣μ)=i=1∑NαT(i)
要求的是输出
O1O2...OT的概率,而输出
O1O2...OT时可能位于的状态有N个,例如输出“干干湿”,最后可能是晴天,也可能是雨天,那么输出“干干湿”的概率就是输出“干干湿”,最后是晴天的概率加上输出“干干湿”,最后是雨天的概率。
考虑
αt+1(j)和
αt(i),1≤i≤N的关系,有如下:
αt+1(j)=(i=1∑Nαt(i)aij)bj(Ot+1)
我们详细解释一下这个公式,首先理清
αt(i)表达的含义是在已知观察序列
O1O2...Ot的情况下,最后状态位于
si的概率
下图详细地阐述了这一过程:
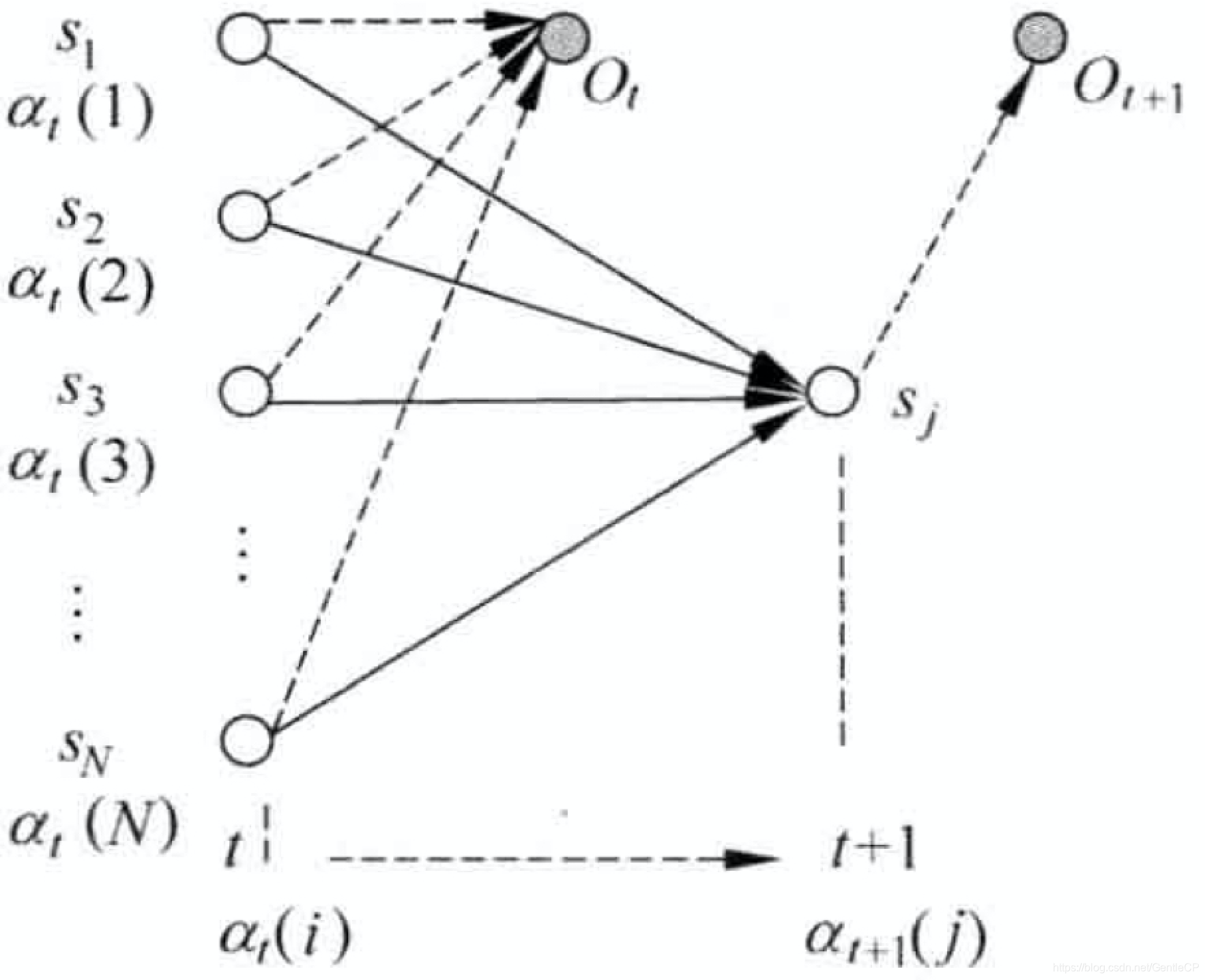
我们可以将时间从1到t+1,HMM到达状态
sj,输出观察序列
O1O2...Ot+1的过程分解成两步(先到t时刻,再从t时刻到t+1)
-
从1到t,HMM到达状态
si,输出观察序列
O1O2...Ot
可以看出过程和t+1是一样的,只是状态和时间点不一样,说明这是一个递归的过程,也可以用动态规划迭代的方式来刷新
-
从状态
si转移到状态
sj,在状态
sj输出观测值
Ot+1
关键就在于这一步的转移需要考虑所有的状态
由上我们可以发现当第一步完成后,从
si到
sj变换的概率是
αt(i)∗aij∗bj(Ot+1)
其中
aij是状态
i转移到状态
j的概率,
bj(Ot+1)是状态j产生
Ot+1观测值的概率
而由于我们要考虑所有的状态转移到状态j(i从1到N),因此就有
αt+1(j)=(i=1∑Nαt(i)aij)bj(Ot+1)
简言之就是计算t+1的时候,可能是从t的任何一个状态转移而来的,例如t+1天是晴天,前一天可能是晴天也可能是雨天。
最后,我们可以对前向算法进行定义:
-
初始化:
α1(i)=πibi(O1),1≤i≤N
初始状态是初始状态概率分布和其输出对应观测值的结果
-
递归表达式
αt+1(j)=(i=1∑Nαt(i)aij)bj(Ot+1),1≤t≤T−1
-
对前向变量求和
P(O∣μ)=si∑P(O1O2...OT,qT=si∣μ)=i=1∑NαT(i)
为什么对所有T时刻下前向变量求和即可得到
P(O∣μ)?
注意
P(O∣μ)表示在所有状态
qT下观察到
O1O2...OT的概率,而
αT(i)表示在状态
qi下观测到
O1O2...OT的概率,对i求和就是所有的状态的概率和
可以发现前向算法是典型的动态规划迭代更新的,每一个
αt(i)要考虑前一时刻t-1的N个状态,时间复杂度为O(N),而对于每一个当前时刻点t,要计算每个状态的前向变量
αt(1),αt(2)...,因此对于一个时刻的计算时间复杂度为
O(N2),我们一共需要计算T个时刻,因此总的时间复杂度是
O(N2T)
前向算法之所以能够降低时间复杂度,是因为后面的计算结果都是建立在前面计算完成的结果上,那么前面的内容就不需要多次重复计算,因此省去了大量计算
-
一个前向算法的例子
考虑一个抽球问题,一共有两个盒子,A盒中放1个白球,一个黑球;B盒中放两个黑球。现在告诉你下列循环操作:
- 开始随机从一个盒子中拿球,记录其颜色,然后放回
- 重新选择盒子,如果上一次选择了A盒,这一次选择B盒;否则,随机选取一个盒子
- 确定盒子后,从中拿一个球,记录颜色后,将其放回
- 重复上述过程n次,得到观测序列
K
问:当进行5次记录,观测序列
O为
{白,黑,黑,黑,白}时,用前向算法计算该观测序列产生概率?
答:很明显这是一个HMM问题,我们能观察的只是球的颜色,具体选了哪一个盒子并不知道。首先找到HMM的5元组
μ=(S={A盒,B盒},K={白球,黑球},π,A,B):
-
初始状态概率分布
π
一开始随机抽取,所以两盒概率相同
-
状态之间转移概率矩阵
A
依据题意A必然转到B可得
-
状态-特征转移概率矩阵
B
特征实际上就是观测值
为了计算的方便,将A盒状态记为状态0,B盒状态记为状态1,白球记为0,黑球记为1。 按照前向算法的步骤如下计算:
-
初始化
α1(i),这里i只有两个状态0,1
α1(0)=π(0)×B00=0.25α1(1)=π(1)×B10=0
第一个摸出白球,可能是从0(A盒),也可能是从1(B盒)摸出,对应初始概率分别为
π(0),π(1)。从0摸出,又观测到是白球的概率
B00;从1摸出,又观测到是白球的概率
B10,得上面结果
-
利用前向递推式计算后面的
α(i),1<i<=5
α2(0)=[α1(0)×A00+α1(1)×A10]×B01=0α2(1)=[α1(0)×A01+α1(1)×A11]×B11=0.25
后面3,4,5的计算与2同理,因此详细解释下2怎么来的。
α2(0)代表输出观测序列的前两个观测值后,位于状态0的概率,它可能从
α1(0)来,也可能从
α1(1)转移而来,而要形成这个转移,就要乘上对应的转移概率,因此,
α1(0)到
α2(0)是状态0到状态0的转移,乘以
A00,
α1(1)到
α2(0)是状态1到状态0的转移,乘以
A10。转移成功后,仍需要考虑输出观测值的概率,这一点和
α2(i)之前从哪来无关,而受它当前状态影响。
α2(0)当前状态为0,所以最终乘上
B01(处于状态0观测到值1的概率)。
α3(i),α4(i),α5(i)计算同理,不多赘述。
-
停止计算
到了
α5(0),α5(1),前者意味着,输出
{白,黑,黑,黑,白}后,最终状态停留在了0(相当于最后一个球是从A盒摸出来的);后者意味着,最终状态停留在了1(相当于最后一个球是从B盒摸出来的)。生成观测序列没有别的可能情况了,所以总的产生观测序列
{白,黑,黑,黑,白}的概率所有可能情况概率之和:
p(O∣μ)=α5(0)+α5(1)=0.03125
简单例子对于理解前向算法有很好的帮助,建议手动算一下
3.1.2 后向算法
后向算法其实也是为了解决大量计算造成的高时间复杂度,只不过从实现方向上与前向算法不同,它先从后面开始计算。
同样相对的,我们定义一个后向变量
βt(i),其表示在时间t状态为
si时,HMM输出观察序列
Ot+1Ot+2...OT的概率:
βt(i)=P(Ot+1Ot+2...OT∣qt=si,μ)
我们将时间t状态为
si时,HMM输出
Ot+1Ot+2...OT分成两个步骤:
-
在时间t+1,状态为
sj情况下,HMM输出观察序列
Ot+2Ot+3...OT
-
从时间t到时间t+1,HMM从状态
si变为状态
sj,并输出
Ot+1
这里为了和前向算法对应,我将递归的步骤放到了前面。考虑第一步中输出
Ot+1的概率应为
aij∗bj(Ot+1),第二步中由于采用了递归只是时刻到了t+1,状态从i到了j,所以概率为
βt+1(j),最终归纳表达式如下:
βt(i)=j=1∑Naijbj(Ot+1)βt+1(j)
最终,我们得到了后向算法的定义,如下:
-
初始化:
βT(i)=1,1≤i≤N
-
递归表达式
βt(i)=j=1∑Naijbj(Ot+1)βt+1(j),T−1≥t≥1;1≤i≤N
-
对后向变量求和
P(O∣μ)=si∑P(O1O2...OT,qT=si∣μ)=i=1∑Nπibi(O1)β1(i)
最后的结果是在1时刻得到的
-
一个后向算法的例子
同样是前向算法中例子,不过采用后向算法计算。 计算步骤如下:
-
初始化
β5(i)
β5(i)=1,i=1,2
-
利用后向推导式计算
β4(0)=β5(0)A00B00+β5(1)A01B10=0β4(1)=β5(0)A10B00+β5(1)A11B10=0.25
当计算
β4(0)时,其实是考虑它下一个步可以往哪个状态移动,可以是0也可以是1。若是0,即需要从0状态到0状态,因此状态转移概率是
A00,转移到了0状态后,观测得到是白球的概率是
B00;若是1,即需要从0状态到1状态,因此状态转移概率是
A01,转移到了1状态后,观测得到是白球的概率是
B10。后面的计算同理,不多赘述。
-
停止计算
当计算到达
β1(i)时,不需要再继续向前传递了。而我们看看,这个时候的
β1(0)是什么含义?依据定义,是当在时间1时,状态为0,输出
O′为
{黑,黑,黑,白}的概率,进一步我们想要得到
O为
{白,黑,黑,黑,白}的概率,只需要在此基础上计算输出一个白球的概率,这个白球可能从A盒出,也可能从B盒出。若是A盒,首先需选中A盒,概率
π(0),然后乘上选出A盒后观测到白球的概率
B00,此时的状态已经是位于0了,因此最后乘上
β1(0),得到完整的观测序列
O。若选了B盒,情况同理,只不过起始状态不一样了(一个是0,一个是1)。 这两种情况都是产生观测序列的可能,因此要将它们加起来,最终表达式如下:
p(O∣μ)=π(0)×B00×β1(0)+π(1)×B10×β1(1)=0.03125
其实仔细思考就容易发现,无论是前向还是后向,都是一条寻路的过程。前向从前到后,每一个状态会询问上一层所有可能状态(我可能从哪来),知道后,对应于当前所处的状态,输出观测值(相当于多对一)。后向,从后往前,每一个状态会询问下一层所有可能状态(我可能到哪去)。而所有的转移都是有代价的(由状态间转移概率矩阵
A)给出,转移完成后正确输出观测值(由状态,观测概率矩阵
B)给出。
3.1.3 前后向结合计算观察序列概率
深入理解了前后向算法后,我们可以知道前向算法从前往后计算,后向算法从后往前计算,
P(O∣μ)表示产生观察序列
O1O2...OT的概率,该概率包含所有不同状态下产生该序列概率的和,对于给定状态
si,其产生O序列的概率为
P(O,qt=si∣μ),因此有:
P(O∣μ)=i=1∑NP(O,qt=si∣μ)
而对于
P(O,qt=si∣μ),我们有如下推导:
P(O,qt=si∣μ)=P(O1O2...OT,qt=si∣μ)=P(O1O2...Ot,qt=si,Ot+1...OT∣μ)=P(O1O2...Ot,qt=si∣μ)∗P(Ot+1...OT∣O1O2...Ot,qt=sI,μ)=P(O1O2...Ot,qt=si∣μ)∗P(Ot+1...OT,qt=sI,μ),由于状态只和最近一个状态有关,后面的条件可去掉=αt(i)∗βt(i)
因此,我们可以利用前后向算法相结合来计算
P(O∣μ):
P(O∣μ)=i=1∑Nαt(i)∗βt(i),1≤t≤T
这个公式的直观理解就是前向变量负责输出观测序列的前半部分,后向变量负责输出观测序列的后半部分,最后组合形成了整个序列。
3.2 序列问题:维特比算法
再回顾一下问题:
-
给定一个观察序列
O=O1O2...OT和模型
μ=(A,B,π),如何快速有效地选择一定意义下“最优”的状态序列
Q=q1q2...qT,使得该状态序列“最好地解释”观察序列
用直白的语言就是什么样的实际状态序列最有可能产生观测序列
由此我们可以定义最优序列Q即使条件概率
P(Q∣O,μ)最大的状态序列,如下:
Q^=QargmaxP(Q∣O,μ)
维特比算法很好地解决了这一问题,同样采用动态规划的方式。
-
维特比变量
维特比变量是在时间t时,HMM沿着某一条路径到达状态
si,并输出观察序列
O1O2...Ot的最大概率:
δt(i)=q1,q2,...,qt−1maxP(q1,q2,...,qt=si,O1O2...Ot∣μ)
简单来说就是找到产生观察序列的可能性最大的状态序列,按照不同的状态个数(设状态数为M),最后形成
O1O2...Ot的可能有M种(即最后一个状态是停留在M个状态之一)
维特比变量的递推关系如下:
δt+1(j)=imax{[δt(i)∗aij]∗bj(Ot+1)}
解读一下这个递推式,在时间t+1时HMM沿某一条路径到达状态j,输出观察序列
O1O2...Ot+1的最大概率等于时间t最大概率乘以其到j状态的转移概率的最大者在乘上输出
Ot+1观测值的概率。
简而言之,就是将前面的结果乘以其转移概率之后最大的挑出来。
由于我们需要输出的是状态序列,因此还需要另外一个数组用于存储整个最大概率路径结果,记作
ψ(i)。最终,得到维特比算法的定义如下:
ψ(i) 是用于记录路径中前一个状态结果的,当我们计算出最后停留状态,找到
δt(i),i=1,...,M后,就可以取最大者就是形成该序列的最大概率。有了最大的
δt(i)后,就有了观测序列的最大可能状态序列的最后一个状态
Qt,将其代入
ψt+1(Qt)就可以获得该最大路径上的前一个状态
Qt−1,一直迭代进行 ,就可以将该序列输出出来。
-
初始化
δ1(i)=πibi(O1),1≤i≤Nψ1(i)=0
初始概率由初始概率和观测概率共同得到
-
递归表达式
δt+1(j)=1≤i≤Nmax[δt(i)∗aij]∗bj(Ot+1),1≤t≤T−1;1≤j≤Nψt+1(j)=1≤i≤Nargmax[δt(i)∗aij]∗bj(Ot+1),1≤t≤T−1;1≤j≤N
-
终止结果
Q^T=1≤i≤Nargmax[δT(i)]P^(Q^T)=1≤i≤Nmax[δT(i)]
-
状态回溯(路径查询)
用于找出状态序列
q^t=ψt+1(q^t+1),t=T−1,T−2,...,1
实际应用的时候,最佳状态序列可能不只一个,往往会记录m个。下面这是一个应用维特比算法的例子。
