目录
关于什么是隐马尔可夫模型我想你看到的解释应该是酱紫的:
隐马尔可夫模型(Hidden Markov Model,HMM)是统计模型,它用来描述一个含有隐含未知参数的马尔可夫过程。其难点是从可观察的参数中确定该过程的隐含参数。然后利用这些参数来作进一步的分析,隐马尔科夫模型在语音识别、自然语言处理、生物信息、模式识别等领域有着广泛的应用。
或者是这样子的:
隐马尔可夫模型是关于时序的概率模型,描述由一个隐藏的马尔可夫链随机生成不可观测的状态随机序列,再由各个状态生成一个观测而产生观察随机序列的过程......
看不懂没关系,我也看不懂,这可能是出于专业出版的对于定义的严谨性,所以很多时候看不懂一些文献、书籍没关系,我很喜欢博客上各位大神的博文,他们常常能够解决我最根本的问题,看懂了他们博文,再去看书籍和文献,什么都通了。
一、什么是隐马尔可夫模型
我们先用一个例子来说明一下什么是隐马尔可夫模型
该例子来自Yang Eninala博士的知乎https://www.zhihu.com/question/20962240/answer/33438846
一个经典的例子,掷骰子。假设我手里有三个不同的骰子。第一个骰子是我们平常见的骰子(称这个骰子为D6),6个面,每个面(1,2,3,4,5,6)出现的概率是1/6。第二个骰子是个四面体(称这个骰子为D4),每个面(1,2,3,4)出现的概率是1/4。第三个骰子有八个面(称这个骰子为D8),每个面(1,2,3,4,5,6,7,8)出现的概率是1/8。
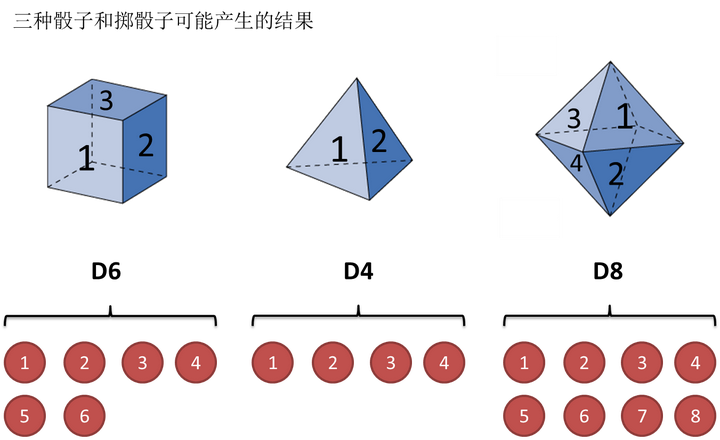
假设我们开始掷骰子,我们先从三个骰子里挑一个,挑到每一个骰子的概率都是1/3。然后我们掷骰子,得到一个数字,1,2,3,4,5,6,7,8中的一个。不停的重复上述过程,我们会得到一串数字,每个数字都是1,2,3,4,5,6,7,8中的一个。例如我们可能得到这么一串数字(掷骰子10次):1 6 3 5 2 7 3 5 2 4
这串数字叫做可见状态链。但是在隐马尔可夫模型中,我们不仅仅有这么一串可见状态链,还有一串隐含状态链。在这个例子里,这串隐含状态链就是你用的骰子的序列。比如,隐含状态链有可能是:D6 D8 D8 D6 D4 D8 D6 D6 D4 D8,这条链就是HMM中说到的马尔可夫链。基于这种类型引发的问题就是隐马尔可夫模型。
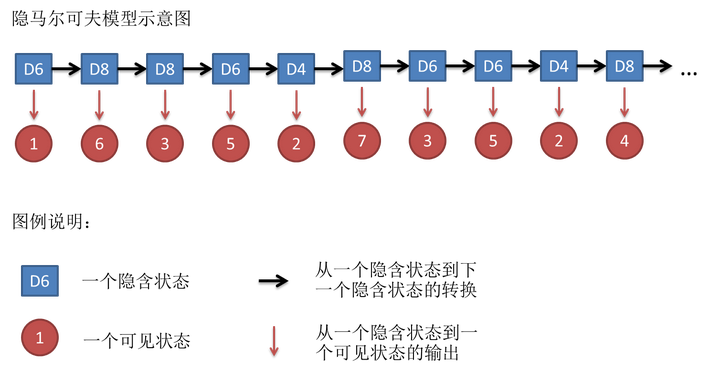
马尔可夫链不是为了隐马尔科夫模型取的,他的应用也不只是隐马尔可夫。
我们再来看看马尔可夫链的定义过程:
马尔可夫过程的定义:
⑴设  是一个随机过程,如果在
是一个随机过程,如果在  在
在  时刻所处的状态为已知时,
时刻所处的状态为已知时,  以后的状态与它在时刻
以后的状态与它在时刻  之前所处的状态无关,则称具有马尔可夫性。(就是说某个状态的概率只受前一个状态的影响)
之前所处的状态无关,则称具有马尔可夫性。(就是说某个状态的概率只受前一个状态的影响)
⑵设 的状态空间为
的状态空间为  ,如果对于任意的
,如果对于任意的  ,任意的
,任意的 ,在条件
,在条件  下,
下, 的条件概率分布函数恰好等于其在条件
的条件概率分布函数恰好等于其在条件 下的条件概率分布函数,即
下的条件概率分布函数,即

则称 为马尔可夫过程。
为马尔可夫过程。
((2)在于用公式来表达定义(1),==》P(t时刻的状态|前1—t-1时刻发生的条件下)=P(t时刻的状态|t-1时刻发生的条件)
其实对于HMM来说,如果提前知道所有隐含状态之间的转换概率和所有隐含状态到所有可见状态之间的输出概率,做模拟是相当容易的。但是应用HMM模型时候呢,往往是缺失了一部分信息的,有时候你知道骰子有几种,每种骰子是什么,但是不知道掷出来的骰子序列;有时候你只是看到了很多次掷骰子的结果,剩下的什么都不知道。如果应用算法去估计这些缺失的信息,就成了一个很重要的问题。这些东西就是HMM要解决的问题。
二、隐马尔可夫模型要解决的问题
*在提问题之前我们先来定义几个变量(重新看一下这个图的图例)
*几个矩阵的定义
| 所有可能的状态集合 |
所有可能的观测集合 |
| T时刻的状态序列 |
T时刻的观测序列 |
| 状态转移概率矩阵
|
观测概率矩阵
|
| 模型参数 λ(A,B,Π),Π为初始状态概率向量,A为状态转移概率矩阵,B为观测概率矩阵,Π和A决定状态序列,B决定观测序列 | |
*马尔可夫链的两个假设
| (1)齐次马尔可夫假设: | 即t时刻的状态只受t-1时刻状态的影响 |
| (2)观测独立性假设: | 即任意时刻的观测只受该时刻所处状态的影响 |
*马尔可夫模型的三个基本问题
| (1)概率计算问题: | 给定模型参数 λ(A,B,Π)和观测序列 |
| (2)学习问题: | 给定观测序列 |
| (3)预测问题: | 给定参数 λ(A,B,Π)和观测序列 |
问题(1)是求条件概率问题。(2)在解决这个问题的时候用的是Baum-welch算法,它是由EM算法引发出来的,而EM算法里面又涉及到极大似然估计的知识,本文会简单的交代一下EM算法,至于极大似然估计的问题如果不懂的话先补完知识再看。往后有时间我会写这个节点的博文。(3)是隐马尔可夫模型的核心,很多领域对隐马尔可夫模型的应用大部分会是问题(3),比如在机器翻译做中文对英文的翻译时,单词的翻译总是有很多个意思,而词性往往起到很重要的作用,乍一看词性这一序列怎么跟我们说到的隐含的状态序列=(
)很像呢!类似这样的还有很多.......
如果只是想了解一下HMM是什么的话你了解到这里也就差不多了,如果想要知道他长什么样,那就往下。
三、问题解决
1.概率计算问题:
直接计算算法:对所有可能存在的状态序列 =(
),表示出来,形成一个状态序列空间
{
},并求
,即基于模型
求空间D中全部状态序列下出现O的概率。
联合概率
变成 发生的条件下
发生的概率
乘以
,
发生的条件下O发生的概率
其中 1) ,
=
,
表示所有可能状态序列
2)
故
对所有满足的
求和得到
至此算法结束
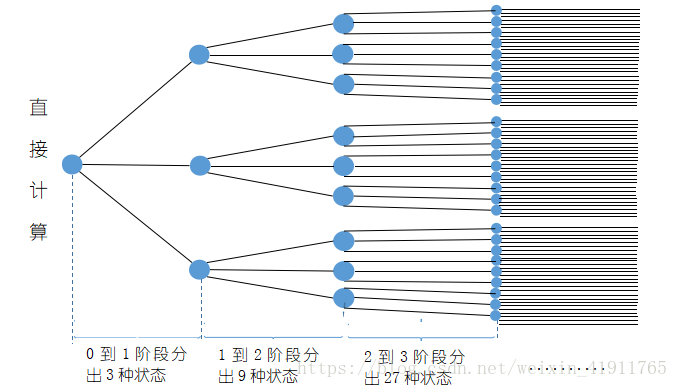
前向算法:直接计算算法很简单便捷,但是计算量很大,假设状态集合有N个可选的状态,而状态序列
有t个节点则可选的状态序列空间
就有
个可选序列,这意味这求和项要求和
次,可想而知,计算量不是一般的少。因此引入前向算法:每个节点处先对N个状态分别乘以转化率之后再求和,不理解没关系,先来一幅图。
大概看一下 :
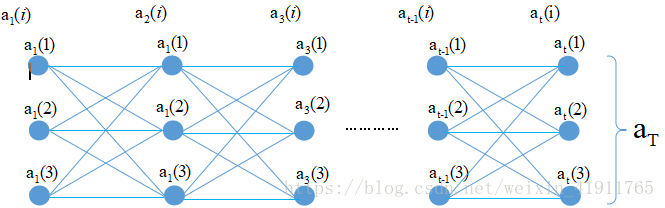
定义:
,表示时刻t,其部分观测序列为
,且状态等于
中的
故:
(1)初值: 即
遍历状态集合
(2)递推 for t =1 to T-1
即对上一个节点的所以状态乘转化率后求和再乘本 节点的生成概率
(3)终止 对最后一节点的所有
求和
后向算法:和前向算法一样,只是顺序倒置了而已,形状参考前向算法,只是对应的位置换成
。
定义:
,表示
时刻状态为
的条件下,往后部分观测序列为
的概率
(1)初值:
(2)递推 for t=T-1 to 1
(3) 终止
至此三个对概率计算的算法算结束了,为了对一下问题(2)和(3)的推导,引入一些概率与期望的计算
一些概率与期望值的计算
1)给定模型和观测序列
,在t时刻处于状态
的概率为:
由上述前向概率和后向概率
的定义可知:
于是得到:
2)给定模型和观测序列
,在t时刻状态
,且在t+1时刻处于状态
的概率为:
3)将和
对各个时刻t求和,可以得到一些有用的期望:
①在观测序列的条件下状态
出现的期望值:
②在观测序列的条件下由状态
转移的期望值:
③在观测序列的条件下由状态
转移到状态
的期望值:
注:上面几个应该有错,似乎忽略了各个时刻相交的部分,使得期望变大。
以1为例假如状态集Q有10个状态,时刻T=10,并且各个时刻状态下i出现的概率都是相等的,
则=0.1,
=1,这是不可能存在的,
应该是。
通项就是
但是的分布总是乱七八糟的,没办法写出通项来。
2.学习问题:
学习问题就是给定观测序列,求参数
映射到我们起初提到的骰子的例子大概就是知道了观测序列为
要求参数
1)A: t时刻选用骰子D4到t+1时刻选用骰子D6或D8的转换概率。
2)B: 任意时刻选用固定骰子后出现某个点数的概率。
3)Π: 其实选择骰子D4、D6、D8的概率。
如果知道了隐藏的状态序列,即是每个时刻都选用了哪个骰子的话,求参数
我们直接选用极大似然估计就好了,可是关键在于我们并不知道
是什么。因此我们采用Baum-welch算法来求解,而该算法来自与EM算法的变形。
Baum-Welch算法:
是为了解决HMM的参数估计问题而提出的,而且是没有标注也就是HMM的状态序列未知的参数估计问题。具体来说,就是已知观测序列O=(o1,o2,...,oT)O=(o1,o2,...,oT),估计模型参数λ=(A,B,π)λ=(A,B,π),使得在该模型下观测序列概率P(O|λ)P(O|λ)最大。由于状态序列未知,因此这可以看做是一个含有隐变量的参数估计问题,解决这一问题的经典算法就是EM算法。Baum-Welch算法就是EM算法在隐马尔科夫模型学习中的具体体现。下面简单叙述一下该算法。
首先按照EM算法,我们需要先写出Q函数。Q函数是完全数据的对数似然函数关于给定模型参数和观测变量的前提下对隐变量的条件概率分布的期望。如下:
我们写出Q函数之后后面就要对它进行极大化,也就是说EM算法的M步骤。既然是最大化,那么只要保证不影响最终的结果,对Q函数进行对于最大化来说没有影响的常数因子乘除是可以的。我们注意到Q函数的后部分
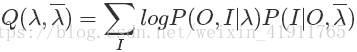
而P(O|λ)P(O|λ)便是概率计算问题中我们解决的问题,对于固定的模型参数来说它是一个常量,因此我们为了后边计算方便可以在上面原先的Q函数的基础上乘以它,使得Q函数成为:
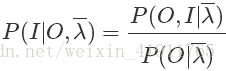
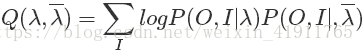
为什么要这么做呢?这是为了后面将概率计算问题中有意义的一些概率计算公式直接套进去。
又因为完全数据可以写成这样:
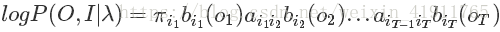
于是Q函数可以写成:
此时我们看到待估计的参数刚好分别出现在三个项中,所以只需对各个项分别极大化。然后直接极大化我们无法对公式进行细致描述,因此需要将以上Q函数形式修改一下,变成下面这样:
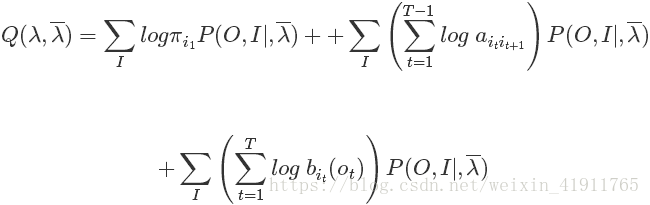
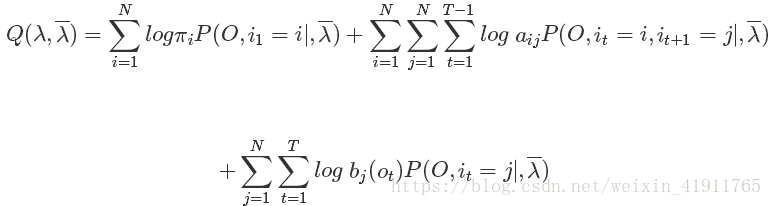
可以看到,我们将三项中分别的对的求和进行了划分。由于隐变量=(
)。原来的求和需要遍历所有
的取值,然后进行求和,然而这基本是不可能完成的任务。改写后,我们将遍历的空间进行了划分,同时很好地将
部分改写后也融入到求和其中。比如第一项,对
的遍历等价于先固定状态
,使其分别取值所有可能的状态(共有N个可取的离散状态),而
仍然像原来一样随便取值。这样,就把II空间划分成了N个更小的空间。然后再把这N个空间的结果相加,等价于原来对空间
进行遍历。
而且,改写之后部分变的可以表示了。如果对
函数的三项分别求极大,在计算后会发现,上面导出的有意义的概率可以用来表示。这也就是之前对
函数进行修改的原因。
接下来极大化,并求解满足目标最大化的参数A、B、
的值

用上面推导的公式有 ,
表示给定模型和观测序列
,在t=1时刻处于状态
的概率

表示对 (任意时刻由状态转移到状态
的所有求和项) 比上 (任意时刻处于状态
的所有求和项)

表示对(任意时刻状态为观测值为
的所有求和项) 比上 (任意时刻状态为
的所有求和项)
3.预测问题:
给定参数 λ(A,B,Π)和观测序列=(
),求隐含的状态序列
=(
).
套回骰子的例子就是已知参数,已知观测到的数字,求数字背后隐藏的是哪种骰子。
近似算法:
用公式表示就是
在每个时刻最可能隐藏的状态
从而状态序列:
由于存在转移概率为0的相邻状态,改算法很不稳定
维比特算法:
维比特算法分两步
第一步
计算每一步的值,即t时刻对每个状态求最大的
,并返回连接到当前状态的前一个最优状态。
始化
递推
终止
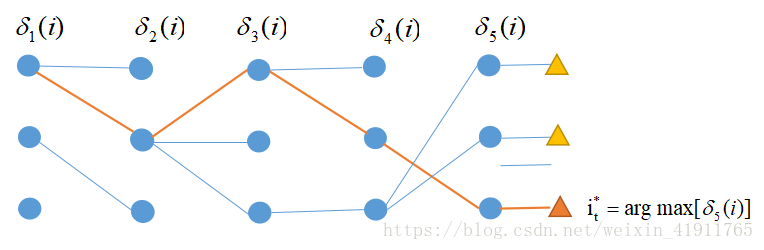
第二步:把T时刻的最优状态,作为参数回溯寻求每一步的最优
[1] 李航.统计学习方法[M].北京:清华大学出版社,2012:155-184
[2] 如何用简单易懂的例子解释隐马尔可夫模型?[Online],https://www.zhihu.com/question/20962240/answer/33438846
[3] ”相亲记“之从EM算法到Baum-Welch算法[Online],https://blog.csdn.net/firparks/article/details/54934112