序列标注与分词
所谓序列标注,就是讲一个序列进行切分,并对切分结果进行标注的过程。
最常见的序列标注当属词性标注。此时,需要将句子切分成块,并对每一个单词进行词性标注,这就是一个典型的序列标注问题。
分词当然也可以说是一个序列标注的过程,只不过标注集可为**{B,M,E,S}**,其中 B 为开头、M 为中间、E 为结尾、S 为单个词。从而将分词问题,转换为序列标注问题!
隐马尔科夫模型模型
隐马尔可夫模型模型实际上是一种状态转移模型
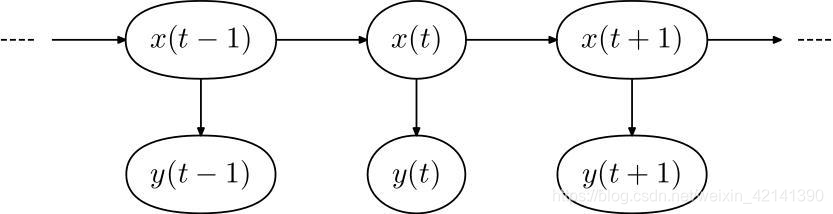
其中 y 为序列, x为状态。换句话说, y 为单词,x 为{B,M,E,S} 。
因此,在单词拆分中,我们认为状态决定单词拆分。
HanLP 实现
可见,要训练一个能够用于分词的隐马尔科夫模型模型,首先需要对已经分词的语料库进行标注。之后,再将语料库转换成二元组 。所幸的是,这些 HanLP 都为我们实现了。使用语料库训练模型如下(语料库为分词后的词典):
from pyhanlp import *
FirstOrderHiddenMarkovModel = JClass('com.hankcs.hanlp.model.hmm.FirstOrderHiddenMarkovModel')
HMMSegmenter = JClass('com.hankcs.hanlp.model.hmm.HMMSegmenter')
corpus_path = r'E:\Anaconda3\Lib\site-packages\pyhanlp\static\data\test\icwb2-data\training\msr_training.utf8' #数据集所在路径。可用txt文件
model = FirstOrderHiddenMarkovModel() #实例化一个马尔可夫模型
segmenter = HMMSegmenter(model) #实例化一个马尔可夫分类器
segmenter.train(corpus_path) #使用语料库训练模型
segment = segmenter.toSegment()
print(segment.seg('商品和服务')) #seg接口拆分句子
二阶马尔可夫模型
二阶模型认为,当前状态不仅与上一个状态有关,而且与上上个状态有关。我们亦可以用二阶马尔可夫模型,来实现句子的分词:
SecondOrderHiddenMarkovModel = JClass('com.hankcs.hanlp.model.hmm.SecondOrderHiddenMarkovModel')
model = SecondOrderHiddenMarkovModel() #实例化一个二阶马尔可夫模型
segmenter = HMMSegmenter(model) #实例化一个马尔可夫分类器
segmenter.train(corpus_path) #使用语料库训练模型
segment = segmenter.toSegment()
print(segment.seg('商品和服务')) #seg接口拆分句子