马尔可夫模型
在介绍隐马尔可夫模型之前,先来介绍马尔可夫模型。
我们知道,随机过程又称随机函数,是随时间而随机变化的过程。 马尔可夫模型(Markov model)描述了一类重要的随机过程。我们常常需要考察一个随机变量序列,这些随机变量并不是相互独立的,每个随机变量的值依赖于这个序列前面的状态。如果一个系统有N个有限状态S={s1,s2,…,sN},那么随着时间的推移,该系统将从某一状态转移到另一状态。Q=(q1,q2,…,qT)为一个随机变量序列,随机变量的取值为状态集S中的某个状态,假定在时间t的状态记为qt。对该系统的描述通常需要给出当前时刻t的状态和其前面所有状态的关系:系统在时间t处于状态sj的概率取决于其在时间1,2,…,t-1的状态,该概率为
P(qt=sj|qt-1=si,qt-2=sk,…)
如果在特定条件下,系统在时间t的状态只与其在时间t-1的状态相关,即
则该系统构成一个离散的一阶马尔可夫链(Markov chain)。
进一步,如果只考虑式(6-1)独立于时间t的随机过程:
该随机过程为马尔可夫模型。
显然,有N个状态的一阶马尔可夫过程有N^2次状态转移,其N^2个状态转移概率可以表示成一个状态转移矩阵。例如,一段文字中名词、动词、形容词三类词性出现的情况可由三个状态的马尔可夫模型描述:
状态s1:名词
状态s2:动词
状态s3:形容词
假设状态之间的转移矩阵如下:
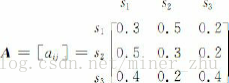
如果在该段文字中某一句子的第一个词为名词,那么根据这一模型M,在该句子中这三类词的出现顺序为O=“名动形名”的概率为:
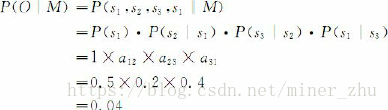
马尔可夫模型又可视为随机的有限状态机。如下图所示,圆圈表示状态,状态之间的转移用带箭头的弧表示,弧上的数字为状态转移的概率,初始状态用标记为start的输入箭头表示,假设任何状态都可作为终止状态。图6-4中省略了转移概率为0的弧,对于每个状态来说,发出弧上的概率和为1。从图可以看出,马尔可夫模型可以看作是一个转移弧上有概率的非确定的有限状态自动机。
一个马尔可夫链的状态序列的概率可以通过计算形成该状态序列的所有状态之间转移弧上的概率乘积而得出,即
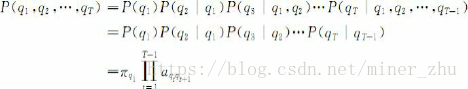
根据上图给出的状态转移概率,我们可以得到:
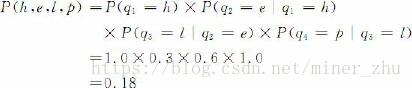
根据之前介绍的n元语法模型,当n=2时,实际上就是一个马尔可夫模型。但是,当n≥3时,就不是一个马尔可夫模型,因为它不符合马尔可夫模型的基本约束。不过,对于n≥3的n元语法模型确定数量的历史来说,可以通过将状态空间描述成多重前面状态的交叉乘积的方式,将其转换成马尔可夫模型。在这种情况下,可将其称为m阶马尔可夫模型,这里的m是用于预测下一个状态的前面状态的个数,那么,n元语法模型就是n-1阶马尔可夫模型。
隐马尔可夫模型(HMM)
在马尔可夫模型中,每个状态代表了一个可观察的事件,所以,马尔可夫模型有时又称作可视马尔可夫模型(visible Markov model, VMM),这在某种程度上限制了模型的适应性。在隐马尔可夫模型(HMM)中,我们不知道模型所经过的状态序列,只知道状态的概率函数,也就是说,观察到的事件是状态的随机函数,因此,该模型是一个双重的随机过程。其中,模型的状态转换过程是不可观察的,即隐蔽的,可观察事件的随机过程是隐蔽的状态转换过程的随机函数。
可以用下面的图6-5说明隐马尔可夫模型的基本原理。
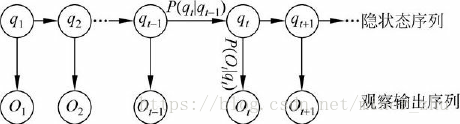
我们可以通过如下例子来说明HMM的含义。假定一暗室中有N个口袋,每个口袋中有M种不同颜色的球。一个实验员根据某一概率分布随机地选取一个初始口袋,从中根据不同颜色的球的概率分布,随机地取出一个球,并向室外的人报告该球的颜色。然后,再根据口袋的概率分布选择另一个口袋,根据不同颜色的球的概率分布从中随机选择另外一个球。重复进行这个过程。对于暗室外边的人来说,可观察的过程只是不同颜色的球的序列,而口袋的序列是不可观察的。在这个过程中,每个口袋对应于HMM中的状态,球的颜色对应于HMM中状态的输出符号,从一个口袋转向另一个口袋对应于状态转换,从口袋中取出球的颜色对应于从一个状态输出的观察符号。
通过上例可以看出,一个HMM由如下几个部分组成:
(1) 模型中状态的数目N(上例中口袋的数目);
(2) 从每个状态可能输出的不同符号的数目M(上例中球的不同颜色的数目);
(3) 状态转移概率矩阵A={aij}(aij为实验员从一个口袋(状态si)转向另一个口袋(sj)取球的概率)
(4) 从状态sj观察到符号vk的概率分布矩阵B={bj(k)}(bj(k)为实验员从第j个口袋中取出第k种颜色的球的概率)
(5) 初始状态概率分布π={πi}
一般地,一个HMM记为一个五元组μ=(S,K,A,B,π),其中,S为状态的集合,K为输出符号的集合,π,A和B分别是初始状态的概率分布、状态转移概率和符号发射概率。为了简单,有时也将其记为三元组μ=(A,B,π)。
当考虑潜在事件随机地生成表面事件时,HMM是非常有用的。假设给定模型μ=(A,B,π),那么,观察序列O=O1O2…OT可以由下面的步骤直接产生:
(1) 根据初始状态的概率分布πi选择一个初始状态q1=si;
(2) 设t=1;
(3) 根据状态si的输出概率分布bi(k)输出Ot=vk;
(4) 根据状态转移概率分布aij,将当前时刻t的状态转移到新的状态qt+1=sj;
(5) t=t+1,如果t<T,重复执行步骤(3)和(4),否则,结束算法。
HMM中有三个基本问题:
(1)估计问题:给定一个观察序列O=O1O2…OT和模型μ=(A,B,π),如何快速地计算出给定模型μ情况下,观察序列O的概率,即P(O|μ)?
(2)序列问题:给定一个观察序列O=O1O2…OT和模型μ=(A,B,π),如何快速有效地选择在一定意义下“最优”的状态序列Q=q1q2…qT,使得该状态序列“最好地解释”观察序列?
(3)训练问题或参数估计问题:给定一个观察序列O=O1O2…OT,如何根据最大似然估计来求模型的参数值?即如何调节模型μ=(A,B,π)的参数,使得P(O|μ)最大?
下面描述的前后向算法及参数估计将给出这三个问题的解决方案。
1.1 解决第一个问题:前向算法和后向算法
给定一个观察序列O=O1O2…OT和模型μ=(A,B,π),要快速地计算出给定模型μ情况下观察序列O的概率,即P(O|μ)。这就是解码(decoding)问题。
对于任意的状态序列Q=q1q2…qT,有
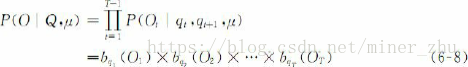
并且
由于
因此
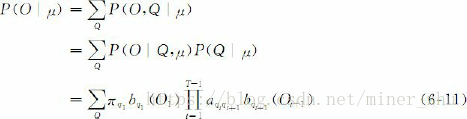
上述推导方式很直接,但面临一个很大的困难是,必须穷尽所有可能的状态序列。如果模型μ=(A,B,π)中有N个不同的状态,时间长度为T,那么,有N^T个可能的状态序列。这样,计算量会出现“指数爆炸”。当T很大时,几乎不可能有效地执行这个算法。为此,人们提出了前向算法或前向计算过程(forward procedure),利用动态规划的方法来解决这一问题,使“指数爆炸”问题可以在时间复杂度为O(N^2*T)的范围内解决。
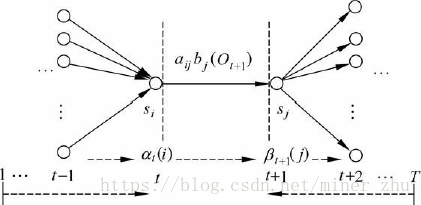
HMM中的动态规划问题一般用格架(trellis或lattice)的组织形式描述。对于一个在某一时间结束在一定状态的HMM,每一个格能够记录该HMM所有输出符号的概率,较长子路径的概率可以由较短子路径的概率计算出来,如图6-6所示
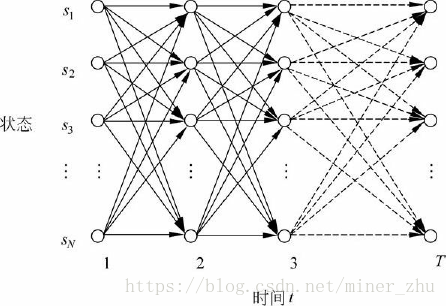
为了实现前向算法,需要定义一个前向变量αt(i)。
定义6-1 前向变量αt(i)是在时间t,HMM输出了序列O1O2…Ot,并且位于状态si的概率
前向算法的主要思想是,如果可以快速地计算前向变量αt(i),那么,就可以根据αt(i)计算出P(O|μ),因为P(O|μ)是在所有状态qT下观察到序列O=O1O2…OT的概率:
在前向算法中,采用动态规划的方法计算前向变量αt(i),其实现思想基于如下观察:在时间t+1的前向变量可以根据在时间t时的前向变量αt(1),αt(2),…,αt(N)的值来归纳计算:
在格架结构中,αt+1(j)存放在(sj,t+1)处的结点上,表示在已知观察序列O1O2…OtOt+1的情况下,从时间t到达下一个时间t+1时状态为sj的概率。图6-7描述了式(6-14)的归纳关系。
从初始时间开始到t+1,HMM到达状态sj,并输出观察序列O1O2…Ot+1的过程可以分解为以下两个步骤:
(1) 从初始时间开始到时间t,HMM到达状态si,并输出观察序列O1O2…Ot;
(2) 从状态si转移到状态sj,并在状态sj输出Ot+1。
这里si可以是HMM的任意状态。根据前向变量αt(i)的定义,从某一个状态si出发完成第一步的概率就是αt(i),而实现第二步的概率为aij×bj(Ot+1)。因此,从初始时间到t+1整个过程的概率为:αt(i) ×aij×bj(Ot+1)。由于HMM可以从不同的si转移到sj,一共有N个不同的状态,因此,得到了式(6-14)。
根据式(6-14)给出的归纳关系,可以按时间顺序和状态顺序依次计算前向变量α1(x),α2(x),…,αT(x)(x为HMM的状态变量)。由此,得到如下前向算法。
算法6-1 前向算法(forward procedure)
步1 初始化:α1(i)=πibi(O1), 1≤i≤N
步2 归纳计算:
步3 求和终结:
在初始化步骤中,πi是初始状态si的概率,bi(O1)是在si状态输出O1的概率,那么,πibi(O1)就是在时刻t=1时,HMM在si状态输出序列O1的概率,即前向变量α1(i)。一共有N个状态,因此,需要初始化N个前向变量α1(1),α1(2),…,α1(N)。
现在我们来分析前向算法的时间复杂性。由于每计算一个αt(i)必须考虑t-1时的所有N个状态转移到状态si的可能性,其时间复杂性为O(N),那么,对应每个时间t,要计算N个前向变量,αt(1), αt(2),…,αt(N),因此,时间复杂性为O(N)×N=O(N2)。因而,在1,2,…,T整个过程中,前向算法的总时间复杂性为O(N2T)。
对于求解HMM中的第一个问题,即在给定一个观察序列O=O1O2…OT和模型μ=(A,B,π)情况下,快速计算P(O|μ)的问题还可以采用另外一种实现方法,即后向算法。
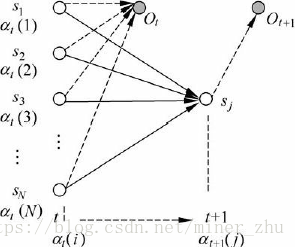
定义6-2 后向变量βt(i)是在给定了模型μ=(A,B,π),并且在时间t状态为si的条件下,HMM输出观察序列Ot+2…OT的概率:
与计算前向变量一样,可以用动态规划的算法计算后向变量。类似地,在时间t状态为si的条件下,HMM输出观察序列Ot+1Ot+2…OT的过程可以分解为以下两个步骤:
(1) 从时间t到时间t+1,HMM由状态si到状态sj,并从sj输出Ot+1;
(2) 在时间t+1的状态为sj的条件下,HMM输出观察序列Ot+2…OT。
第一步中输出Ot+1的概率为:aij×bj(Ot+1);第二步中根据后向变量的定义,HMM输出观察序列为Ot+2…OT的概率就是后向变量βt+1(j)。于是,得到如下归纳关系:
式(6-16)的归纳关系可以由图6-8来描述。
根据后向变量的归纳关系,按T,T-1,…,2,1顺序依次计算βT(x),βT-1(x),…,β1(x)(x为HMM的状态),就可以得到整个观察序列O=O1O2…OT的概率。下面的后向算法用于实现这个归纳计算的过程。
算法6-2 后向算法(backward procedure)
步1 初始化:βT(i)=1,1≤i≤N
步2 归纳计算:
步3 求和终结:
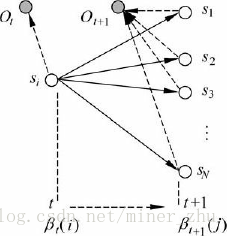
类似于前向算法的分析,可知后向算法的时间复杂度也是O(N2T)。更一般地,实际上我们可以采用前向算法和后向算法相结合的方法来计算观察序列的概率:
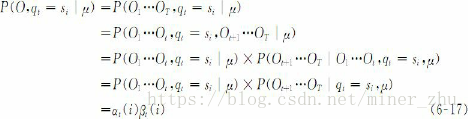
因此
1.2 解决第二个问题:维特比算法
维特比(Viterbi)算法用于求解HMM中的第二个问题,即给定一个观察序列O=O1O2…OT和模型μ=(A,B,π),如何快速有效地选择在一定意义下“最优”的状态序列Q=q1q2…qT,使得该状态序列“最好地解释”观察序列。这个问题的答案并不是唯一的,因为它取决于对“最优状态序列”的理解。
一种理解是,使该状态序列中每一个状态都单独地具有最大概率,即要使得:最大
根据贝叶斯公式,有
参考式(6-17)和式(6-18),并且P(qt=si,O|μ)=P(O,qt=si|μ),因此

有了γt(i),那么,在时间t的最优状态为
根据这种对“最优状态序列”的理解,如果只考虑使每个状态的出现都单独达到最大概率,而忽略了状态序列中两个状态之间的关系,很可能导致两个状态之间的转移概率为0,即=0。那么,在这种情况下,所谓的“最优状态序列”根本就不是合法的序列。
因此,我们常常采用另一种对“最优状态序列”的理解:在给定模型μ和观察序列O的条件下,使条件概率P(Q|O,μ)最大的状态序列。即
这种理解避免了前一种理解引起的“断序”的问题。根据这种理解,优化的不是状态序列中的单个状态,而是整个状态序列,不合法的状态序列的概率为0,因此,不可能被选为最优状态序列。
维特比算法运用动态规划的搜索算法求解这种最优状态序列。为了实现这种搜索,首先定义一个维特比变量δt(i)。
定义6-3 维特比变量δt(i)是在时间t时,HMM沿着某一条路径到达状态si,并输出观察序列O1O2…Ot的最大概率:
与前向变量类似,δt(i)有如下递归关系:
这种递归关系使我们能够运用动态规划搜索技术。为了记录在时间t时,HMM通过哪一条概率最大的路径到达状态si,维特比算法设置了另外一个变量ψt(i)用于路径记忆,让ψt(i)记录该路径上状态si的前一个(在时间t-1的)状态。根据这种思路,给出如下维特比算法。
算法6-3 维特比算法(Viterbi algorithm)
步1 初始化:
步2 归纳计算:
步3 求和终结:
步4 路径(状态序列)回溯:
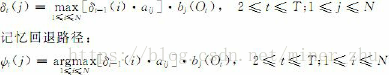
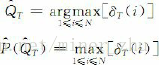
维特比算法的时间复杂性与前向算法、后向算法的时间复杂性一样,也是O(N2T)。
在实际应用中,往往不只是搜索一个最优状态序列,而是搜索n个最佳(n-best)路径,因此,在格架的每个结点上常常需要记录m个最佳(m-best, m<n)状态。
1.3 解决第三个问题:参数估计
参数估计问题是HMM面临的第三个问题,即给定一个观察序列O=O1O2…OT,如何调节模型μ=(A,B,π)的参数,使得P(O|μ)最大化:
模型的参数是指构成μ的πi,aij,bj(k)。最大似然估计方法可以作为HMM参数估计的一种选择。如果产生观察序列O的状态序列Q=q1q2…qT已知,根据最大似然估计,HMM的参数可以通过如下公式计算:

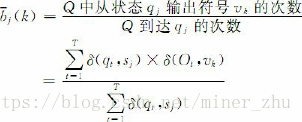
其中,δ(x, y)为克罗奈克(Kronecker)函数,当x=y时,δ(x, y)=1;否则,δ(x, y)=0。vk是HMM输出符号集中的第k个符号。
但实际上,由于HMM中的状态序列Q是观察不到的(隐变量),因此,这种最大似然估计的方法不可行。所幸的是,期望最大化(expectation maximization, EM)算法可以用于含有隐变量的统计模型的参数最大似然估计。其基本思想是,初始时随机地给模型的参数赋值,该赋值遵循模型对参数的限制,例如,从某一状态出发的所有转移概率的和为1。给模型参数赋初值以后,得到模型μ0,然后,根据μ0可以得到模型中隐变量的期望值。例如,从μ0得到从某一状态转移到另一状态的期望次数,用期望次数来替代式(6-23)中的实际次数,这样可以得到模型参数的新估计值,由此得到新的模型μ1。从μ1又可以得到模型中隐变量的期望值,然后,重新估计模型的参数,执行这个迭代过程,直到参数收敛于最大似然估计值。
这种迭代爬山算法可以局部地使P(O|μ)最大化。Baum-Welch算法或称前向后向算法(forward-backward algorithm)用于具体实现这种EM方法。下面我们介绍这种算法。
给定HMM的参数μ和观察序列O=O1O2…OT,在时间t位于状态si,时间t+1位于状态sj的概率ξt(i,j)=P(qt=si,qt+1=sj|O,μ)(1≤t≤T,1≤i, j≤N)可以由下面的公式计算获得:
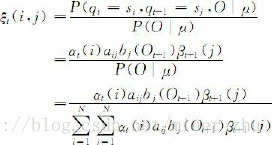
图6-9给出了式(6-24)所表达的前向变量αt(i)、后向变量βt+1(j)与概率ξt(i, j)之间的关系。
给定HMM μ和观察序列O=O1O2…OT,在时间t位于状态si的概率γt(i)为
由此,μ的参数可以由下面的公式重新估计:

根据上述思路,给出如下前向后向算法。
算法6-4 前向后向算法(forward-backward algorithm)
步1 初始化:随机地给参数πi,aij,bj(k)赋值,使其满足如下约束:
由此得到模型μ0。令i=0,执行下面的EM估计。
步2 EM计算:
E-步骤:由模型μi根据式(6-24)和式(6-25)计算期望值ξt(i, j)和γt(i);
M-步骤:用E-步骤得到的期望值,根据式(6-26)、(6-27)和(6-28)重新估计参数πi,aij,bj(k)的值,得到模型μi+1。
步3 循环计算:
令i=i+1。重复执行EM计算,直到πi,aij,bj(k)收敛。
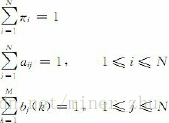
HMM在自然语言处理研究中有着非常广泛的应用。需要提醒的是,除了上述讨论的理论问题以外,在实际应用中还有若干实现技术上的问题需要注意。例如,多个概率连乘引起的浮点数下溢问题。在Viterbi算法中只涉及乘法运算和求最大值问题,因此,可以对概率相乘的算式取对数运算,使乘法运算变成加法运算,这样一方面避免了浮点数下溢的问题,另一方面,提高了运算速度。在前向后向算法中,也经常采用如下对数运算的方法判断参数πi,aij,bj(k)是否收敛:|log P(O|μi+1)-log P(O|μi)|<ε其中,ε为一个足够小的实数值。但是,在前向后向算法中执行EM计算时有加法运算,这就使得EM计算中无法采用对数运算,在这种情况下,可以设置一个辅助的比例系数,将概率值乘以这个比例系数以放大概率值,避免浮点数下溢。在每次迭代结束重新估计参数值时,再将比例系数取消。