隐马尔可夫模型
(Hidden Markov Model,HMM)
以下来源于_作者 :skyme 地址:http://www.cnblogs.com/skyme/p/4651331.html
隐马尔可夫模型(Hidden Markov Model,HMM)是统计模型,它用来描述一个含有隐含未知参数的马尔可夫过程。其难点是从可观察的参数中确定该过程的隐含参数。然后利用这些参数来作进一步的分析,例如模式识别。
是在被建模的系统被认为是一个马尔可夫过程与未观测到的(隐藏的)的状态的统计马尔可夫模型。
下面用一个简单的例子来阐述:
假设我手里有三个不同的骰子。第一个骰子是我们平常见的骰子(称这个骰子为D6),6个面,每个面(1,2,3,4,5,6)出现的概率是1/6。第二个骰子是个四面体(称这个骰子为D4),每个面(1,2,3,4)出现的概率是1/4。第三个骰子有八个面(称这个骰子为D8),每个面(1,2,3,4,5,6,7,8)出现的概率是1/8。
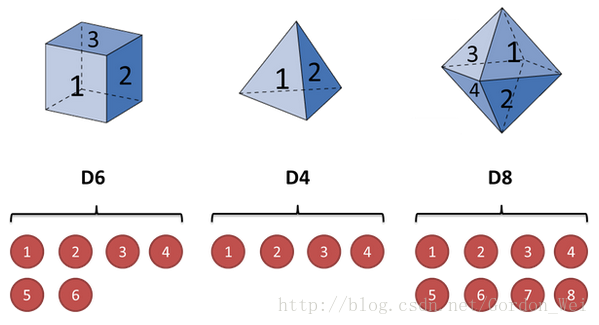
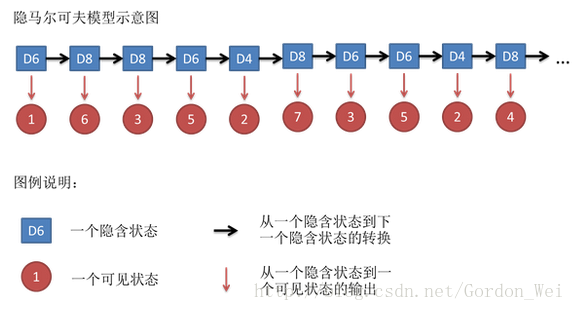
假设我们开始掷骰子,我们先从三个骰子里挑一个,挑到每一个骰子的概率都是1/3。然后我们掷骰子,得到一个数字,1,2,3,4,5,6,7,8中的一个。不停的重复上述过程,我们会得到一串数字,每个数字都是1,2,3,4,5,6,7,8中的一个。例如我们可能得到这么一串数字(掷骰子10次):1 6 3 5 2 7 3 5 2 4
这串数字叫做可见状态链。但是在隐马尔可夫模型中,我们不仅仅有这么一串可见状态链,还有一串隐含状态链。在这个例子里,这串隐含状态链就是你用的骰子的序列。比如,隐含状态链有可能是:D6 D8 D8 D6 D4 D8 D6 D6 D4 D8
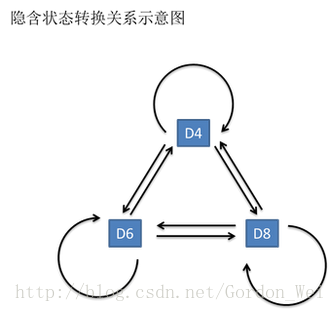
一般来说,HMM中说到的马尔可夫链其实是指隐含状态链,因为隐含状态(骰子)之间存在转换概率(transition probability)。在我们这个例子里,D6的下一个状态是D4,D6,D8的概率都是1/3。D4,D8的下一个状态是D4,D6,D8的转换概率也都一样是1/3。这样设定是为了最开始容易说清楚,但是我们其实是可以随意设定转换概率的。比如,我们可以这样定义,D6后面不能接D4,D6后面是D6的概率是0.9,是D8的概率是0.1。这样就是一个新的HMM。
同样的,尽管可见状态之间没有转换概率,但是隐含状态和可见状态之间有一个概率叫做输出概率(emission probability)。就我们的例子来说,六面骰(D6)产生1的输出概率是1/6。产生2,3,4,5,6的概率也都是1/6。我们同样可以对输出概率进行其他定义。比如,我有一个被赌场动过手脚的六面骰子,掷出来是1的概率更大,是1/2,掷出来是2,3,4,5,6的概率是1/10。
其实对于HMM来说,如果提前知道所有隐含状态之间的转换概率和所有隐含状态到所有可见状态之间的输出概率,做模拟是相当容易的。但是应用HMM模型时候呢,往往是缺失了一部分信息的,有时候你知道骰子有几种,每种骰子是什么,但是不知道掷出来的骰子序列;有时候你只是看到了很多次掷骰子的结果,剩下的什么都不知道。如果应用算法去估计这些缺失的信息,就成了一个很重要的问题。这些算法我会在下面详细讲。
×××××××××××××××××××××××××××××××××××××××××××××××××××××××××
如果你只想看一个简单易懂的例子,就不需要往下看了。
×××××××××××××××××××××××××××××××××××××××××××××××××××××××
说两句废话,答主认为呢,要了解一个算法,要做到以下两点:会其意,知其形。答主回答的,其实主要是第一点。但是这一点呢,恰恰是最重要,而且很多书上不会讲的。正如你在追一个姑娘,姑娘对你说“你什么都没做错!”你要是只看姑娘的表达形式呢,认为自己什么都没做错,显然就理解错了。你要理会姑娘的意思,“你赶紧给我道歉!”这样当你看到对应的表达形式呢,赶紧认错,跪地求饶就对了。数学也是一样,你要是不理解意思,光看公式,往往一头雾水。不过呢,数学的表达顶多也就是晦涩了点,姑娘的表达呢,有的时候就完全和本意相反。所以答主一直认为理解姑娘比理解数学难多了。
回到正题,和HMM模型相关的算法主要分为三类,分别解决三种问题:
1)知道骰子有几种(隐含状态数量),每种骰子是什么(转换概率),根据掷骰子掷出的结果(可见状态链),我想知道每次掷出来的都是哪种骰子(隐含状态链)。
这个问题呢,在语音识别领域呢,叫做解码问题。这个问题其实有两种解法,会给出两个不同的答案。每个答案都对,只不过这些答案的意义不一样。第一种解法求最大似然状态路径,说通俗点呢,就是我求一串骰子序列,这串骰子序列产生观测结果的概率最大。第二种解法呢,就不是求一组骰子序列了,而是求每次掷出的骰子分别是某种骰子的概率。比如说我看到结果后,我可以求得第一次掷骰子是D4的概率是0.5,D6的概率是0.3,D8的概率是0.2.第一种解法我会在下面说到,但是第二种解法我就不写在这里了,如果大家有兴趣,我们另开一个问题继续写吧。
2)还是知道骰子有几种(隐含状态数量),每种骰子是什么(转换概率),根据掷骰子掷出的结果(可见状态链),我想知道掷出这个结果的概率。
看似这个问题意义不大,因为你掷出来的结果很多时候都对应了一个比较大的概率。问这个问题的目的呢,其实是检测观察到的结果和已知的模型是否吻合。如果很多次结果都对应了比较小的概率,那么就说明我们已知的模型很有可能是错的,有人偷偷把我们的骰子給换了。
3)知道骰子有几种(隐含状态数量),不知道每种骰子是什么(转换概率),观测到很多次掷骰子的结果(可见状态链),我想反推出每种骰子是什么(转换概率)。
这个问题很重要,因为这是最常见的情况。很多时候我们只有可见结果,不知道HMM模型里的参数,我们需要从可见结果估计出这些参数,这是建模的一个必要步骤。
问题阐述完了,下面就开始说解法。(0号问题在上面没有提,只是作为解决上述问题的一个辅助)
0.一个简单问题
其实这个问题实用价值不高。由于对下面较难的问题有帮助,所以先在这里提一下。
知道骰子有几种,每种骰子是什么,每次掷的都是什么骰子,根据掷骰子掷出的结果,求产生这个结果的概率。
解法无非就是概率相乘:
1.看见不可见的,破解骰子序列
这里我说的是第一种解法,解最大似然路径问题。
举例来说,我知道我有三个骰子,六面骰,四面骰,八面骰。我也知道我掷了十次的结果(1 6 3 5 2 7 3 5 2 4),我不知道每次用了那种骰子,我想知道最有可能的骰子序列。
其实最简单而暴力的方法就是穷举所有可能的骰子序列,然后依照第零个问题的解法把每个序列对应的概率算出来。然后我们从里面把对应最大概率的序列挑出来就行了。如果马尔可夫链不长,当然可行。如果长的话,穷举的数量太大,就很难完成了。
另外一种很有名的算法叫做Viterbi algorithm. 要理解这个算法,我们先看几个简单的列子。
首先,如果我们只掷一次骰子:
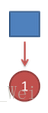
看到结果为1.对应的最大概率骰子序列就是D4,因为D4产生1的概率是1/4,高于1/6和1/8.
把这个情况拓展,我们掷两次骰子:
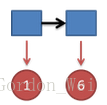
结果为1,6.这时问题变得复杂起来,我们要计算三个值,分别是第二个骰子是D6,D4,D8的最大概率。显然,要取到最大概率,第一个骰子必须为D4。这时,第二个骰子取到D6的最大概率是
同样的,我们可以计算第二个骰子是D4或D8时的最大概率。我们发现,第二个骰子取到D6的概率最大。而使这个概率最大时,第一个骰子为D4。所以最大概率骰子序列就是D4 D6。
继续拓展,我们掷三次骰子:
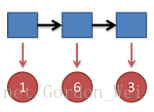
同样,我们计算第三个骰子分别是D6,D4,D8的最大概率。我们再次发现,要取到最大概率,第二个骰子必须为D6。这时,第三个骰子取到D4的最大概率是
同上,我们可以计算第三个骰子是D6或D8时的最大概率。我们发现,第三个骰子取到D4的概率最大。而使这个概率最大时,第二个骰子为D6,第一个骰子为D4。所以最大概率骰子序列就是D4 D6 D4。
写到这里,大家应该看出点规律了。既然掷骰子一二三次可以算,掷多少次都可以以此类推。我们发现,我们要求最大概率骰子序列时要做这么几件事情。首先,不管序列多长,要从序列长度为1算起,算序列长度为1时取到每个骰子的最大概率。然后,逐渐增加长度,每增加一次长度,重新算一遍在这个长度下最后一个位置取到每个骰子的最大概率。因为上一个长度下的取到每个骰子的最大概率都算过了,重新计算的话其实不难。当我们算到最后一位时,就知道最后一位是哪个骰子的概率最大了。然后,我们要把对应这个最大概率的序列从后往前推出来。
2.谁动了我的骰子?
比如说你怀疑自己的六面骰被赌场动过手脚了,有可能被换成另一种六面骰,这种六面骰掷出来是1的概率更大,是1/2,掷出来是2,3,4,5,6的概率是1/10。你怎么办么?答案很简单,算一算正常的三个骰子掷出一段序列的概率,再算一算不正常的六面骰和另外两个正常骰子掷出这段序列的概率。如果前者比后者小,你就要小心了。
比如说掷骰子的结果是:
要算用正常的三个骰子掷出这个结果的概率,其实就是将所有可能情况的概率进行加和计算。同样,简单而暴力的方法就是把穷举所有的骰子序列,还是计算每个骰子序列对应的概率,但是这回,我们不挑最大值了,而是把所有算出来的概率相加,得到的总概率就是我们要求的结果。这个方法依然不能应用于太长的骰子序列(马尔可夫链)。
我们会应用一个和前一个问题类似的解法,只不过前一个问题关心的是概率最大值,这个问题关心的是概率之和。解决这个问题的算法叫做前向算法(forward algorithm)。
首先,如果我们只掷一次骰子:
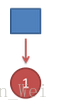
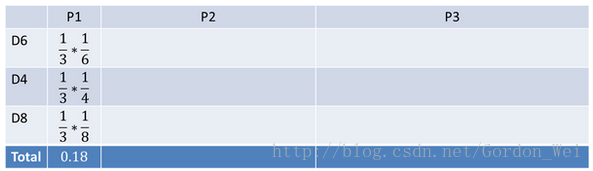
看到结果为1.产生这个结果的总概率可以按照如下计算,总概率为0.18:
把这个情况拓展,我们掷两次骰子:
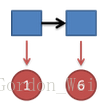
看到结果为1,6.产生这个结果的总概率可以按照如下计算,总概率为0.05:

继续拓展,我们掷三次骰子:
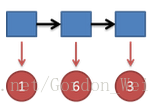
看到结果为1,6,3.产生这个结果的总概率可以按照如下计算,总概率为0.03:

同样的,我们一步一步的算,有多长算多长,再长的马尔可夫链总能算出来的。用同样的方法,也可以算出不正常的六面骰和另外两个正常骰子掷出这段序列的概率,然后我们比较一下这两个概率大小,就能知道你的骰子是不是被人换了。
Viterbi algorithm
HMM(隐马尔可夫模型)是用来描述隐含未知参数的统计模型,举一个经典的例子:一个东京的朋友每天根据天气{下雨,天晴}决定当天的活动{公园散步,购物,清理房间}中的一种,我每天只能在twitter上看到她发的推“啊,我前天公园散步、昨天购物、今天清理房间了!”,那么我可以根据她发的推特推断东京这三天的天气。在这个例子里,显状态是活动,隐状态是天气。
任何一个HMM都可以通过下列五元组来描述:
:param obs:观测序列
:param states:隐状态
:param start_p:初始概率(隐状态)
:param trans_p:转移概率(隐状态)
:param emit_p: 发射概率 (隐状态表现为显状态的概率
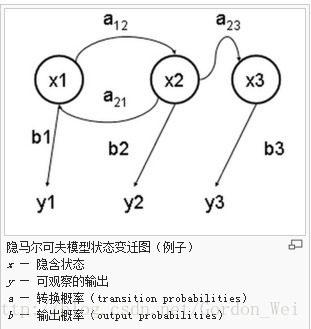
伪码如下:
states = ('Rainy', 'Sunny')
observations = ('walk', 'shop', 'clean')
start_probability = {'Rainy': 0.6, 'Sunny': 0.4}
transition_probability = {
'Rainy' : {'Rainy': 0.7, 'Sunny': 0.3},
'Sunny' : {'Rainy': 0.4, 'Sunny': 0.6},
}
emission_probability = {
'Rainy' : {'walk': 0.1, 'shop': 0.4, 'clean': 0.5},
'Sunny' : {'walk': 0.6, 'shop': 0.3, 'clean': 0.1},
}求解最可能的天气
求解最可能的隐状态序列是HMM的三个典型问题之一,通常用维特比算法解决。维特比算法就是求解HMM上的最短路径(-log(prob),也即是最大概率)的算法。
稍微用中文讲讲思路,很明显,第一天天晴还是下雨可以算出来:
定义V[时间][今天天气] = 概率,注意今天天气指的是,前几天的天气都确定下来了(概率最大)今天天气是X的概率,这里的概率就是一个累乘的概率了。
因为第一天我的朋友去散步了,所以第一天下雨的概率V[第一天][下雨] = 初始概率[下雨] * 发射概率[下雨][散步] = 0.6 *0.1 = 0.06,同理可得V[第一天][天晴] = 0.24 。从直觉上来看,因为第一天朋友出门了,她一般喜欢在天晴的时候散步,所以第一天天晴的概率比较大,数字与直觉统一了。
从第二天开始,对于每种天气Y,都有前一天天气是X的概率 * X转移到Y的概率 * Y天气下朋友进行这天这种活动的概率。因为前一天天气X有两种可能,所以Y的概率有两个,选取其中较大一个作为V[第二天][天气Y]的概率,同时将今天的天气加入到结果序列中
比较V[最后一天][下雨]和[最后一天][天晴]的概率,找出较大的哪一个对应的序列,就是最终结果。
算法的代码可以在github上看到,地址为:
https://github.com/hankcs/Viterbi
运行完成后根据Viterbi得到结果:
Sunny Rainy Rainy
Viterbi被广泛应用到分词,词性标注等应用场景。
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
以下来源于:知乎 作者 :傅睿卿
地址:https://www.zhihu.com/question/20962240/answer/34202445
粗略的看了一遍,觉得必须要说两句,之前几乎所有人答案都是在没有具体应用方法的背景下讲理论,在实际应用中反而会让人迷糊,HMM用途大多数情况下不会是求隐变量的场合,隐变量具体是什么在很多的学习、分类问题下都是无关紧要的!
—————以下正题—————-
首先说马尔科夫,这是基础,没有这个一切都是胡闹,之前很多答案并没有过多的顾及马尔科夫模型的问题,答案只能说是个隐概率模型。马尔科夫模型描述的是当前状态只和前一状态相关的情况。
【先打比方】打麻将坐庄,比如现在是东风庄,那么(理想情况下)下把有75%的概率是北风(被胡牌),25%还是东风(自己胡牌),而跟上一把是不是东风庄没有任何关系。这就是一个标准的马尔科夫过程,(考虑心里因素时也可能不是,这里不谈)
【再说不恰当的案例】而最多举得天气的例子,就不是很合适,第一,明天下雨的概率现实中绝对不仅依赖于今天是不是晴天,这在建模时需要首先考虑模型的精度,注意,概率模型是以[你所认知的]世界为基础的,在某个问题下,你可以认为全人类得癌症的概率是多少多少,在其他问题下,你可能认为男性女性得癌症的概率分别是多少,这取决于模型的精度和你掌握的信息来定。绝大部分问题不是天生就是马尔科夫的,首先,夏天冬天不一样,梅雨季节更不一样,用术语说,这是时变的,当然你可以在你的模型中忽略这些,”假装”他是马尔科夫的。
【再说具体点】作为马尔科夫的过程,就和HMM应用会扯上关系的问题来说,要注意,任何时候,当系统出于某一状态时(也可以是以某一概率处于某些状态),下周期处于状态的概率要是确定的(比如刚说的75%,和25%,数值可以不知道,但一定是不会变的某个值),而不依赖于之前的状态(前天)或系统的其他状态(冬季)。
【如果数学一些】由于任何状态迁移到其他状态的概率是确定的,所以我们如果知道本周期的概率分布,就可以求出下周期的分布,方法用中学时代的描述就是分类讨论,而本科阶段开始就用矩阵乘简单处理,这个就不多说了。要注意,能够写成矩阵(也就说概率是确定的)很重要。如果不是,那么就是其他问题了,比如半隐马尔科夫,如果有时间我下面会说,没有的话先坑着。
—————-开始HMM,之后讨论有什么用,因为你看完这段肯定不知道怎么用———————–
HMM针对的问题,必须是一个上面规范定义的过程,为什么?因为数学的求解能力是非常有限的,或许看似简单的变化,导致的可能是不可接受的计算量,
【先说定义】所谓的隐,就是看不见的意思。借用一句有切身感觉的话说”当看到方便面中油包变成固体的时候,宅男知道,冬天来了“。这里的季节(冬天)就是隐藏起来的变量,宅男(观察者)不出屋,所以看不到天气,他只可以看到方便面调料(这叫观测)。所谓的HMM,用来描述一个我们看不到系统状态,只能看到观测(但观测和状态之间有确定性的概率关系)的状态。
【需要强调的】第一就是刚刚的最后一句,观测和系统的状态之间必须有确定的概率关系,这个关系和系统的运行时间,之前的观测,之前的状态等等都不能有任何关系。也就是任何时候我看到固体的调料包,就代表(90%冬天,10%刚刚春天)。第二就是刚说到的,HMM是用来描述这样一个系统使用的工具,就好像我们可以用矩阵代表一个线性方程组一样。我们可以用HMM模型来表示一个这样的系统,定义它的量包括:(1)每个观测下,系统处于某状态的概率,共计观测类型系统状态类型 个,(由于概率总和为1,有效的量少观测类型个)。(2)本周期系统处于某状态时,下周期各状态的概率分布(就是刚刚马尔科夫中的那个矩阵),数量为 状态类型 状态类型 个(同上,有效的略少)。(3)系统的初始状态分布,就是第一周期时候系统是什么样子,这样我们就可以计算出每周期的概率了。这个值一共有 状态类型个(有效的少一个)
—————————-下面是怎么用HMM—————————–
刚刚已经说过什么是HMM了,就和高斯分布一样,HMM是描述系统分布的一种手段,那我们怎么用呢?(这里我们只谈用法思路,计算办法网上很多,思路和模型本身关系不是那么密切,就是算了)
【最常见的使用方法】我们说使用HMM时,一般时在解决这样的一个问题:当我有一个观测序列(样本)时,它和我所有已经知道的HMM模型哪个最匹配。我们通常会为每个我们预计要检测的东西训练一个HMM(用该类的大量样本)。
【沿用刚刚的例子】刚在举例子的时候没想太周全,这里就将就看吧。如果说我们可以用一个HMM描述宅男看方便面的问题的话,那么我们最可能干的事情就是,通过观察方便面油包状态,估计宅男所处的城市。是不是有点意外?居然不是看季节?其实HMM使用时最容易犯的错误就是弄混隐变量和我们的分类结果的关系了,关系就是没有关系!我们首先选取了世界各地宅男看到的油包状态,比如北京的1万个宅男,深圳的1万个,北冰洋的1万个宅男各3年的观察,作为样本,这时,我们系统一共涉及到了这样几个信息:(1)我们预计有3个HMM模型,分别是北京,深圳,北冰洋(2)我们只有2个观测结果,即油包是固态还是液态(3)我们的隐变量通常并不明确,但本例中我们估计系统状态可能是4季,所以我们设定4个隐变量,注意:这4个就代表四季在实际应用中完全就是猜的,而且不见得训练的结果就是四季!
【解决例子中的问题】为了完成这个工作,我们要干以下几步:(1)分别利用每个地区的1万个样本,各自训练一个HMM,方法可参考网上各种文章。(2)在实际判断一个宅男的地理位置时,拿到一个观察序列,然后分别计算北京、深圳、北冰洋的HMM能够得到这个观测序列的概率。概率最大的,就是该宅男的所在提。
————————————–最后多说几句————————————
HMM的求解是一个非常麻烦的事情,可以看成是一个EM迭代的过程,而且求解的变量非常多,这就直接导致了一些约束:(1)观测的种类不能很多,尤其不能是连续过程(2)系统隐状态也不宜太多(3)要检测的目标,也就是HMM的数量,倒不是大问题,因为这是线性增长的,多一倍求解时间只多一倍,一般都能接受