隐马尔可夫模型
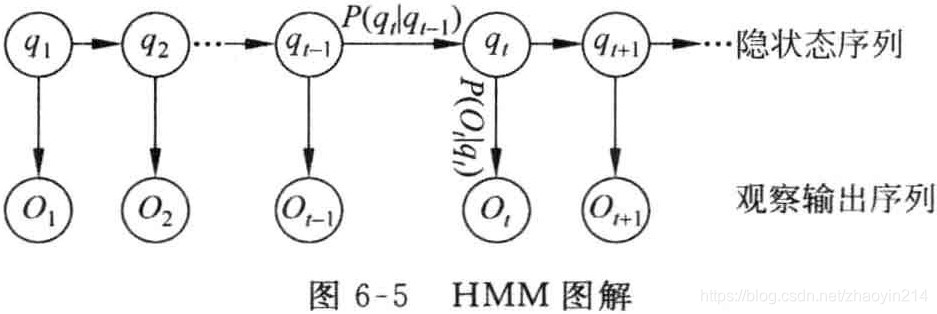
在马尔可夫模型中,每个状态代表了一个可观察的事件,因此,马尔可夫模型又称作可视马尔可夫模型(visible Markov model,VMM)。隐马尔可夫模型(HMM)中,模型所经过的状态序列未知,只知道状态的概率函数,即观察到的事件是状态的随机函数,因此,该模型是一个双重随机过程。其中,模型的状态转换过程是不可观察的(隐蔽的),可观察事件的随机过程是隐蔽状态转换过程的随机函数。

HMM模型可表示为一个五元组
μ=(S,K,A,B,π),其中
S为状态的集合,
K为输出符号的集合,
π、
A和
B分别表示初始状态的概率分布、状态转移概率和符号发射概率。有时也将其简记为三元组
μ=(A,B,π)。
-
模型中的状态数
N=∣S∣;
-
每个状态可能输出的符号数
M=∣K∣;
-
状态转移概率矩阵
A={aij},其中
aij=P(qt=sj∣qt−1=si)aij≥0j=1∑Naij=11≤i,j≤N(6-6)
- 从状态
sj观察到符号
vk的概率分布矩阵
B={bj(k)},其中
bj(k)=P(Ot=vk∣qt=sj)bj(k)≥0k=1∑Mbj(k)=11≤j≤N, 1≤k≤M(6-7)
观察符号的概率又称符号发射概率(symbol emission probability);
- 初始状态概率分布
π={πi},其中,
πi=P(q1=si)πi≥0i=1∑Nπi=11≤i≤N(6-8)
考虑潜在事件随机地生成表面事件,假设给定HMM模型
μ=(A,B,π),则观察序列
O=O1O2⋯OT可以由以下步骤产生:
-
根据初始状态的概率分布
π,选择一个初始状态
q1=si;
-
设
t=1;
-
根据状态
si的输出概率分布
bi(k)输出
Ot=vk;
-
根据状态转移概率分布
aij,将当前时刻
t的状态转移到新的状态
qt+1=sj;
-
t=t+1,如果
t<T,重复执行步骤(3)、(4),否则,结束算法。
HMM的三个基本问题:
-
估计问题:给定观察序列
O=O1O2⋯OT和模型
μ=(A,B,π),计算观察序列
O的概率,即
P(O∣μ);
-
序列问题:给定观察序列
O=O1O2⋯OT和模型
μ=(A,B,π),选择在一定意义下“最优”的状态序列
Q=q1q2⋯qT,使得该状态序列“最好地解释”观察序列;
-
训练问题(参数估计问题):给定一个观察序列
O=O1O2⋯OT,根据最大似然估计计算模型参数值,即计算使
P(O∣μ)最大时,模型
μ=(A,B,π)的参数。
三个基本问题可通过前后向算法及参数估计解决。