在之前格物汇的文章中,我们介绍了特征构建的几种常用方法。特征构建是一种升维操作,针对特征解释能力不足,可以通过特征构建的方法来增加特征解释力,从而提升模型效果。随着近几年大数据技术的普及,我们可以获取海量数据,但是这些海量数据带给我们更多信息的同时,也带来了更多的噪音和异常数据。如何降维去噪成为很多企业关注的焦点,今天我们将介绍特征工程中的一种降维方法——特征选择。
什么是特征选择
特征选择( Feature Selection )也称特征子集选择( FeatureSubset Selection , FSS ),或属性选择( Attribute Selection )。是指从已有的N个特征(Feature)中选择M个特征使得系统的特定指标最优化。
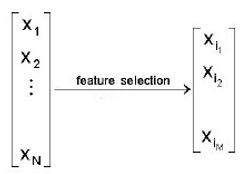
特征选择主要有两个功能:
减少特征数量、降维,使模型泛化能力更强,减少过拟合
增强对特征和特征值之间的理解
特征选择的流程
特征选择的目标是寻找一个能够有效识别目标的最小特征子集。寻找的一般流程可用下图表示:
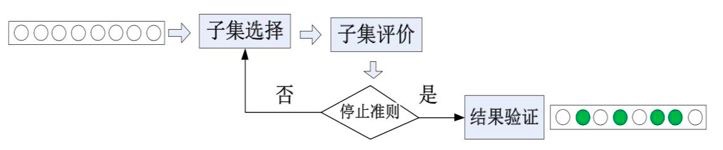
一般来说,通过枚举来对特征子集进行选择是一个比较费时的步骤,所以应使用一些策略来进行特征选择,通常来说,我们会从两个方面考虑来选择特征:
特征是否发散:
如果一个特征不发散,例如方差接近于0,也就是说样本在这个特征上基本上没有差异,这个特征对于样本的区分并没有什么用。
特征与目标的相关性:
这点比较显见,与目标相关性高的特征,应当优选选择。除方差法外,本文介绍的其他方法均从相关性考虑。
根据特征选择的形式又可以将特征选择方法分为3种:
Filter
Wrapper
Embedded
特征选择的方法
01、Filter
过滤法,按照发散性或者相关性对各个特征进行评分,设定阈值或者待选择阈值的个数,选择特征。
评分指标有:
方差:评价指标的离散程度,越离散说明包含的信息越多。
相关性:衡量特征对目标的解释能力,相关系数越大说明解释能力越强。
卡方检验:检验定性自变量对定性因变量的相关性。
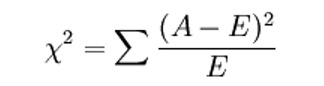
互信息:也是评价定性自变量对定性因变量的相关性的。
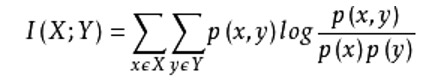
02、Wrapper
包装法,根据目标函数(通常是预测效果)评分,每次选择若干特征,或者排除若干特征,主要的方法是递归特征消除法。递归消除特征法使用一个基模型来进行多轮训练,每轮训练后,减少若干特征,或者新增若干特征,进行评估看新增的特征是否需要保留,剔除的特征是否需要还原。最后再基于新的特征集进行下一轮训练。
03、Embedded
嵌入法,先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据系数从大到小选择特征。类似于Filter方法,但是是通过训练来确定特征的优劣。
一般分为如下两大类:
基于惩罚项的特征选择法:
这个方法可以用线性回归模型来举例说明,我们在线性模型的目标函数中增加L1正则项(实际上这就是lasso模型)。由于该正则项的存在,某些与目标y不太相关的特征的系数将缩减至0,而保留的特征系数将相应调整,从而达到了对特征进行筛选的效果,L1正则项系数越大,筛选的力度也就越大。
基于树模型的特征选择法:
在我们之前的文章中介绍过随机森林,GDBT等等基于树的模型,他们均有一个特点就是模型可以计算出特征的重要性。决策树会优先将对预测目标y帮助最大的特征放在模型的顶端,因此根据这个效果我们计算得到特征的重要性,进而我们可以根据特征重要性对特征进行选择。
今天我们大致了解了如何给工业大数据降维去噪,进行特征选择,在后续文章中,我们将继续带大家了解特征工程的另一个内容——特征抽取,敬请期待。
本文作者:格创东智OT团队(转载请注明作者及来源)