目录:
1.什么是特征工程?
什么是特征工程?特征工程解决了什么问题?为什么特征工程对机器学习那么重要?怎么做好特征工程?带着这些问题,我们来看本文的内容。首先,以我的理解回答以上的问题,好让读者有个初步印象,后面,我将通过详细讲解和代码(Sklearn实现)带来直观的感受。特征工程(Feature Engineering)是将原始的数据转换为更好的表达问题本质特征的过程,使得这些特征运用到模型中能提高对不可见的数据的模型预测精度。目的是分解或和并数据,以便更好地表达问题的本质,提高模型的准确度。在工业界有一句话广泛流传:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。所以说特征工程在机器学习中有着至关重要的作用。在这我将特征工程分为四部分为读者进行讲解,分别为:数据预处理、特征工程、特征降维、特征不平衡处理。
2.数据预处理
通过数据预处理,我们能得到未经处理的特征,这时的特征可能有以下问题:
- 不属于同一量纲:即特征的规格不一样,不能够放在一起比较。无量纲化可以解决这一问题。
- 信息冗余:对于某些定量特征,其包含的有效信息为区间划分,例如学习成绩,假若只关心“及格”或不“及格”,那么需要将定量的考分,转换成“1”和“0”表示及格和未及格。二值化可以解决这一问题。
- 定性特征不能直接使用:某些机器学习算法和模型只能接受定量特征的输入,那么需要将定性特征转换为定量特征。最简单的方式是为每一种定性值指定一个定量值,但是这种方式过于灵活,增加了调参的工作。通常使用哑编码的方式将定性特征转换为定量特征:假设有N种定性值,则将这一个特征扩展为N种特征,当原始特征值为第i种定性值时,第i个扩展特征赋值为1,其他扩展特征赋值为0。哑编码的方式相比直接指定的方式,不用增加调参的工作,对于线性模型来说,使用哑编码后的特征可达到非线性的效果。
- 存在缺失值:缺失值需要补充。
- 信息利用率低:不同的机器学习算法和模型对数据中信息的利用是不同的,之前提到在线性模型中,使用对定性特征哑编码可以达到非线性的效果。类似地,对定量变量多项式化,或者进行其他的转换,都能达到非线性的效果。
2.1.缺失值处理
数据分析和数据挖掘中所提供的数据,永远不是完美的。很多特征,对于分析和建模来说意义非凡,所以一般在数据挖掘之中,常常会有重要的字段缺失值很多,然而我们又不想放弃特征,常常就处理缺失值,常用的方法有0-1填充,中值、均值、众数填充,算法填充等等。这是数据分析的重要步骤之一。
import numpy as np
from sklearn.impute import SimpleImputer
from sklearn.datasets import load_iris
# 人为的制造空值
X,y = load_iris(return_X_y=True)
X[0:2,1:] = np.nan
X[:5]
结果展示:

众数填充:
SimpleImputer(missing_values=np.nan,strategy="most_frequent").fit_transform(X)[:5] # 众数填充
# missing_values为要填充的对象,默认np.nan
# strategy 填充的策略,默认为均值,也可以为中值median,众数most_frequent,值或字符串constant(后面须有参数fill_value)

常数填充:
# 常数0填充
SimpleImputer(missing_values=np.nan,strategy='constant',fill_value=0).fit_transform(X)[:5]

2.2.数据的无量纲化
在机器学习算法实践中,我们往往有着将不同规格的数据转换到同一规格,或不同分布的数据转换到某个特定分布
的需求,这种需求统称为将数据“无量纲化”。譬如梯度和矩阵为核心的算法中,譬如逻辑回归,支持向量机,神经
网络,无量纲化可以加快求解速度;而在距离类模型,譬如K近邻,K-Means聚类中,无量纲化可以帮我们提升模
型精度。无量纲化包括中心化处理和缩放处理。中心化的本质是让所有记录减去一个固定值,即让数据样本数据平移到某个位置。缩放的本质是通过除以一个固定值,将数据固定在某个范围之中,取对数也算是一种缩放处理。
2.2.1.数据归一化preprocessing.MinMaxScaler
当数据(x)按照最小值中心化后,再按极差(最大值 - 最小值)缩放,数据移动了最小值个单位,并且会被收敛到[0,1]之间,而这个过程,就叫做数据归一化。
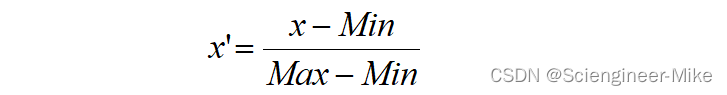
其中Max为样本的最大值,Min为样本的最小值。归一化代码如下:
from sklearn.datasets import load_iris
from sklearn.preprocessing import MinMaxScaler
X,y = load_iris(return_X_y=True)
MinMaxScaler().fit_transform(X)[:5]
归一化结果展示:

2.2.2.数据标准化preprocessing.StandardScaler
当数据(x)按均值(μ)中心化后,再按标准差(σ)缩放,数据就会服从为均值为0,方差为1的正态分布(即标准正态分布),而这个过程,就叫做数据标准化。
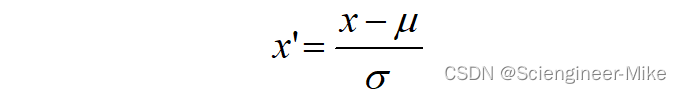
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
X,y = load_iris(return_X_y=True)
StandardScaler().fit_transform(X)[:5]
数据标准化结果展示:

2.3.处理分类型特征:编码和哑变量
在机器学习中,大多数算法,譬如逻辑回归,支持向量机SVM,k近邻算法等都只能够处理数值型数据,不能处理文字,在sklearn当中,除了专用来处理文字的算法,其他算法在fit的时候全部要求输入数组或矩阵,也不能够导入文字型数据。然而在现实中,许多标签和特征在数据收集完毕的时候,都不是以数字来表现的。比如说,学历的取值可以是[“小学”,“初中”,“高中”,“大学”],付费方式可能包含[“支付宝”,“现金”,“微信”]等等。在这种情况下,为了让数据适应算法和库,我们必须将数据进行编码,即是说,将文字型数据转换为数值型。
2.3.1.标签专用,能够将分类标签转换为分类数值preprocessing.LabelEncoder
LabelEncoder针对的对象为标签,因此输入的数据须为一维。
from sklearn.preprocessing import LabelEncoder
import numpy as np
label = np.array(["小学","初中","小学","高中","初中","初中","高中","高中"])
LabelEncoder().fit_transform(label)
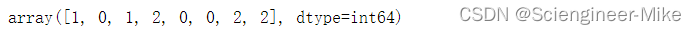
2.3.2.特征专用,能够将分类特征转换为分类数值preprocessing.OrdinalEncoder
from sklearn.preprocessing import OrdinalEncoder
import numpy as np
label = np.array([["小学","初中","小学","高中"],
["初中","初中","高中","高中"]])
OrdinalEncoder().fit_transform(label)

2.3.3.独热编码,创建哑变量preprocessing.OneHotEncoder
from sklearn.preprocessing import OneHotEncoder
import numpy as np
label = np.array([["小学"]
,["初中"]
,["小学"]
,["高中"]])
OneHotEncoder().fit_transform(label).toarray()

2.4.处理连续性特征:二值化与分段
2.4.1.二值化操作preprocessing.Binarizer
根据阈值将数据二值化(将特征值设置为0或1),用于处理连续型变量。大于阈值的值映射为1,而小于或等于阈值的值映射为0。
from sklearn.preprocessing import Binarizer
from sklearn.datasets import load_iris
X,y = load_iris(return_X_y=True)
X[:5]

Binarizer(threshold=3.5).fit_transform(X)[:5]

2.4.2.分段preprocessing.KBinsDiscretizer
这是将连续型变量划分为分类变量的类,能够将连续型变量排序后按顺序分箱后编码。总共包含三个重要参数:
n_bins代表每个特征中分箱的个数,默认为5;
encoder:默认onehot,onehot做哑变量,之后返回一个稀疏矩阵,每一列的一个特征代表一个类别;ordinal每个特征的每个箱都被编码为一个整数,返回每一列是一个特征;
strategy:用来定义箱宽的方式。uniform代表等宽分箱,quantile等位分箱,kmeans按聚类分箱。
代码解释:
from sklearn.datasets import load_iris
from sklearn.preprocessing import KBinsDiscretizer
X,y = load_iris(return_X_y=True)
X_ = X[:,1].reshape(-1,1)
X_[:10]

KBinsDiscretizer(n_bins=5,encode="onehot",strategy="uniform").fit_transform(X_)[:10].toarray()

KBinsDiscretizer(n_bins=5,encode="ordinal",strategy="uniform").fit_transform(X_)[:10]

3.特征选择
当数据预处理完成后,我们需要选择有意义的特征输入机器学习的算法和模型进行训练。通常来说,从两个方面考虑来选择特征:特征是否发散:如果一个特征不发散,例如方差接近于0,也就是说样本在这个特征上基本上没有差异,这个特征对于样本的区分并没有什么用。特征与目标的相关性:这点比较显见,与目标相关性高的特征,应当优选选择。
3.1.Filter过滤法
过滤方法通常用作预处理步骤,特征选择完全独立于任何机器学习算法。它是根据各种统计检验中的分数以及相关性的各项指标来选择特征。
3.1.1.方差过滤
我们设置方差的阈值为threshold=0.3,来筛选特征,筛选前特征数目为4,筛选后,特征数目为3.
from sklearn.feature_selection import VarianceThreshold
from sklearn.datasets import load_iris
X,y = load_iris(return_X_y=True)
VarianceThreshold(threshold=0.3).fit_transform(X)[:10]

3.1.2.相关性过滤(卡方、F检验、互信息法)
3.1.2.1.卡方过滤
卡方过滤是专门针对离散型标签(即分类问题)的相关性过滤。卡方检验类feature_selection.chi2计算每个非负特征和标签之间的卡方统计量,并依照卡方统计量由高到低为特征排名。再结合feature_selection.SelectKBest这个可以输入”评分标准“来选出前K个分数最高的特征的类,我们可以借此除去最可能独立于标签,与我们分类目的无关的特征。
from sklearn.feature_selection import SelectKBest,chi2
from sklearn.datasets import load_iris
X,y = load_iris(return_X_y=True)
SelectKBest(chi2,k=2).fit_transform(X,y)[:5]# 选择按照卡方统计量最高的两个特征

3.1.2.2.F检验
F检验,又称ANOVA,方差齐性检验,是用来捕捉每个特征与标签之间的线性关系的过滤方法。它即可以做回归也可以做分类,因此包含feature_selection.f_classif(F检验分类)和feature_selection.f_regression(F检验回归)两个类。其中F检验分类用于标签是离散型变量的数据,而F检验回归用于标签是连续型变量的数据。
from sklearn.feature_selection import f_classif
from sklearn.datasets import load_iris
X,y = load_iris(return_X_y=True)
f_classif(X,y)# 返回F检验的F,P值
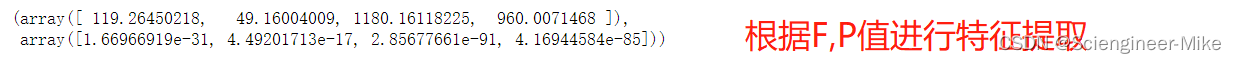
3.1.2.3.互信息法
互信息法是用来捕捉每个特征与标签之间的任意关系(包括线性和非线性关系)的过滤方法。和F检验相似,它既可以做回归也可以做分类,并且包含两个类feature_selection.mutual_info_classif(互信息分类)和feature_selection.mutual_info_regression(互信息回归)。互信息法不返回p值或F值类似的统计量,它返回“每个特征与目标之间的互信息量的估计”,这个估计量在[0,1]之间取值,为0则表示两个变量独立,为1则表示两个变量完全相关。以互信息分类为例的代码如下:
from sklearn.feature_selection import mutual_info_classif
from sklearn.datasets import load_iris
X,y = load_iris(return_X_y=True)
mic = mutual_info_classif(X,y)# 返回互信息量
(mic>0.5).sum()# 返回互信息大于0.5的特征数目

3.2.嵌入法
嵌入法是一种让算法自己决定使用哪些特征的方法,即特征选择和算法训练同时进行。在使用嵌入法时,我们先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据权值系数从大到小选择特征。这些权值系数往往代表了特征对于模型的某种贡献或某种重要性,比如决策树和树的集成模型中的feature_importances_属性,可以列出各个特征对树的建立的贡献,我们就可以基于这种贡献的评估,找出对模型建立最有用的特征。因此相比于过滤法,嵌入法的结果会更加精确到模型的效用本身,对于提高模型效力有更好的效果。
from sklearn.feature_selection import SelectFromModel
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
RFC = RandomForestClassifier()
X,y = load_iris(return_X_y=True)
SelectFromModel(RFC,threshold=0.05).fit_transform(X,y)[:10]# 筛选出feature_importances_>0.05的特征

3.3.包装法
包装法也是一个特征选择和算法训练同时进行的方法,与嵌入法十分相似,它也是依赖于算法自身的选择,比如coef_属性或feature_importances_属性来完成特征选择。但不同的是,我们往往使用一个目标函数作为黑盒来帮助我们选取特征,而不是自己输入某个评估指标或统计量的阈值。
from sklearn.feature_selection import RFE
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
RFC = RandomForestClassifier()
X,y = load_iris(return_X_y=True)
RFE(RFC,n_features_to_select=3).fit_transform(X,y)[:10]# 筛选出feature_importances_>0.05的特征

4.降维
降维,指的是降低特征矩阵中特征的数量,目的是为了让算法运算更快,效果更好。在降维过程中,我们会减少特征的数量,这意味着删除数据,数据量变少则表示模型可以获取的信息会变少,模型的表现可能会因此受影响。同时,在高维数据中,必然有一些特征是不带有有效的信息的(比如噪音),或者有一些特征带有的信息和其他一些特征是重复的(比如一些特征可能会线性相关)。我们希望能够找出一种办法来帮助我们衡量特征上所带的信息量,让我们在降维的过程中,能够即减少特征的数量,又保留大部分有效信息——将那些带有重复信息的特征合并,并删除那些带无效信息的特征等等——逐渐创造出能够代表原特征矩阵大部分信息的,特征更少的,新特征矩阵。具有代表性的降维算法有主成分分析法(PCA)和线性判别分析(LDA)。
4.1.PCA降维算法–无监督算法
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
X,y = load_iris(return_X_y=True)
X_new = PCA(n_components=2).fit_transform(X)
print("降维前特征的维度:",X.shape,"降维后特征的维度:",X_new.shape)

4.2.LDA降维算法–有监督算法
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA
from sklearn.datasets import load_iris
X,y = load_iris(return_X_y=True)
X_new = LDA(n_components=2).fit_transform(X,y)
print("降维前特征的维度:",X.shape,"降维后特征的维度:",X_new.shape)
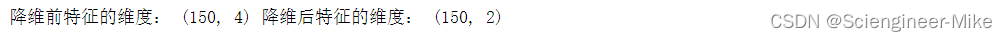
5.样本不平衡处理
样本(类别)样本不平衡(class-imbalance)指的是分类任务中不同类别的训练样例数目差别很大的情况,一般地,样本类别比例(Imbalance Ratio)(多数类vs少数类)明显大于1:1(如4:1)就可以归为样本不均衡的问题。现实中,样本不平衡是一种常见的现象,如:金融欺诈交易检测,欺诈交易的订单样本通常是占总交易数量的极少部分,而且对于有些任务而言少数样本更为重要。常用的方法上采样,下采样、SMOTE算法、加权处理等等。
5.1.上采样
## 使用上采样进行平衡样本
# 加载库
import numpy as np
from sklearn.datasets import load_iris
X,y = load_iris(return_X_y=True)
# 移除前 40 个观测
X = X[40:,:]
y = y[40:]
# 创建二元目标向量,表示是否是类 0
y = np.where((y == 0), 0, 1)
# 查看不平衡的目标向量
y
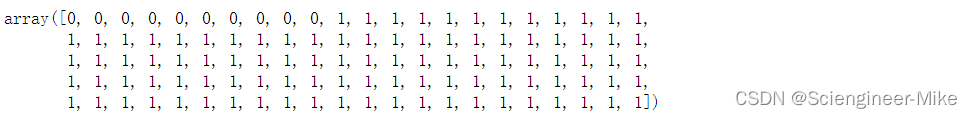
# 每个类别的观测的下标
i_class0 = np.where(y == 0)[0]
i_class1 = np.where(y == 1)[0]
# 每个类别的观测数量
n_class0 = len(i_class0)
n_class1 = len(i_class1)
# 对于类 1 中的每个观测,我们从类 0 中带放回随机选择观测。
i_class0_upsampled = np.random.choice(i_class0, size=n_class1, replace=True)
# 将类 0 的上采样的目标向量,和类 1 的目标向量连接到一起
np.concatenate((y[i_class0_upsampled], y[i_class1]))
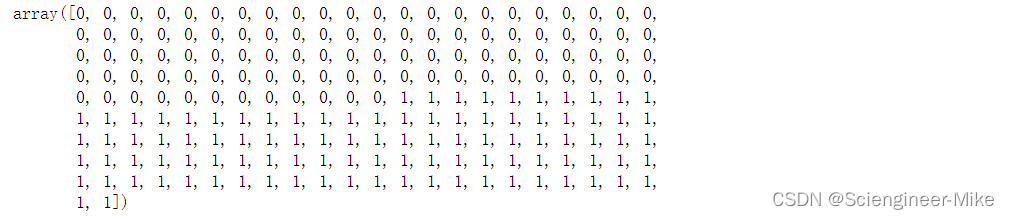
5.2.下采样
# 使用下采样处理不平衡类
# 加载库
import numpy as np
from sklearn.datasets import load_iris
X,y = load_iris(return_X_y=True)
X = X[40:,:]
y = y[40:]
# 创建二元目标向量,表示是否是类 0
y = np.where((y == 0), 0, 1)
# 查看不平衡的目标向量
y
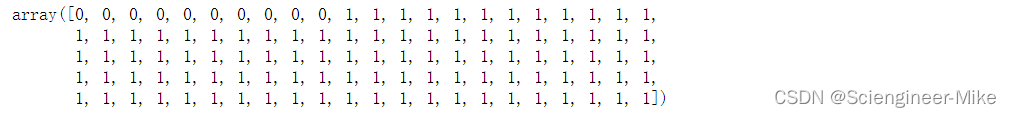
# 每个类别的观测的下标
i_class0 = np.where(y == 0)[0]
i_class1 = np.where(y == 1)[0]
# 每个类别的观测数量
n_class0 = len(i_class0)
n_class1 = len(i_class1)
# 对于类 0 的每个观测,随机从类 1 不放回采样
i_class1_downsampled = np.random.choice(i_class1, size=n_class0, replace=False)
# 将类 0 的目标向量,和下采样的类 1 的目标向量连接到一起
np.hstack((y[i_class0], y[i_class1_downsampled]))
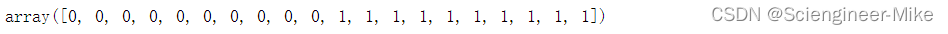
5.3.SMOTE
SMOTE全称是Synthetic Minority Oversampling即合成少数类过采样技术
主要思想是:利用特征空间中少数样本之间的相似性来建立人工数据,特别是,对于子集Smin<S,对于每一个样本Xi<Smin使用K-近邻法,其中K-近邻被定义为考虑Smin中的K个元素本身与Xi的欧式距离在n维特征空间X中表现为最小幅度值的样本。由于不是简单地复制少数类样本,因此可以在一定程度上避免分类器的过度拟合,实践证明此方法可以提高分类器的性能。
from imblearn.over_sampling import SMOTE
from sklearn.datasets import load_iris
X,y = load_iris(return_X_y=True)
# 移除前 40 个观测
X = X[40:,:]
y = y[40:]
# 创建二元目标向量,表示是否是类 0
y = np.where((y == 0), 0, 1)
# 查看不平衡的目标向量
y
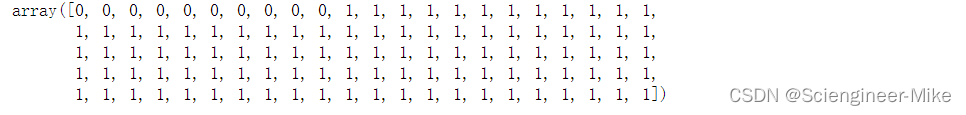
X,y = SMOTE(random_state=0).fit_resample(X,y)
y

5.4.加权处理
加权处理是指通过调整不同类型标签的权重值,增加占比少的类别 B 样本数据的权重,降低占比多的类别 A 样本数据权重,从而使总样本占比少的类别 B 的分类识别能力与类别 A 的分类识别能力能够同等抗衡。在sklearn各个算法中,常用来处理样本不均衡的参数有类别权重:class_weight,样本权重:sample_weight。如果即用了class_weight,又用了sample_weight,那么样本的真正权重是:class_weight × sample_weight。在用xgb进行分类任务时,若是样本不均衡,可以用参数scale_pos_weight调节,一般输入的是负样本量与正样本量之比。各个算法有自己单独的权重参数,具体不过多述,读者可自行深入探究。
#设定class_weight
wclf = svm.SVC(kernel='linear', class_weight={
1: 10})
wclf.fit(X, y)
# 负/正样本的比例
XGBClassifier(scale_pos_weight=10).fit(X,y)
6.总结
特征工程指的是把原始数据转变为模型的训练数据的过程,它的目的就是获取更好的训练数据特征,使得机器学习模型逼近这个上限。本文就完成了机器学习中特征处理方法的汇总,包括数据的预处理,数据特征的选择,数据特征的降维以及最后的样本不均衡处理。希望对大家有所帮助。
链接: 【机器学习之集成算法】RandomForest和XGboost原理介绍与代码实现
链接: 【机器学习之逻辑回归】sklearn+python逻辑回归详解
链接: 【机器学习之聚类算法】KMeans原理及代码实现
链接: 【机器学习之线性回归】多元线性回归模型的搭建+Lasso回归的特征提取
链接: 【机器学习之决策树】决策树原理介绍及代码实现sklearn