该小节讲解数据的降维,注意这里的降维不是数组的降维,这里的维代表的是特征,如一组数据我们通过特征抽取之后获得4个特征,我们在这里称为4维,降维即减少特征数量。
为什么要减少特征的数量,如我们之前的例子:

皮肤的颜色对对于分辨男女是没有影响的,所以我们可以进行降维。有的时候我们特城抽取之后的数据有几百个特征,甚至更多,则根据我们的需要进行合适的降维。
常用的降维方式有2种:
1.特征选择
2.主成分分析
我们先讲解特征选择这种方式
特征选择
从字面上也十分的好理解,就是选择部分特征当做我们想要的数据。比如我们需要对鸟进行分类。那么每来一只鸟,我们就要进行特城收集,如
1.羽毛颜色 2.眼睛宽度 3.是否有爪子 4.爪子长度等等
如上的是否有爪子,这个我们是不需要的,因为鸟都是有爪子的,也就是说,我们准备好数据之后,还需要有一个特征的筛选过程,该分为两种情况,1.在收集数据的时候,人为的进行选择。2.利用工具进行选择。
其工具有三大武器:
Filter(过滤式):VarianceThreshold
Embedded(嵌入式):正则化、决策树
Wrapper(包裹式)
第三种Wrapper(包裹式)就不进行讲解了,因为用的比较少,Embedded暂时不讲解,在后续讲解算法的时候,为大家讲解。所以接下来我们会讲解Filter,Filter中有一种方法叫做VarianceThreshold(方差过滤),他是什么呢?
从名字上看,叫方差过滤,我们为什么要对方差进行过滤呢?有的时候我们拿到的数据中,其有的特征一列都是相同的(当然还有其他的情况),那么我们就没有必要进行方差计算,所以需要进行过滤。
sklearn特征选择API:
sklearn.feature_selection.VarianceThreshold
使用方法
VarianceThreshold(threshold = 0.0)
删除所有低方差特征
Variance.fit_transform(X,y)
X:numpy array格式的数据[n_samples,n_features]
返回值:训练集差异低于threshold的特征将被删除。
默认值是保留所有非零方差特征,即删除所有样本
中具有相同值的特征。
测试数据:
[[0, 2, 0, 3],
[0, 1, 4, 3],
[0, 1, 1, 3]]
编写代码如下:
from sklearn.feature_selection import VarianceThreshold
def var():
"""
特征选择:删除低方差特征
:return:
"""
var = VarianceThreshold(threshold=0.0)
data = var.fit_transform([[0, 2, 0, 3], [0, 1, 4, 3], [0, 1, 1, 3]])
print(data)
return None
if __name__ == '__main__':
var()
运行之后,打印信息如下:
[[2 0]
[1 4]
[1 1]]
threshold的值要根据实际的需求进行选择。
主成分分析
下面我们开始时间截主成分分析,先了解几个概念,PCA是什么
:
本质:PCA是一种分析、简化数据集的技术
目的:是数据维数压缩,尽可能降低原数据的维数(复杂度),损失少量信息。
作用:可以削减回归分析或者聚类分析中特征的数量
PCA代表的就是主成分分析,一般来说应用的场景不是特别多,如果特征的数量特别多(达到上百个),首先考虑的问题是需不需要使用PCA去简化数据,其实就是减少特征数量,但是数据也会改变(损耗很少)。
有算法是必须使用PCA进行降维处理的。
高维度数据容易出现的问题,特征之间通常都是相关的,如下:
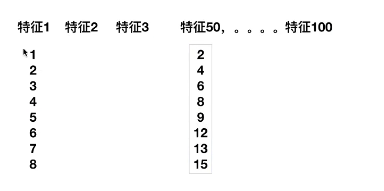
可以看到特征1余特征50,他们的关系十分明显,进行缩放以后,可以替代宁外一个特征,所以我们可以把他们合并在一起,用一个特征进行表示。在特征比较多的时候,类似这种情况是不可避免的,所以此时我们就新药运用到PCA。
PCA语法:
PCA(n_components=None)
将数据分解为较低维数空间
PCA.fit_transform(X)
X:numpy array格式的数据[n_samples,n_features]
返回值:转换后指定维度的array
其上的n_components有两种填写方式:
1.小数:代表你要保留的数据信息,如0.9代表你需要保留原来百分之90的信息,只能损耗百分之十。一般为0.9-0.95之间
2.整数:减少的特征数量(一般我们不使用,因为很难确定我们需要减少的特征数量)
测试数据:
[[2,8,4,5],
[6,3,0,8],
[5,4,9,1]]
编写程序:
from sklearn.decomposition import PCA
def pca():
"""
主成分分析
:return:
"""
pca = PCA(n_components=0.9)
data = pca.fit_transform([[2,8,4,5],[6,3,0,8],[5,4,9,1]])
print(data)
return None
if __name__ == '__main__':
pca()
打印信息如下:
[[ 1.28620952e-15 3.82970843e+00]
[ 5.74456265e+00 -1.91485422e+00]
[-5.74456265e+00 -1.91485422e+00]]