1.13 特征选择
sklearn.feature_selection模块中的类可以用于样本集上的特征选择/降维,以提高估计器的精度值,或提高其应用在高维数据集上的性能。
1.13.1 删除低方差的特征
VarianceThreshold是一种简单的特征选择baseline方法。它删除了方差不满足某个阈值的所有特性。
默认情况下,它会删除所有的零方差特性,即在所有样本中具有相同值的特性。
例如,假设我们有一个具有布尔特征的数据集,并且我们想要删除超过80%的样本中所有要么为1要么为0(开或关)的特征。
布尔特征是伯努利随机变量,其方差为
\(\mathrm{Var}[X] = p(1 - p)\)
所以我们可以选择使用阈值 .8 * (1 - .8):
from sklearn.feature_selection import VarianceThreshold
X = [[0, 0, 1], [0, 1, 0], [1, 0, 0], [0, 1, 1], [0, 1, 0], [0, 1, 1]]
sel = VarianceThreshold(threshold=(.8 * (1 - .8)))
sel.fit_transform(X)array([[0, 1],
[1, 0],
[0, 0],
[1, 1],
[1, 0],
[1, 1]])
VarianceThreshold删除了第一列,该列包含0的概率为p = 5/6 > .8。
1.13.2 单变量特征选择
单变量特征选择的工作原理是基于单变量统计检验来选择最佳特征。它可以被看作是估计器的一个预处理步骤。
Scikit-learn将特性选择例程作为实现转换方法的对象公开:
SelectKBest 删除了k个最高评分的特征以外的所有特性;
SelectPercentile 删除了除用户指定的最高评分百分比以外的所有特征;
对每个特征使用常见的单变量统计检验: 假阳性率SelectFpr,假发现率SelectFdr,或族判断误差率SelectFwe;
GenericUnivariateSelect允许使用可配置策略执行单变量特性选择。这允许选择最好的单变量选择策略与超参数搜索估计器。
例如,我们可以对样本进行\(\chi^2\)测试,只检索两个最好的特征:
from sklearn.datasets import load_iris
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
X, y = load_iris(return_X_y=True)
X_new = SelectKBest(chi2, k=2).fit_transform(X, y)
X.shape, X_new.shape((150, 4), (150, 2))
这些对象接受一个评分函数作为输入,该函数返回单变量分数和p-值(或仅返回SelectKBest和SelectPercentile的分数):
对于回归问题: f_regression, mutual_info_regression
对于分类问题: chi2, f_classif, mutual_info_classif
基于F检验的方法估计了两个随机变量之间的线性相关程度。
另一方面,互信息方法可以捕获任何类型的统计相关性,但由于是非参数的,因此需要更多的样本来进行准确的估计。
1.13.3 递归特征删除
给定一个给特征赋予权重的外部估计量(例如,线性模型的系数),递归特征删除(RFE)是通过递归地考虑越来越小的特征集来选择特征。
首先,对估计器进行原始特征集的训练,然后通过coef_属性或feature_importances_属性获得每个特征的重要性。
然后,从当前的一组特性中删除最不重要的特性。该过程在修剪集上递归地重复,直到最终达到所需的要选择的特性数量。
RFECV在交叉验证循环中执行RFE,以找到最优的特性数量。
1.13.4 用SelectFromModel选择特征
SelectFromModel是一个元转换器,可以与任何在拟合后具有coef_或feature_importances_属性的估计器一起使用。
如果相应的coef_或feature_importances_值低于提供的阈值参数,则认为这些特性不重要并将其删除。
除了以数字方式指定阈值外,还有使用字符串参数查找阈值的内置启发式方法。
可用的启发式方法是“平均数”、“中位数”和这些数的浮点倍数,如“0.1*平均数”。
有关如何使用它的示例,请参考下面的部分。
1.13.4.1 基于L1的特征选择
用L1范数惩罚的线性模型具有稀疏解:它们的许多估计系数为零。
当目标是减少与另一个分类器一起使用的数据的维数时,可以将它们与feature_selection.SelectFromModel一起使用来选择非零系数。
特别是,稀疏估计器很适用此场景,如用于回归的linear_model.Lasso和用于分类的linear_model.LogisticRegression和svm.LinearSVC:
from sklearn.svm import LinearSVC
from sklearn.datasets import load_iris
from sklearn.feature_selection import SelectFromModel
X, y = load_iris(return_X_y=True)
lsvc = LinearSVC(C=0.01, penalty="l1", dual=False).fit(X, y)
model = SelectFromModel(lsvc, prefit=True)
X_new = model.transform(X)
X.shape, X_new.shape((150, 4), (150, 3))
对于支持向量机和逻辑回归,参数C控制了稀疏性:C越小,选择的特征越少。对于Lasso, alpha参数越高,选择的特征越少。
1.13.4.2 基于树的特征选择
基于树的估计器(参照sklearn.tree模块和sklearn.ensemble模块中的森林)可用于计算特征的重要性,而这些重要性又可用于丢弃不相关的特征(与SelectFromModel元转换器结合使用):
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.datasets import load_iris
from sklearn.feature_selection import SelectFromModel
X, y = load_iris(return_X_y=True)
clf = ExtraTreesClassifier(n_estimators=50)
clf = clf.fit(X, y)
model = SelectFromModel(clf, prefit=True)
X_new = model.transform(X)
X.shape, X_new.shape, clf.feature_importances_((150, 4), (150, 2), array([0.09394361, 0.05591118, 0.42796637, 0.42217885]))
1.13.5 特征选择作为流水线的一部分
特征选择通常用作实际学习之前的预处理步骤。在scikit-learn中推荐的方法是使用sklearn.pipeline.Pipeline:
clf = Pipeline([
('feature_selection', SelectFromModel(LinearSVC(penalty="l1"))),
('classification', RandomForestClassifier())
])
clf.fit(X, y)在这个代码片段中,我们使用了sklearn.svm.LinearSVC和sklearn.feature_selection.SelectFromModel用于评估特征重要性并选择最相关的特征。
然后,一个sklearn.ensemble.RandomForestClassifier针对转换后的输出进行训练,即仅使用相关特征。
还可以使用其他特性选择方法以及提供评估特性重要性方法的分类器执行类似的操作。
完整案例
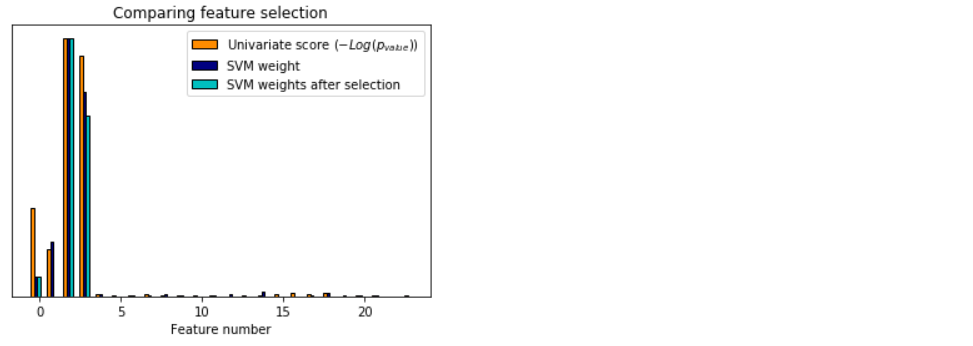
一个显示单变量特征选择的例子。
在iris数据中加入噪声(非信息性)特征,应用单变量特征选择。
对于每个特征,我们绘制单变量特征选择的p值和支持向量机相应的权值。
我们可以看到,单变量特征选择选择了信息特征,并且这些特征具有更大的SVM权值。
在整个特征集中,只有前四个特征是重要的。我们可以看到他们在单变量特征选择上得分最高。
支持向量机给这些特征赋予了很大的权重,但也选择了许多非信息性特征。
在支持向量机之前进行单变量特征选择,可以增加支持向量机的显著特征权重,从而改善分类。
print(__doc__)
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets, svm
from sklearn.feature_selection import SelectPercentile, f_classif
# #############################################################################
# Import some data to play with
# The iris dataset
iris = datasets.load_iris()
# Some noisy data not correlated
E = np.random.uniform(0, 0.1, size=(len(iris.data), 20))
# Add the noisy data to the informative features
X = np.hstack((iris.data, E))
y = iris.target
plt.figure(1)
plt.clf()
X_indices = np.arange(X.shape[-1])
# #############################################################################
# Univariate feature selection with F-test for feature scoring
# We use the default selection function: the 10% most significant features
selector = SelectPercentile(f_classif, percentile=10)
selector.fit(X, y)
scores = -np.log10(selector.pvalues_)
scores /= scores.max()
plt.bar(X_indices - .45, scores, width=.2,
label=r'Univariate score ($-Log(p_{value})$)', color='darkorange',
edgecolor='black')
# #############################################################################
# Compare to the weights of an SVM
clf = svm.SVC(kernel='linear')
clf.fit(X, y)
svm_weights = (clf.coef_ ** 2).sum(axis=0)
svm_weights /= svm_weights.max()
plt.bar(X_indices - .25, svm_weights, width=.2, label='SVM weight',
color='navy', edgecolor='black')
clf_selected = svm.SVC(kernel='linear')
clf_selected.fit(selector.transform(X), y)
svm_weights_selected = (clf_selected.coef_ ** 2).sum(axis=0)
svm_weights_selected /= svm_weights_selected.max()
plt.bar(X_indices[selector.get_support()] - .05, svm_weights_selected,
width=.2, label='SVM weights after selection', color='c',
edgecolor='black')
plt.title("Comparing feature selection")
plt.xlabel('Feature number')
plt.yticks(())
plt.axis('tight')
plt.legend(loc='upper right')
plt.show()Automatically created module for IPython interactive environment