特征选择与降维2–降维
什么是降维?
降维是通过获得一组基本上是重要特征的主变量来减少所考虑的特征变量的过程。现实应用中属性维度成千上万,在高维度情况下会带来很多麻烦,而且当维度大的时候,数据样本一般分布的非常稀疏,这是所有学习算法要面对的问题,降维技术应运而生。
降维是对事物的特征进行压缩和筛选,该项任务相对比较抽象。如果没有特定领域知识,无法预先决定采用哪些数据,比如在人脸识别任务中,如果直接使用图像的原始像素信息,数据的维度会非常高,通常会利用降维技术对图像进行处理,保留下最具有区分度的像素组合。
降维中的数据集样本:
在降维方法中我们把样本数据集看成是矩阵,数据集的每行对应一个样本,每列对应一个特征或者维度,所以降维方法的证明均源于数学中很多关于矩阵的处理技巧和定理。
机器学习领域中所谓的降维就是指采用某种映射方法,将原高维空间中的数据点映射到低维度的空间。
降维的本质是学习一个映射函数f : x->y,其中x是原始数据点的表达,目前最多使用向量表达形式。 y是数据点映射后的低维向量表达,通常y的维度小于x的维度(当然也可以提高维度)。映射函数f可能是显式的或隐式的、线性的或非线性的。
在很多算法中,降维算法成为了数据预处理的一部分。一些算法如果没有降维预处理,就很难得到很好的效果。
常见的降维方法:
1.SVD–奇异值分解
奇异值分解(Singular Value Decomposition,简称SVD)是在机器学习领域广泛应用的算法,它不光可以用于降维算法中的特征分解,还可以用于推荐系统,以及自然语言处理等领域,是很多机器学习算法的基础,更是PCA降维方法的基础。
SVD的原理简单,仅涉及简单的矩阵线性变换知识,奇异值分解是一个能适用于任意矩阵的一种分解方法,奇异值分解发现矩阵中的冗余并提供用于消除他的格式,奇异值分解就是利用隐藏的特征建立起矩阵行和列之间的联系
SVD是较强的数据降维工具,可以有效处理数据噪音。在数据处理过程中得到的三个矩阵,也有相关物理含义。
SVD 的缺点是分解出的矩阵的可解释性差,计算量大。
关于奇异值分解的原理这里就不重复了,我在之前的预备知识的笔记中详细记录过。
前一篇笔记:大数据学习–预备知识:数学基础
SVD的原理不难,只要有基本的线性代数知识就可以理解,实现也很简单因此值得仔细的研究。当然,SVD的缺点是分解出的矩阵解释性往往不强,有点黑盒子的味道,不过这不影响它的使用。
由于奇异值的计算是一个纯数学的过程,在数据挖掘的应用中只要理解其原理掌握应用方法即可。
SVD的性质:一般地,奇异值的减少特别的快,在很多情况下,前10%甚至1%的奇异值的和就占了全部的奇异值之和的99%以上的比例。即可以用最大的k个的奇异值和对应的左右奇异向量来近似描述矩阵A,这样矩阵A的信息量就被极大的压缩和去除噪声,也为后续大规模的计算提高了效率。
SVD分解可以广泛地用来求解最小二乘问题,正则化问题,低秩逼近问题,数据压缩问题,文本处理中的分类问题。
SVD应用与推荐系统
推荐系统定义:不需要用户提供明确的需求,通过分析用户的历史行为给用户的兴趣建模,从而主动给用户推荐能够满足他们兴趣和需求的信息的在线系统。
对比搜索引擎:搜索引擎满足了用户有明确目的主动查找需求,而推荐系统能够在用户没有明确目的的时候帮助他们发现感兴趣的新内容。
SVD用于推荐系统思路:
提取数据集,一般数据集的行代表用户user,列代表物品item,其中的值代表用户对物品的打分。
基于SVD的优势在于:用户的评分数据是稀疏矩阵,可以用SVD将原始数据映射到低维空间中,然后计算物品item之间的相似度,可以节省计算资源。
整体思路:先找到用户没有评分的物品,然后再经过SVD“压缩”后的低维空间中,计算未评分物品与其他物品的相似性,得到一个预测打分,再对这些物品的评分从高到低进行排序,返回前N个物品推荐给用户。
2.PCA–主成份分析
PCA(Principal Component Analysis,主成分分析)
在高维向量空间中,随着维度的增加,数据呈现出越来越稀疏的分布特点,增加后续算法的复杂度,而很多时候虽然数据维度较高,但是很多维度之间存在相关性,他们表达的信息有重叠。
思想:
寻找表示数据分布的最优子空间(降维,可以去掉现行相关性)
PCA的思想是将n维特征映射到k维上(k<n),这k维是全新的正交特征。
这k维特征称为主成分,是重新构造出来的k维特征,而不是简单地从n维特征中去除其余n-k维特征(这也是与特征选择特征子集的方法的区别)。
数学原理:
取协方差矩阵前s个最大特征值对应的特征向量构成映射矩阵,对数据进行降维
PCA的目的是在高维数据中找到最大方差的方向,接着映射它到比最初维数小或相等的新的子空间。
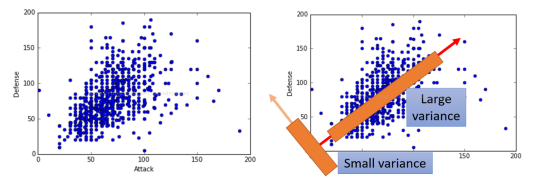
在PCA中,数据从原来的坐标系转换到新的坐标系,由数据本身决定。转换坐标系时,以方差最大的方向作为坐标轴方向,因为数据的最大方差给出了数据的最重要的信息。第一个新坐标轴选择的是原始数据中方差最大的方法,第二个新坐标轴选择的是与第一个新坐标轴正交且方差次大的方向(这个要在3维以上空间体会)。重复该过程,重复次数为原始数据的特征维数。
通过这种方式获得的新的坐标系,而且大部分方差都包含在前面几个坐标轴中,后面的坐标轴所含的方差几乎为0,。可以忽略余下的坐标轴,只保留前面的几个含有绝不部分方差的坐标轴。事实上,这样也就相当于只保留包含绝大部分方差的维度特征,而忽略包含方差几乎为0的特征维度,也就实现了对数据特征的降维处理。
PCA算法的流程:
输入:n维特征的样本数据集D
输出:降到p维后的样本集D’
1.对所有样本构成的矩阵X进行去中心化
2.求出X的协方差矩阵C
3.利用特征值分解,求出协方差矩阵C的特征值及对应的特征向量
4.将特征向量按对应特征值大小从上到下按行排列成矩阵,根据实际业务场景,取前p列组成新的坐标矩阵W
5.令原始数据集与新坐标矩阵W相乘,得到新的数据集即为降到p维后的数据集
PCA的优缺点:
优点:
以方差衡量信息的无监督学习,不受样本标签限制。
各主成分之间正交,可消除原始数据成分间的相互影响。
计算方法简单,主要运算是奇异值分解,易于在计算机上实现。
可减少指标选择的工作量。
缺点:
主成分解释其含义往往具有一定的模糊性,不如原始样本特征的解释性强。
方差小的非主成分也可能含有对样本差异的重要信息,因降维丢弃可能对后续数据处理有影响。
3.LDA - 线性判别分析
LDA是一种监督学习的降维技术,将数据在低维度上进行投影,投影后希望每一种类别数据的投影点尽可能的接近,而不同类别的数据的类别中心之间的距离尽可能的大。
思想:寻找可分性判据最大的子空间。
用到了Fisher的思想,即寻找一个向量,使得降维后类内散度最小,类间散度最大;其实就是取对应的特征向量构成映射矩阵,对数据进行处理

假设我们有两类数据 分别为红色和蓝色,如上图所示,这些数据特征是二维的,我们希望将这些数据投影到一维的一条直线,让每一种类别数据的投影点尽可能的接近,而红色和蓝色数据中心之间的距离尽可能的大。
图中提供了两种投影方式,直观上可以看出,右图要比左图的投影效果好,因为右图的黑色数据和蓝色数据各个较为集中,且类别之间的距离明显。左图则在边界处数据混杂。以上就是LDA的主要思想了,在实际应用中,数据是多个类别的,原始数据一般也是超过二维的,投影后的也一般不是直线,而是一个低维的超平面。
LDA的算法流程:

LDA的优缺点:
优点:
在降维过程中可以使用类别的先验经验。
LDA在样本分类信息依赖均值而不是方差的时候,比PCA之类的算法较优。
缺点:
LDA不适合对非高斯分布样本进行降维,PCA也有这个问题。
LDA降维最多降到类别数k-1的维数,如果我们降维的维度大于k-1,则不能使用LDA。当然目前有一些LDA的进化版算法可以绕过这个问题。
LDA在样本分类信息依赖方差而不是均值的时候,降维效果不好。
LDA可能过度拟合数据。
4.LLE - 局部线性嵌入
局部线性嵌入(Locally Linear Embedding,简称LLE)也是非常重要的降维方法。和传统的PCA,LDA等关注样本方差的降维方法相比,LLE关注于降维时保持样本局部的线性特征,由于LLE在降维时保持了样本的局部特征,它广泛的用于图像识别,高维数据可视化等领域。
LLE属于流形学习的一种,和传统的PCA、LDA相比,不再是关注样本方差和样本间协方差,而是一种关注降维时保持样本局部的线性特征的方法。
LLE方法执行思路是:将高维流形分成很多小块,每一小块可以用平面代替,然后再在低维中重新拼合起来,且要求保留各点之间的拓扑关系不变。
LLE首先假设数据在较小的局部是线性的,即某一个数据能够用它邻域中的几个样本来线性表示,可以通过k-近邻的思想来找到它的近邻点。在降维之后,希望样本点对应的投影尽量保持同样的线性关系,即投影前后线性关系的权重参数不变或者改变很小。
线性关系只在样本的附近起作用,离样本远的样本对局部的线性关系没有影响,因此降维的复杂度降低了很多。
LLE的算法流程:

LLE的优缺点:
优点有:
可以学习任意维的局部线性的低维流形。
算法归结为稀疏矩阵特征分解,计算复杂度相对较小,实现容易。
缺点有:
算法所学习的流形只能是不闭合的,且样本集是稠密均匀的。
算法对最近邻样本数的选择敏感,不同的最近邻数对最后的降维结果有很大影响。
PCA的实现:
主要利用PCA原理逐步对实现简单两维数据集的降维,需要手工输入一个两维10行的实验数据集,两个维度代表两个特征,分别用x和y表示。
1.导入数据处理模块与手工输入原始数据
import numpy as np
x=np.array([2.5,0.5,2.2,1.9,3.1,2.3,2,1,1.5,1.1])
y=np.array([2.4,0.7,2.9,2.2,3.0,2.7,1.6,1.1,1.6,0.9])
x=x[:,np.newaxis] #np.newaxis 为 numpy.ndarray(多维数组)增加一个轴
y=y[:,np.newaxis]
2.将输入的两个特征进行整合
#将x和y整合后的数据赋值给变量O
O=np.hstack((x,y)) #np.hstack():数组拼接函数,h表示在水平方向上平铺
3.将输入的x与y两个去中心化
#将x和y整合后,再去中心化,并赋值给变量X,也就是用于降维处理的矩阵
X=np.hstack((x-np.mean(x,axis=0),y-np.mean(y,axis=0)))
4.计算去中心化后的矩阵X的协方差矩阵C
C=np.cov(X.T) #计算协方差矩阵
5.计算协方差矩阵C的特征值和特征向量
eigenvalues, eignvactors = np.linalg.eig(C)#计算协方差矩阵的特征值和特征向量
print(eigenvalues)
print(eignvactors)
6.求出特征值对应的信息量占比
tot = sum(eigenvalues) # 求出特征值的和
var = [(i / tot) for i in sorted(eigenvalues, reverse=True)] # 求出每个特征值占的比例(降序)
7.利用最大特征值对应的特征向量构造变换矩阵
index=np.argsort(eigenvalues) #将特征值按从大到小排序,index保留的是对应原特征值序列中的下标
n_index=index[-1:-2:-1] #取最大的1维特征值在原特征数据集中的下标
W=np.matrix(eignvactors[:, n_index]) #取最大的1维特征值对应的特征向量组成变换矩阵
8.利用变换矩阵对原始数据矩阵进行降维
O*W
