论文阅读-FaceForensics++: Learning to Detect Manipulated Facial Images

概述
本文的主要对DeepFake Detection的相关工作做了总结, 并提出了一个新的数据集用以进行DFD任务. 该数据集是免费开源的, 如果需要使用, 要需要填写一个表单向作者申请, 表单可以在下面的github里获得. 根据我的体验他们回复是很快的, 大概一到两天就会给出下载的脚本.
本文project的github地址: https://github.com/ondyari/FaceForensics
方法
大致上, 本文没提出新的模型, 整体而言本文还是提出了一个benchmark. 但他们还是给出了自己的表现比较好的模型, 基于Xception. 做法如下:

输入一张图片, 使用Dlib工具的face detector获取脸部, 然后将脸部乘1.3作为模型的输入. 模型是在ImageNet上训练的Xception, 作者经过一部分细微的微调, 即将元模型最后的全连接层更改为两个输出. 其余权重是在ImageNet上获取的.
此外作者采用的baseline有:
手工特征 + CNN*(Cozzolino et al. Recasting residual-based local descriptors as convolutional neural networks: an application to image forgery detection )*
一个使用约束卷积层的卷积网络*(Bayar and Stamm, A deep learning approach to universal image manipulation detection using a new convolutional laye)*
使用全局池化层的CNN*(Rahmouni et al. Distinguishing computer graphics from natural images using convolution neural networks)*
MesoInception-4 (Mesonet: a compact facial video forgery detection network)
5)人工辨识(224个学生)
- 手工特征+SVM
实验结果
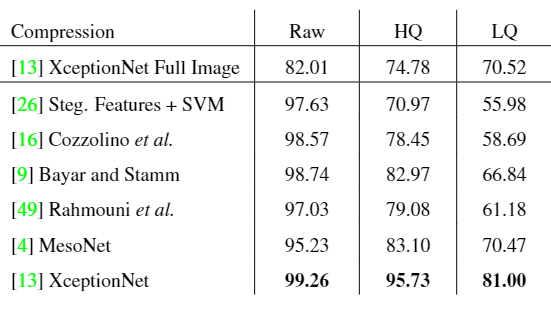
从结果来说可以看到, 当视频进行压缩(LQ, low quality)的时候, 模型基本都出现了严重的表现下滑, 而且这些模型基本上都无法很好的扩展(需要以知fake模型), 这一点在X-ray里面有相关的描述(该论文阅读见https://www.cnblogs.com/Xuang/p/13055088.html).