本博客系博主阅读论文之后根据自己理解所写,非逐字逐句翻译,预知详情,请参阅论文原文。
论文标题:Neural Transformation Learning for Deep Anomaly Detection Beyond Images;
论文作者:Chen Qiu 1 2, Timo Pfrommer 1, Marius Kloft 2 ,Stephan Mandt 3 ,Maja Rudolph 1;
1 Bosch Center for AI
2 TU Kaiserslautern
3 UC Irvine.
Correspondence to: Maja Rudolph
论文发表地点:ICML 2021;
论文下载地址:[2103.16440] Neural Transformation Learning for Deep Anomaly Detection Beyond Images
代码地址:https://github.com/boschresearch/NeuTraL-AD
Neural Transformation Learning for Deep Anomaly Detection Beyond Images | Papers With Code
摘要:
数据变换(比如旋转,反射,和裁剪)在自监督学习中有很大的作用。典型的,对图像进行不同角度的变换,那么在与这些角度有关的下游任务上,使用这些变换后的图像数据训练的神经网络模型就能学习到更有效的特征表示,包括异常检测任务。
然而,对于非图像数据的异常检测任务而言,使用何种变换方式通常是不清楚的(什么变换方式较好)。
因此本文提出了一个简单的端到端的步骤,借用可学习的变换来应对异常检测。本文模型的关键点是将变换后的数据嵌入到一个语义空间中,在该空间中的转换后数据表征与原始数据表征(转换前的)相似,并且不同的转换间很容易区分。
在时间序列数据上的实验表明本文模型在 one-vs.-rest 设置下显著优于现有的模型,在更难的 n-vs.-rest 异常检测任务设置下也很好。在医学和网络安全领域的表格数据上的实验表明,本文的方法能够学到领域特定的变换,比以前的工作更加准确地检测异常。
本文动机:
1.在异常检测,自监督学习等领域中,数据增强很有效。尤其是对图像数据,借助不同转换方式下的图像数据能极大提高模型的能力。但是对非图像数据,明确何种转换方式是有效的,设计特定的转换方式,都很难。因此本文针对非图像类型数据,设计了可学习的转换方法,不用手工设计转换方式。
现存方法的问题:
1.针对图像数据的转换方法不适合其他数据类型,比如时间序列,表格数据等;
2.传统对比学习损失需要采样负样本,本文设计的损失函数不需要额外的正则化或者对抗学习,可直接用于计算异常分数。
本文主要贡献:
1.针对非图像数据,设计了可学习的数据转换方式;
2.构建了端到端的异常检测模型,基于原始对比学习设计了新的确定性对比学习(deterministic contrastive loss)目标函数;
本文模型和方法:
本文方法NeuTral AD主要包含两个部分:一个可学习的转换器集合,一个编码器。两者用确定性对比损失(DCL)联合训练。该损失函数在训练阶段用于学习转换器集合和编码器的参数,在测试阶段用于计算每个样本是否为异常点。
可学习的数据转换器 Learnable Data Transformations:
给定有N个样本的数据集D,数据空间为X。本文构造K个可学习的转换器T,这些转换器可以用任意基于梯度优化的参数网络建模,将他们的参数记为theta_k。本文实验中使用简单的前馈神经网络建模T,具体实现方式见下文实验部分。
确定性对比学习损失 Deterministic Contrastive Loss (DCL):
本文基于对比学习损失设计了一种新的损失函数DCL。该损失函数要求样本的转换后数据与样本原始数据相似,且同样本不同转换器得到的转换数据间不相似。
首先定义两个数据样本间的分数为:
![]()
其中k,l代表不同的转换器,是本文的编码器,sim()函数计算两个输入数据的余弦相似度,tao是一个温度参数。
DCL损失函数定义为:
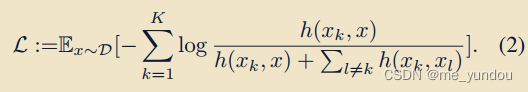
本文模型的参数包括编码器的参数phi和K个转换器的参数theat_{1:k}。
整体结构:
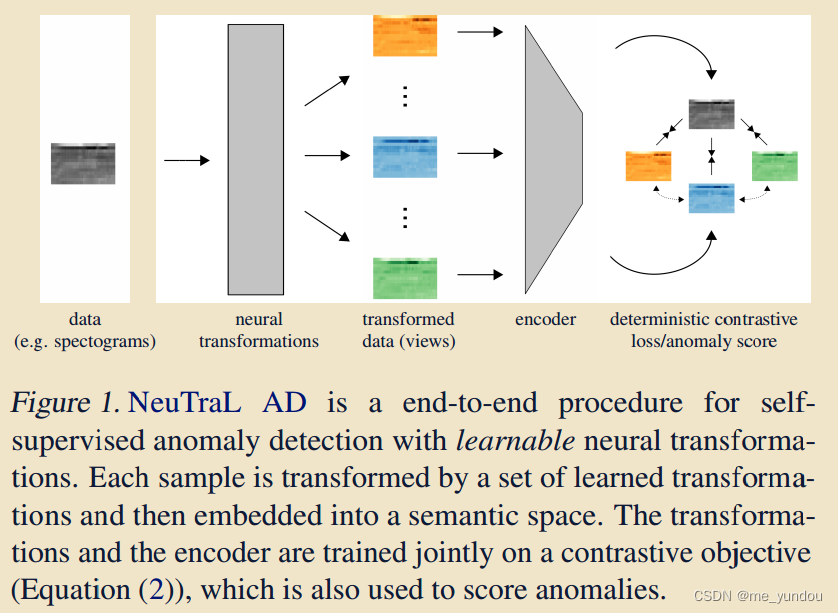
如上图1所示,是模型的整体结构,输入数据经过一系列可学习的转换器得到不同角度的转换后数据,然后使用编码器对原始数据及转换后数据进行特征提取,最后DCL损失函数要求每种转换后数据与原始数据相似,且不同转换数据间不相似。
异常分数计算:
本文方法的一个优势是模型训练loss就是异常分数计算方式,如下:

本文方法的理论解释:
本文的多个转换器设计可能出现平凡解:
- 所有转换器都是常数输出(常数的数值不同);
- 所有转换器都是同样的输出(非常数,但是输出公式一样)。
然后本文在3.2节及附录详细介绍了理论解释,因为博主对该部分还没有理解到位,这里不再进行说明,预知详情者请参阅论文原文。
实验:
任务:异常检测;
数据集:
- 时间序列数据集:SAD,NAROPS,CT,EPSY,RS;
- 表格数据数据集:Arrhythmia, Thyroid, KDD,KDDRev;
- (因为图像数据上人工定义的转换方法已经很厉害了,所以本文不对图像数据进行对比实验);
评估指标:
使用两种异常检测评估方式:
- the standard ‘one-vs.-rest’ :将所有数据分为N个one class 分类任务,一类作为正常数据训练,其他所有类中选取数据作为异常进行测试;
- the more challenging ‘n-vs.-rest’:将若干个类作为正常,剩余类作为异常,通过增加更多的类作为正常类,该方式会更难;
对比方法:
- (浅层)传统算法:OC-SVM, IF, LOF;
- 深度算法:Deep SVDD, DROCC ,DAGMM;
- 自监督算法:GOAD,[1] is a softmax-based classification method based on hand-crafted transformations;
- 时间序列算法:本文还对比了两个专门处理时间序列数据的模型,RNN-based model (RNN), LSTM-ED;
实现细节:
在针对时间序列数据的实验中,本文转换器,其中M_k由三个带instance normalization层的残差模块外加一个由sigmoid激活的卷积层构成。所有的偏置项为0.本文编码器由若干残差模块和一维的卷积层构成,残差模块数量由数据的维度决定,编码器的输出层维度是64.
在针对表格数据的实验中,本文转换器,其中M_k由3个不带偏置项的带relu激活层的线性层构成,最后的输出层是一个sigmoid函数。针对不同的表格数据集,可学习的转换器数目不一样,具体见论文。本文编码器由3或者4个以relu激活的线性层构成。
实验结果分析:
- 时间序列数据集上结果:

从上表1可以看出,本文方法NeuTral AD比所有浅层方法都好,与其他深度学习方法对比,在5个数据集有4个都超过他们的结果。本文方法只在RS数据集上比不过手工定义的固定的转换器方法,这说明设计特定的转换器只能在部分场景下较好,而本文的可学习转换器能够为不同数据学习合适的转换方式。
可视化实验:
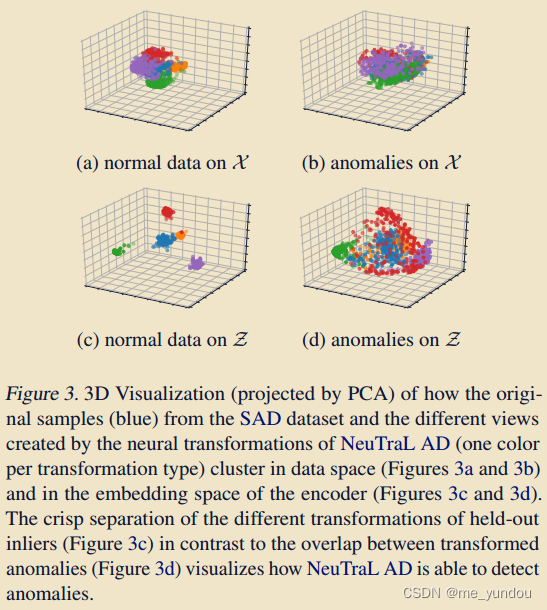
如上图3所示,在SAD数据集上使用4个可学习的转换器,X是输入数据空间,Z是编码器所学的嵌入空间,其中蓝色点是原始数据, 其他颜色点是不同转换器得到的转换后数据。从图3a中可以看出,转换后的数据各自聚类在一起,但是只有在编码器的帮助下,不同转换下的数据才能分得更开(图3c)。相对的,异常点及其转换之后的数据在Z空间中结构差异大,因此能够被检测出来(图3d)。

如上图4所示,是一个正常点的4个不同mask(mask是转换器里面的M函数)结果。可以看出,mask各不相同,分别关注原始数据的不同部分。说明满足了本文中不同转换器间不相似的要求。
改变n-vs-rest中正常类别数目的实验:
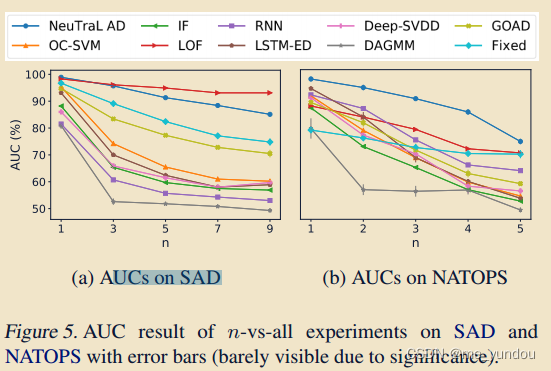
如上图5所示,通过在n-vs-rest 实验中增加正常数据的类别数目,异常检测的性能普遍下降。但是本文的方法显然优于其他方法,下降更为缓慢。
- 表格数据集上实验结果:
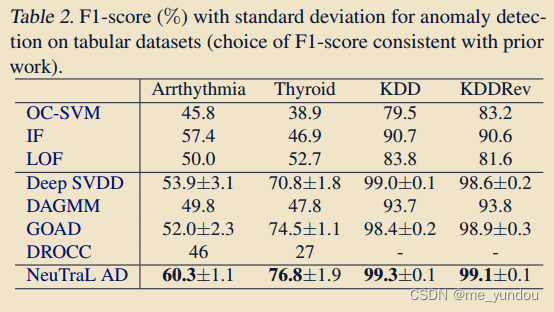
如上表2所示,在所有表格数据集上,本文模型都优于其他算法。
- 针对转换器的实验:

本文针对三种不同的转换器设计方式,分别是前馈的: ,残差连接的:
,相乘的:
,以及转换器数据 K 进行了实验,如上图6所示。从图中可以看出,当K<=4时,异常检测的性能差距较大,说明少量的转换器不足以覆盖数据的特征,而当转换器足够多时(K > 4),所学的转换器就包含足够多的有效特征了。
参考文献:
[1] Wang, S., Zeng, Y., Liu, X., Zhu, E., Yin, J., Xu, C., and Kloft, M. Effective end-to-end unsupervised outlier detection via inlier priority of discriminative network. In Advances in Neural Information Processing Systems, pp. 5962–5975, 2019b
个人理解和问题:
1.本文模型设计的可学习转换器确实比人工设计的好,但是在针对不同数据集的时候,转换器的结构和层数也还是需要手动定义(比如针对时间序列数据的转换器是残差模块构成的,而表格数据的转换器是线性层构成的),这中间不是仍然有人工设计的成分吗?