今天,突然发现,selenium库不开万花筒的话,有点脑热,因为,每爬一页就打开一个网页,除非我是撕裂者3990X的CPU,64核,128线的,但是,我的CPU不是,所以,怕到时候打开页面太多,直接卡机废了。。我就去搜了开启万花筒模式,这样就更好了,直接爬数据不用打开浏览器页面。
这次案例的网址是:https://book.douban.com/tag/%E5%90%8D%E8%91%97?start=0&type=T
完整代码:
首先,我们先导入需要用到的库,selenium库和time库。然后,开启selenium的万花筒模式(无界面),即不打开网页就能爬取信息。所以有:

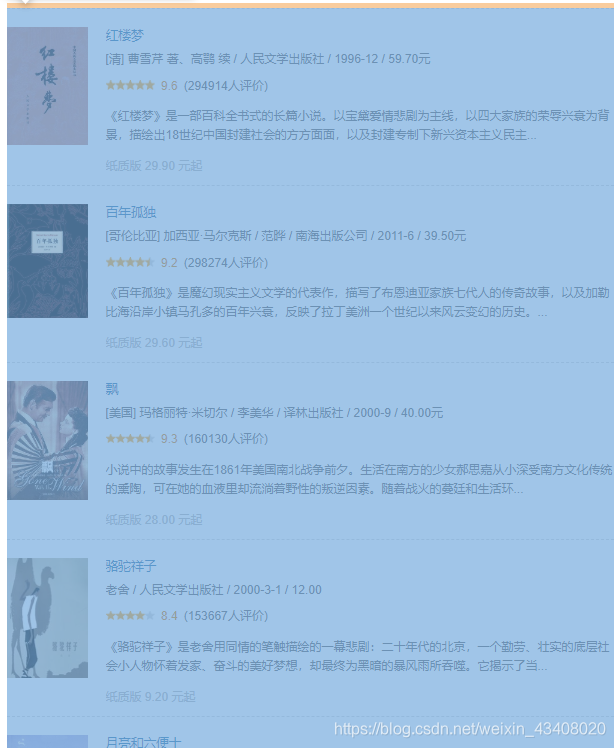
然后,我们观察url地址,发现,它的start值会随着翻页规律性增加,每次增加20,等到start值达到980的时候,停止增加,因为start=980的时候,就是最后一页了。所以,我们可以人为构造url地址,我们观察网页结构,发现通过提取ul标签,可以将整个页面的内容抓取下来,如下图:

所以有:
运行结果,随机抽取开头和结尾截图,剩下的就不截图了,请大家见谅。


接着,我们要给我们的工作留个纪念,要不然太亏了,我选择以csv的文件格式保存数据。修改代码,如下图:
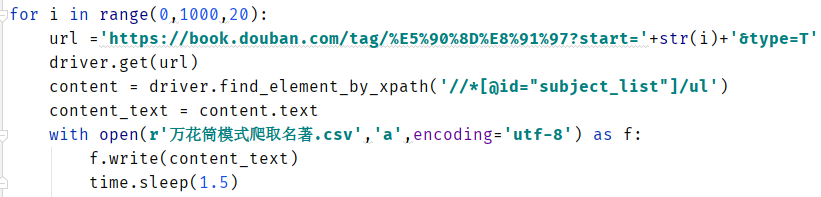
静等一小段时间后,运行结果:

去pycharm编辑器路径下面找到保存的文件,如下图:
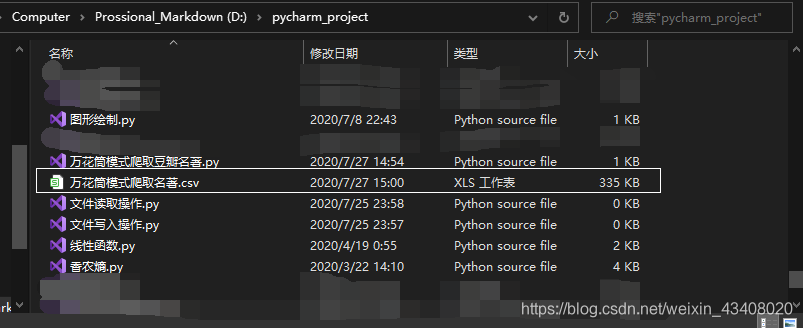
打开,如下图,数据太多不便截图,请大家谅解:


pycharm编辑器中打开文件,如下图,数据太多不便截图,请大家谅解:


过瘾,第一次爬了将近5000行的数据,就一个字,爽!!这次学会开启万花筒写轮眼,这将是我陷入万花筒不能自拔的开始。。。。
最后,感谢大家前来阅读鄙人的文章,文中或有诸多不妥之处,还望指出和海涵。