今天,晚上得好好复习了,因为白天又研究了一波爬虫,所以,有所收获,然后,发文纪念一下,顺便完成今天的发文任务,明天要考试了,所以,晚上得复习复习了。
我这里就默认看这篇文章的同志是已经装好selenium库的了(没有装好的同志可以看我上一篇博文有说),所以,接下来,我们直接上代码,我们这次的案例网址是:https://www.tmall.com/,我们先导入webdriver,再用get请求天猫网址。所以有:
我们先模拟天猫搜索框的搜索,把它的xpath路径提取下来,然后,再用函数driver.send_keys()来模拟输入内容,然后再把搜索按钮的xpath路径提取下来,再用**submit.click()模拟点击,之后,等待浏览器响应,用函数driver.implicitly_wait(3)**来设置等待时间为3秒。所以有:

接着,我们观察天猫网页结构,我们要提取当前页面的书籍信息,所以,我们检查xpath路径来进行对比,如下图:

我们发现规律,第一本书籍信息跟第二本书籍信息在xpath路径里面仅仅只是div的序号不一样,对应第一个和第二个。所以,我们可以自己构造xpath路径,来提取整个页面的书籍信息。所以有:

结果:
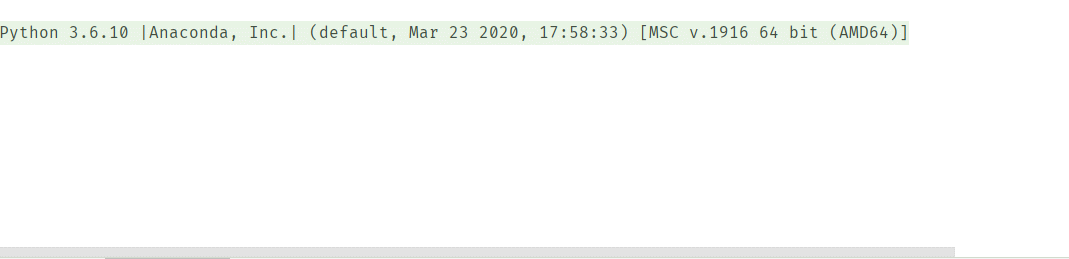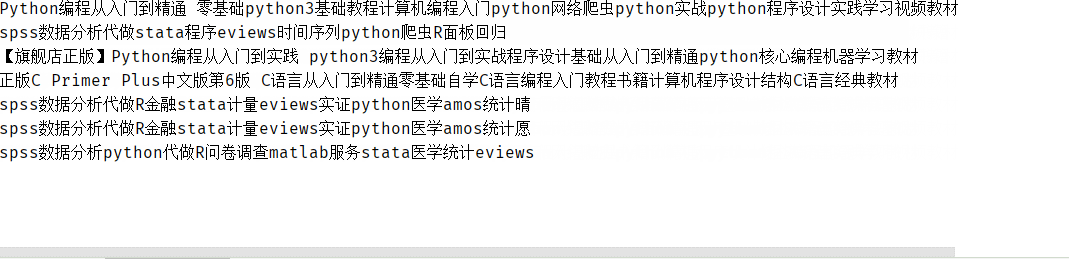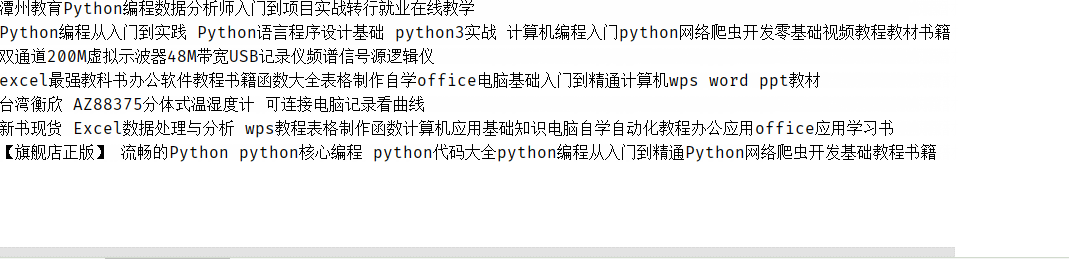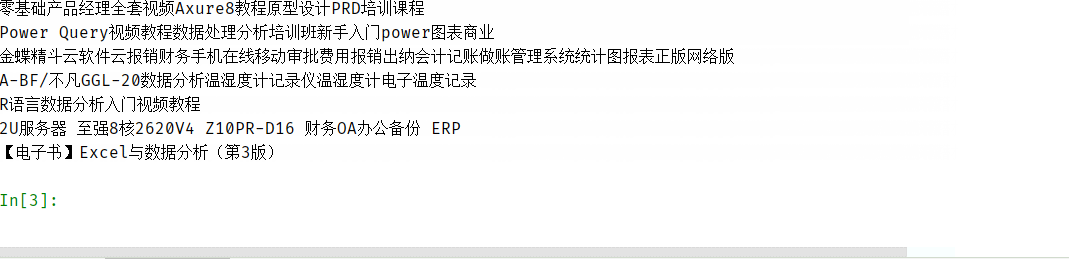
当然,我们还差最后一步,就是将爬取的数据保存到本地计算机中,所以,修改代码:

我保存的数据默认在pycharm编辑器路径下面,运行结果:

找到文件打开,如下图:

在pycharm编辑器打开如下图:

感觉很nice,又学到新的东西了,懂得selenium的webdriver基本操作。
最后,感谢大家前来阅读鄙人的文章,文中或有诸多不妥之处,还望指出和海涵。