这几天一直在想,如果浏览器能点进一个链接,然后,点击当前的页面的链接,又可以进入下一个页面,那么爬虫能不能实现呢?
我个人偏见,这是一个有意思的发现,我把这种爬取方式称为深入爬取,简单来说,就是我们写的爬虫,就像是浏览器去浏览网页一样,爬虫看见的东西,都可以爬下来,可以模拟人的行为,点击链接进去,获取链接的页面,然后,链接里面的链接页面内容也可以通过这种方式获取。这就像是生物学的细胞分裂,一个页面变出两个页面,两个页面变出四个,往复如此,直到最后一个页面的信息被提取完毕。这样,我们的爬虫就不再是单页面网页爬虫了,而是多页面网站爬虫。
现在,我的研究只到一个初期,还没有完全实现整个网站的爬取。只能实现特定链接进入后再爬取。接下来就跟大家分享一波。
本次案例的网址是 http://www.4399.com/
完整代码:
from selenium import webdriver
import urllib.request
from lxml import etree
import time
driver = webdriver.Chrome()
url = 'http://www.4399.com/'
driver.get(url)
driver.implicitly_wait(3)
for i in range(1,9):
xpath_road = '//*[@id="skinbody"]/div[7]/div[1]/div[1]/div/span['+str(i)+']/a'#第一行深度爬取试验
a_label = driver.find_elements_by_xpath(xpath_road)
for a in a_label:
a_text = a.text
print(a_text)
time.sleep(1.5)
next_href = a.get_attribute('href')
print(next_href)
want = str(input('是否深入爬取?'))
if want == '是':
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36 Edg/84.0.522.40'
}
request = urllib.request.Request(next_href,headers=headers)
response = urllib.request.urlopen(request)
html = response.read().decode('gb2312','ignore')
xpath_road2 ='//a/text()'
select = etree.HTML(html)
next_page_text = select.xpath(xpath_road2)
for t in next_page_text:
with open(r'4399深入爬取试验1.txt','a',encoding='utf-8') as f:
f.write(t+'\n')
elif want == '否':
break
else:
print('输入错误!!')
break
首先,我们写爬虫得导入所需要的库,这里,我选择selenium库,lxml库,urllib库。selenium是一款好用的测试工具,无界面浏览器,考虑网页的反爬机制。lxml是一款很不错的网页解析库,urllib是一款多功能的url库。这里,我同时还导入了time库,因为我们要控制爬取速度,要不然会耗费大量网络资源,占用其他用户的资源,严重可能导致网页崩溃,所以,这是一个道德问题。
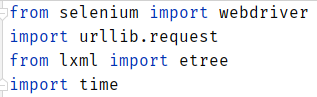
其次,我们先采用selenium打开网页,并设置响应时间为3秒。
执行结果,我们会看见如下页面:

接着,我开始尝试我的想法,先拿一个小行来试一下。现在,我选择专辑那一栏,

发现他们这些游戏名,对应的xpath标签,只是span的序号不一样,所以,我要进行提取的话,只需要构造span的序号。所以有:

接着我们要点击进去,所以,我们得先获取游戏名的超链接,根据selenium的函数,所以有:

运行结果,我们可以看见,对应游戏名的链接出来了。
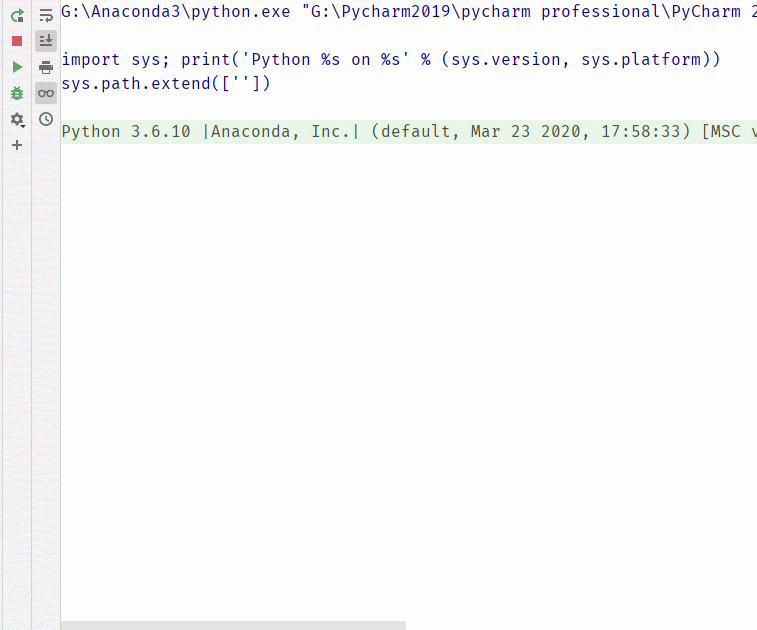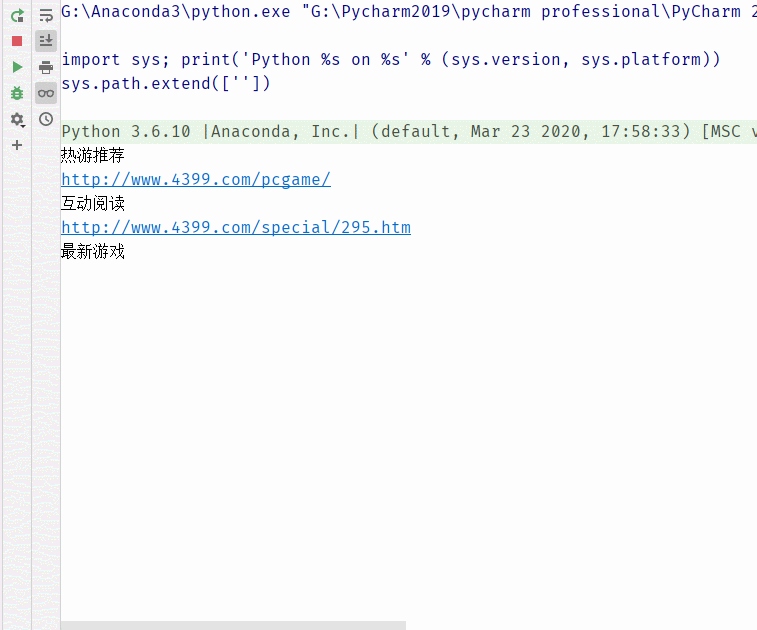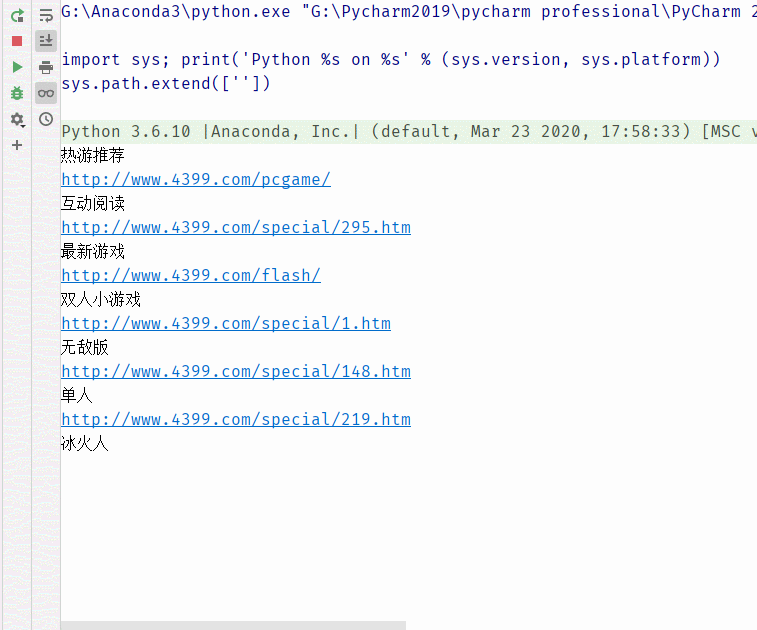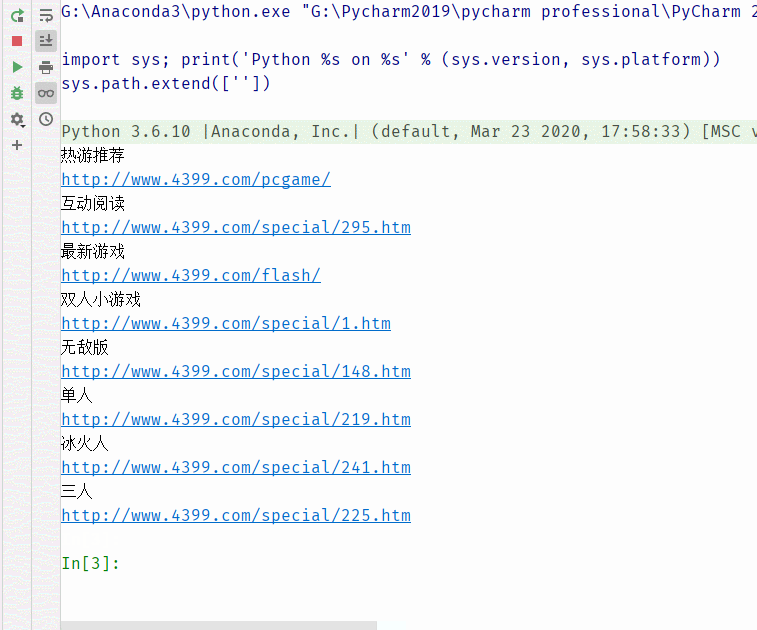
接着,我们就要开始试验我们的想法,我们获得了链接后,就开始用到lxml库和urllib库。跟我们以前说的基本操作一样,我们需要设置请求报头headers来模拟浏览器。之后,使用urllib.request.Request(),传递参数next_url和headers。之后,用urllib.request.urlopen(request)打开链接,网页响应后的源代码,查看网页编码后

再用response.read().decode(‘gb2312’)解码。然后,再创建select选择器,应用xpath方法提取当前页面的信息。提取的信息是以列表的形式返回,因此,需要for循环遍历,挨个打印输出信息。所以有:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36 Edg/84.0.522.40'
}
request = urllib.request.Request(next_href,headers=headers)
response = urllib.request.urlopen(request)
html = response.read().decode('gb2312','ignore')
xpath_road2 ='//a/text()'
select = etree.HTML(html)
next_page_text = select.xpath(xpath_road2)
for t in next_page_text:
print(t)
运行结果:

报错了,原因是字符集出错,上网查找了解决方法,修改代码如下:

运行结果,随机截取的图片,还有很多内容,我就不全部列出了,请大家见谅。

如果,仅仅只是让程序去自行爬取链接,不人为控制的话,貌似有些我不需要的信息也会爬取下来。因此,我们要设置一个可控的程序,我们想要哪个页面的信息,就爬取哪个页面的信息。添加if条件判断语句,来进行控制。所以有:
want = str(input('是否深入爬取?'))
if want == '是':
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36 Edg/84.0.522.40'
}
request = urllib.request.Request(next_href,headers=headers)
response = urllib.request.urlopen(request)
html = response.read().decode('gb2312','ignore')
xpath_road2 ='//a/text()'
select = etree.HTML(html)
next_page_text = select.xpath(xpath_road2)
for t in next_page_text:
with open(r'4399深入爬取试验1.txt','a',encoding='utf-8') as f:
f.write(t+'\n')
elif want == '否':
break
else:
print('输入错误!!')
break
运行结果,后面还有很多内容,我就不全部列出了,请大家见谅。

接着,我们给辛苦这么久的成果留个纪念。修改代码,所以有:

运行结果:

打开文件4399深入爬取试验1.txt,如下图:

后面还有很多内容,我就不全部截图了,请大家见谅。
在pycharm编辑器中打开文件,如下图:

我们现在通过这个试验,我个人偏见,爬取整个网站信息的爬虫应该是能够研发出来的,但是,仍需考虑多种因素,网页编码,网页的类型,等等问题。我后面的文章,会引入简单的数据去重。
最后,感谢大家前来观看鄙人的文章,文中或有诸多不妥之处,还望指出和海涵。