今天,又是个美好的一天,我因为开始自学爬虫,所以就顺便看看爬虫重修群的作业(当然我没有挂科),我觉得这次作业还有一些意思,所以,我自己就解决了这次作业。
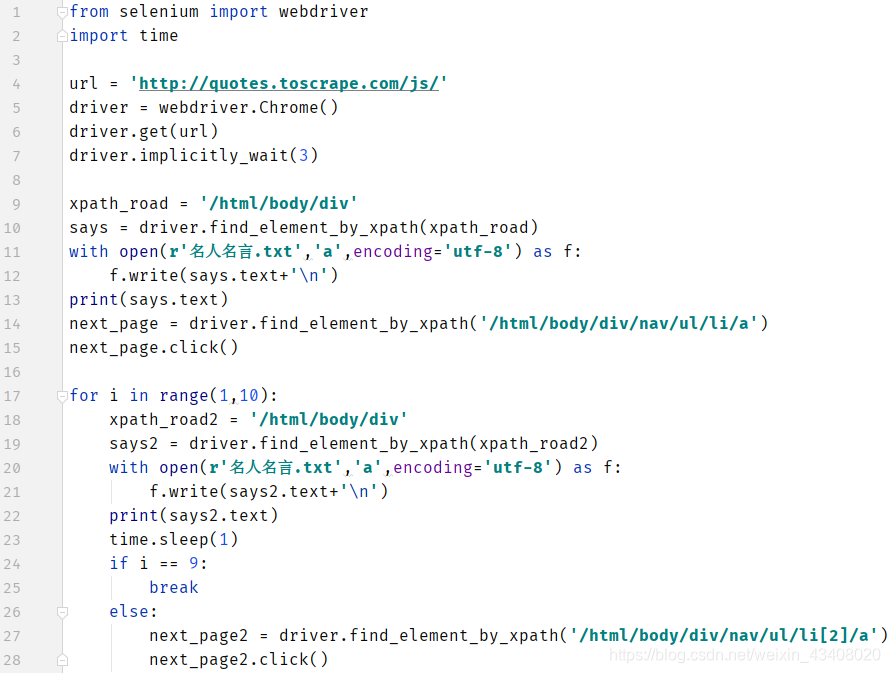
完整代码其实也就20多行左右:
我们这次的案例,不是我自己想的,是老师的作业,网址是:http://quotes.toscrape.com/js/,我们先进去看一下,如下图所示:

然后,我们往后翻页,发现它这个页数是固定的,只有10页就翻完了。所以,我们可以利用这个特点。首先,先导入我们会用到的库,selenium和time。如下图:

接着,将案例网址的url传递给driver.get()进行get请求。再等待浏览器响应,如下图:

接着,我们就需要去查看网页结构,了解网页结构,才能确定我们爬取的方向和构造方向。如下图:

这里,我发现这里有个方便的提取方法,直接将整个页面提取下来,省去一个个用循环提取,也可以降低时间复杂度,能不用循环就不要用。所以,我这里选择的提取对象是div标签。接着,我们观察网页发现,它底下有个链接next,我们提取完一个页面信息后,需要模拟点击next进入下一个页面,再提取当前页面的信息,这样就能实现翻页提取了,如下图:

但是,因为翻页你会发现一个问题,就是翻页后,它会自动生成一个往前翻页的按钮,我们如果单纯的只是用next_page = driver.find_element_by_xpath(‘html/body/div/nav/ul/li/a’),那肯定是行不通的,所以,第一个既然是一个特例,我就选择把它单独拿出来,剩下的页面都是遵循同一种规律next_page2 = driver.find_element_by_xpath(’/html/body/div/nav/ul/li[2]/a’),因此就可以用循环解决。如下图:

运行结果:


后面还很多,我就不全部列出了,请大家见谅,不过,大家自己做的话,不出意外的话,跟我的效果应该是一样的,接下来,我们就要将数据保存到我们自己的本地计算机中了,做的这么辛苦,边想边做边改,搞了好几个小时的成果,可不能让它就这样打水漂,要不然太亏了,哈哈。所以,修改代码如下图:

运行结果:
在pycharm编辑器路径下找到名人名言.txt文件打开。

在pycharm编辑器打开名人名言.txt文件。

对比网页每页上的内容,都是一致的。

因为,文件打开内容过多,不便于截图,所以仅仅展示一些图片,大家可以自行尝试一下。
最后,感谢大家前来观看鄙人的文章,文中或有诸多不妥之处,还望指出和海涵。