今天先把昨天的发文补上再说,昨天在搞Flask框架搭建,并且尝试批量爬取视频,遇到了一些坑,跟大家分享一下。
这次我们案例的网址是:
https://haokan.baidu.com/v?vid=13433481203252935978&pd=bjh&fr=bjhauthor&type=video。
我们进去后,会看见如下画面:

我们这次要做的是要把旁边列表中的视频爬取下来,完整代码如下:
from selenium import webdriver
from bs4 import BeautifulSoup
from lxml import etree
import urllib.request
import requests
import time
import re
import os
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--disable-gpu')
driver = webdriver.Chrome(options=options)
#爬取象棋视频列表
url = 'https://haokan.baidu.com/v?vid=13433481203252935978&pd=bjh&fr=bjhauthor&type=video'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36 Edg/84.0.522.50'
}
driver.get(url)
driver.implicitly_wait(3)
html = driver.page_source
select = etree.HTML(html)
half_href = 'https://haokan.baidu.com/'
for i in range(1,21):
video_half_href = select.xpath('//*[@id="rooot"]/div/div[2]/div[2]/ul/li['+str(i)+']/a/@href')
href = half_href + video_half_href[0]
video_name = select.xpath('//*[@id="rooot"]/div/div[2]/div[2]/ul/li['+str(i)+']/@title')[0]
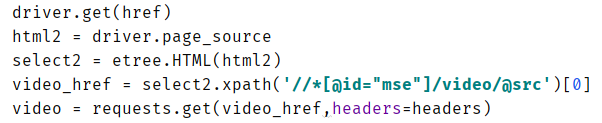
driver.get(href)
html2 = driver.page_source
select2 = etree.HTML(html2)
video_href = select2.xpath('//*[@id="mse"]/video/@src')[0]
video = requests.get(video_href,headers=headers)
#print(video_name)
#print(href)
#print(video_href)
#time.sleep(1.5)
with open('E:/video/{}.avi'.format(video_name),'wb+') as f:
f.write(video.content)
time.sleep(1.5)
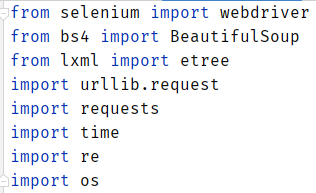
首先,我们导入可能会用到的各种库,如下图:
接着,我们开启万花筒模式,如下图:

然后,跟以前一样的老套路,将url地址和请求头设置好。代码如下:
url = 'https://haokan.baidu.com/v?vid=13433481203252935978&pd=bjh&fr=bjhauthor&type=video'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36 Edg/84.0.522.50'
}
接着,我们用driver.get()函数,发出get请求,请求网页,等待浏览器响应,响应时间设置为3秒,再将源代码传递给etree,创建select选择器。如下图:

之后,我们就要去观察网页结构了,找到右边的视频列表的第一个视频鼠标右击选择检查,或者按下键盘上的功能键F12,如下图:

我们发现视频的链接在a标签中,我们点击进去看一下,如下图:

但是,我们发现如果根据这个a标签来提取链接就会出现一个问题,如下图:

结果:

只有半截地址,所以,我们要去构造地址,我们去观察它的url地址,发现规律:


只要在前面加上:https://haokan.baidu.com/,就行了。
如下图:

结果,出现了我们想要的完整地址:

接下来,我们去观察列表的最后一个视频地址的xpath路径,对比一下,如下图:

我们发现,只是li标签的序号不同,所以,我们可以根据for循环构造视频所在的页面url地址。如下图:

结果:

接着,我们要获取视频的页面地址,所以,我们去观察网页发现,如下图:

在video标签里面的地址,把它复制下来去浏览器里面打开发现是我们需要的视频地址,所以有:
我们请求获取到的地址,然后,构造选择器select2来获取视频video标签内的属性,也就是视频地址。如下图:

结果,下来还有一些内容,就不全部截图了,请大家见谅:

现在我们已经获取到视频的地址了,还差视频的名称,我们还是去观察网页结构,如下图:

我们发现,我们想要的视频名称在li标签中的属性title里面,我们要提取title标签。所以,我们在起始页面,用xpath方法来提取title属性,如下图:

结果:

我们用requests.get()请求视频地址,然后获得视频内容,如下图:
我们现在万事具备,只欠东风,我先在E盘创建一个文件夹(目录)video,用来存放视频。所以有:

结果,在E盘自动创建了一个video文件夹(目录):

再以二进制的形式写入视频,文件名对应视频的标题名,文件格式是avi视频格式,用格式化字符串的方法(format方法),每执行一次休息1.5秒钟,所以有:

等待一段时间后,运行结果:


我们随便打开一个看一下,如下图:

最后,感谢大家前来观看鄙人的文章,文中或有诸多不妥之处,还望指出和海涵。