今天,在研究BeautifulSoup库的使用方法和技巧,我看了一下BeautifulSoup库函数,觉得BeautifulSoup库没有lxml库的xpath函数那么好用,各有优势吧。
案例网址:https://zhidao.baidu.com/question/877231635748319892.html。
完整代码:
from bs4 import BeautifulSoup
import lxml
import urllib.request
import time
url = 'https://zhidao.baidu.com/question/877231635748319892.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36 Edg/84.0.522.48'
}
request = urllib.request.Request(url,headers=headers)
response = urllib.request.urlopen(request)
html = response.read().decode('gbk')
soup = BeautifulSoup(html,'lxml')
contents = soup.find_all('p')
for c in contents:
if c.string != None:
print(c.string)
with open(r'waiting_for_love.txt','a',encoding='utf-8') as f:
f.write(c.string+'\n')
time.sleep(1.5)
else:
continue
首先,我们要先去安装BeautifulSoup库(因为是第三方库,不是标准内置库),输入命令:

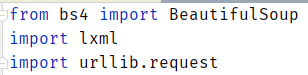
然后,正式开始我们的程序设计,导入会用到的库。这里我选择三个库联合使用,
我认为这样做会更好一点。
我们设置好url和请求报头,所以有:
url = 'https://zhidao.baidu.com/question/877231635748319892.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36 Edg/84.0.522.48'
}
request = urllib.request.Request(url,headers=headers)
接着,我们要把设置好的url和请求报头作为urlopen函数的参数传入,并读取源代码,再解码,我们在解码前,先去查看它的编码方式,如下图:

所以有:

之后,因为我们这次主要使用BeautifulSoup,因此,设置soup,并将解码后的html传递给soup,然后,设置lxml解析库为参数,目的是为了加快解析速度。所以有:
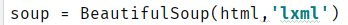
接着,我们开始爬取A神的歌词吧。先去查看网页结构进行分析。

通过观察,我们发现大部分内容都在p标签中。所以,确定爬取目标开始设计。用find_all()函数找出所有p标签,得到的结果是一个列表,
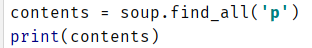
如下图:

所以,我们要用for循环遍历,然后打印输出结果,

如下图:

我们会发现结果存在空值None,因此,我们要在程序上再改进一下,让空值不出现。所以有:

如下图:

下面,我们再重新观察一下网页结构,然后,我们发现还有另一种方法。但是,我个人不推荐这种方法,因为页面通常是变动的。我们直接去找到div框架的标签,找到它的属性ID,然后,输出这个div标签下的文本内容。所以有:

如下图:

这个方法有明显的缺陷,目前原因尚未清楚,出现了莫名其妙的数字。
我们既然爬取A神的歌词,就留个纪念吧,好歹也辛苦这么久了。修改代码,再加入时间库,控制爬行速度,所以有:

运行结果:
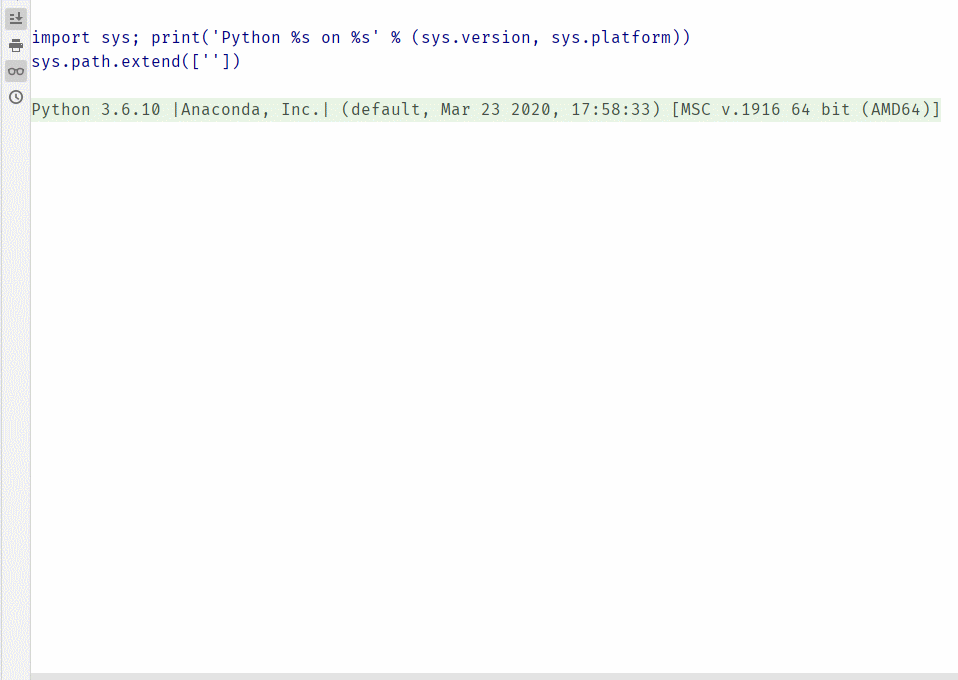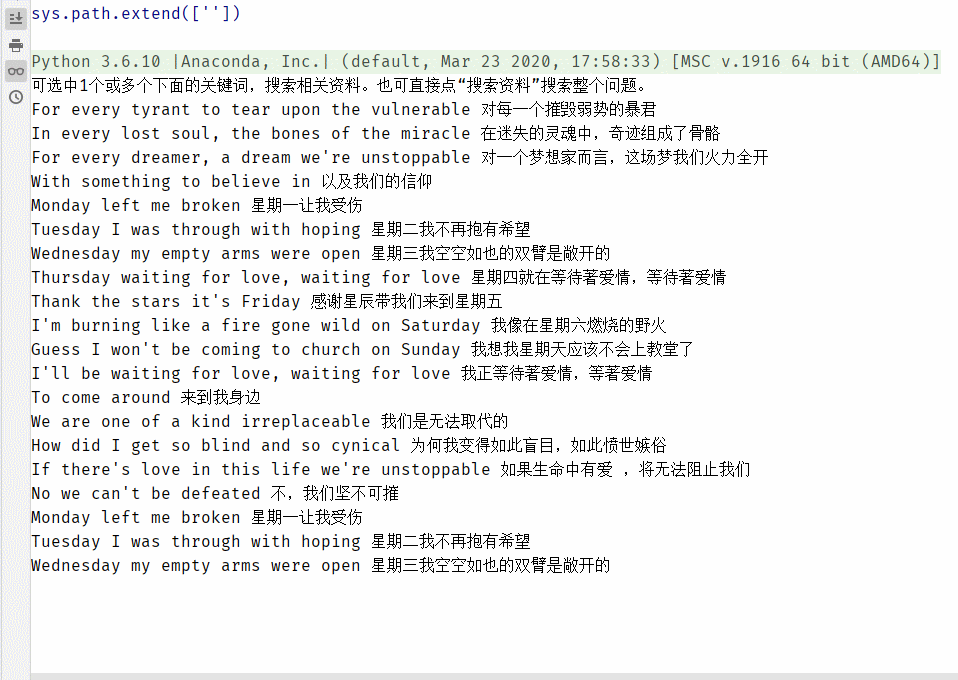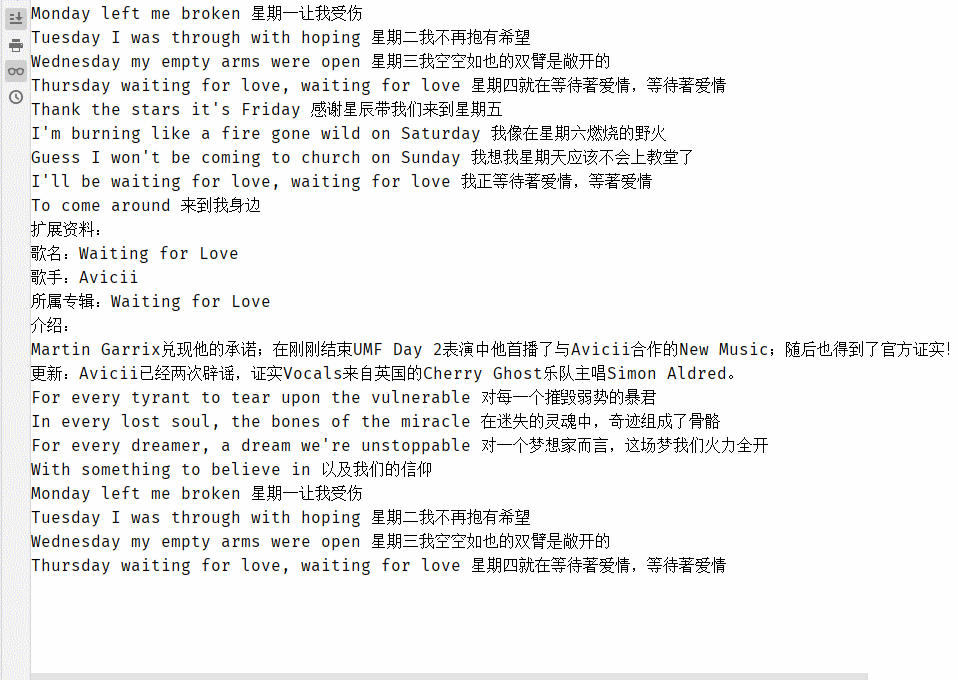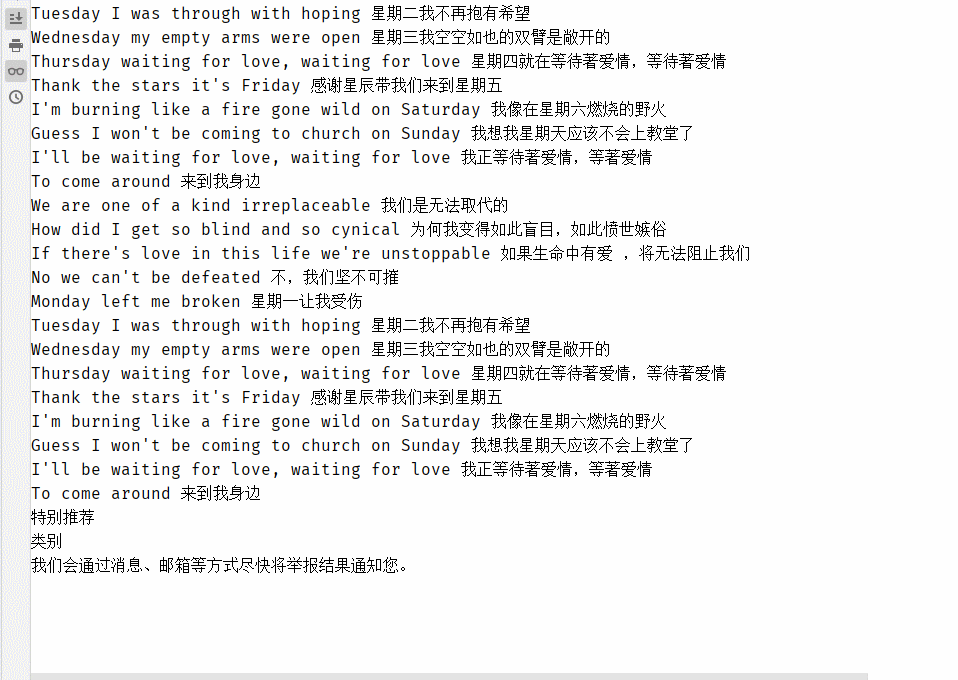
接着,我们去pycharm编辑器的路径下面,找到文件,打开文件看看,如下图:
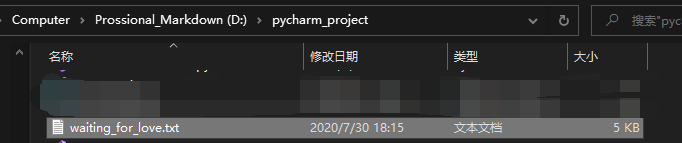
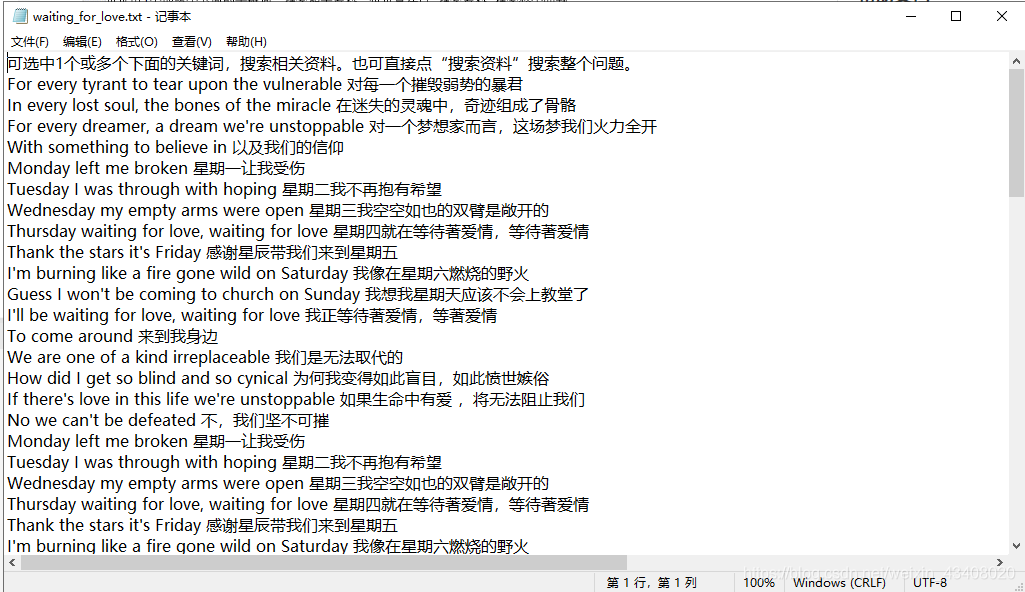
后面还有很多内容,就不全部截图了,请大家见谅。
最后,感谢大家前来观看鄙人的文章,文中或有诸多不妥之处,还望指出和海涵。