今天,我刚刚爬取成功经典老歌《皇后大道东》,现在正在听,很舒服,喜欢老歌的朋友可以跟我一起来爬取老歌,我们每一天都有新的东西,每一天都会比昨天进步一点,我想这就足够了。
此次案例的网址是:http://www.jdlg.net/baolijinjingdianlaoge/A925.html。
完整代码:
from selenium import webdriver
from lxml import etree
import requests
import time
import re
import os
def download_music():
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--disable-gpu')
driver = webdriver.Chrome(options=options)
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36 Edg/84.0.522.50'
}
url = 'http://www.jdlg.net/baolijinjingdianlaoge/A925.html'
driver.get(url)
html = driver.page_source
reg = r'var firstplay="(.*?)"'
music_href_list = re.findall(reg,html)
href = music_href_list[0]
music_name = driver.find_element_by_xpath('//*[@id="play_title"]').text
music = requests.get(href,headers=headers)
#print(music_name)'//*[@id="type01"]/ol/li[1]/a[1]'
#'//*[@id="type01"]/ol/li[12]/a[1]'
os.mkdir('E:/music')
with open('E:/music/{}.mp3'.format(music_name),'wb+') as f:
f.write(music.content)
download_music()
我们进入网页后,看见如下画面:

然后,跟以前一样的套路,分析网页结构,我们打开检查,或者是按键盘上的功能键F12,我们选择“元素”(Element),看见如下画面:

我们如果在这个页面去找标签,发现标签内没有音频内容,如下图:

但是,我们不必因此气馁,我们往下接着找,会发现,如下的JavaScript标签内有我们想要的音频内容,如图: 。
。
我们把它的这个地址复制到浏览器里面去搜索一下,如下图:

我们可以知道,这个就是我们要的音频地址,接下来明确目标后,就开始干!!干就完了!!撸起袖子加油干!!
首先,我们导入可能需要用到的库,如下图:
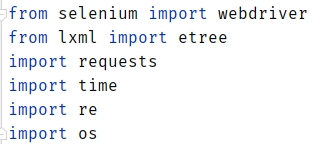
接着,我们要用工程性思维,自定义函数download_music,要尝试开始使用函数编写爬虫。所以有:
我们在函数体内,开始写爬虫代码,我们先开启万花筒模式,开启方法如下图:

然后,我们设置好url地址和headers请求报头。
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36 Edg/84.0.522.50'
}
url = 'http://www.jdlg.net/baolijinjingdianlaoge/A925.html'
接着,我们请求网页,并获得源代码:

然后,我们发现,音频地址在JavaScript里面,不能直接用xpath方法提取,我们使用正则提取。观察网页结构:

所以有:

然后,我们根据列表的下标来提取列表内的元素(音频地址),所以有:
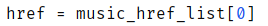
我们还需要给对应音频的名字作为文件名,所以,我们再观察网页,发现:

h1标签内有我们想要的歌名和歌手名。我们可以用xpath方法提取下来,所以有:
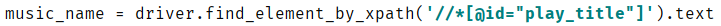
之后,我们现在文件名有了,音频地址也有了,所以,就差保存到本地计算机了,我们先用requests请求音频地址,再用os模块在E盘下创建一个music文件夹,把请求的音频以二进制写入文件,文件名为歌名和歌手名,保存在music文件夹下面。所以有:

调用函数:

运行结果,在E盘下找到music文件夹(目录)打开,如下图:

双击打开音频文件,如下:
现在正在听《皇后大道东》,过瘾。
最后,感谢大家前来观看鄙人的文章,文中或有诸多不妥之处,还望指出和海涵。