本博客内容来源于:
《Python数据分析与应用》第6章使用sklearn构建模型,侵请删
相关网站链接
一、P174 任务一:使用sklearn实现数据处理和降维
1、读取sklearn中自带的波士顿数据集
2、用train_test_split()划分数据集
3、标准差标准化
4、PCA降维
sklearn模块小记:
1、数据获取模块:sklearn.datasets
2、模型选择模块:sklearn.model_selection
3、数据预处理模块:sklearn.preprocessing
4、特征分解模块:sklearn.decomposition
# 代码 6-6 获取sklearn数据
import numpy as np
from sklearn.datasets import load_boston
boston = load_boston()
print(boston.keys())
boston_data = boston['data']
boston_target = boston['target']
boston_names = boston['feature_names']
print('boston数据集数据的形状为:',boston_data.shape)
print('boston数据集标签的形状为:',boston_target.shape)
print('boston数据集特征名的形状为:',boston_names.shape,"\n")
# 代码 6-7 划分数据
from sklearn.model_selection import train_test_split
boston_data_train, boston_data_test, \
boston_target_train, boston_target_test = \
train_test_split(boston_data, boston_target,
test_size=0.2, random_state=42)
print('训练集数据的形状为:',boston_data_train.shape)
print('训练集标签的形状为:',boston_target_train.shape)
print('测试集数据的形状为:',boston_data_test.shape)
print('测试集标签的形状为:',boston_target_test.shape,"\n")
# 代码 6-8 标准差标准化
from sklearn.preprocessing import StandardScaler
stdScale = StandardScaler().fit(boston_data_train) #生成规则
boston_trainScaler = stdScale.transform(boston_data_train)
boston_testScaler = stdScale.transform(boston_data_test)
print('标准差标准化后训练集数据的方差为:',np.var(boston_trainScaler))
print('标准差标准化后训练集数据的均值为:',np.mean(boston_trainScaler))
print('标准差标准化后测试集数据的方差为:',np.var(boston_testScaler))
print('标准差标准化后测试集数据的均值为:',np.mean(boston_testScaler),"\n")
# 代码 6-9 PCA降维
from sklearn.decomposition import PCA
pca = PCA(n_components=5).fit(boston_trainScaler) ## 生成规则
boston_trainPca = pca.transform(boston_trainScaler)
boston_testPca = pca.transform(boston_testScaler)
print('降维后boston数据集数据测试集的形状为:',boston_trainPca.shape)
print('降维后boston数据集数据训练集的形状为:',boston_testPca.shape)




Sklearn中关于数据预处理部分具有高度集成化的特点,使用起来特别方便!
通过简单的语句和少量的参数控制,就能实现划分数据集、标准化、降维的操作,对于使用者来说,提供了巨大的便利!
标准化的均值应该为0,在本例中,虽然训练集标准化后的均值不为0,但实际已经是一个很小的数字了,可以认为其结果已经为零了!
二、P182 任务二:构建聚类模型
数据集见上面给的那个链接(有点麻烦就是了)
# 代码 6-15
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
seeds = pd.read_csv('./第六章 实验数据/任务数据/data/seeds_dataset.txt',sep = '\t')
print('数据集形状为:', seeds.shape)
## 处理数据
seeds_data = seeds.iloc[:,:7].values
seeds_target = seeds.iloc[:,7].values
sees_names = seeds.columns[:7]
stdScale = StandardScaler().fit(seeds_data)
seeds_dataScale = stdScale.transform(seeds_data)
##构建并训练模型
kmeans = KMeans(n_clusters = 3,random_state=42).fit(seeds_data)
print('构建的KMeans模型为:\n',kmeans)
# 代码 6-16
from sklearn.metrics import calinski_harabaz_score
for i in range(2,7):
##构建并训练模型
kmeans = KMeans(n_clusters = i,random_state=12).fit(seeds_data)
score = calinski_harabaz_score(seeds_data,kmeans.labels_)
print('seeds数据聚%d类calinski_harabaz指数为:%f'%(i,score))
#'''聚类训练集采用的是标准化之后的数据测试
'''
from sklearn.metrics import calinski_harabaz_score
for i in range(2,7):
##构建并训练模型
kmeans = KMeans(n_clusters = i,random_state=12).fit(seeds_dataScale)
score = calinski_harabaz_score(seeds_target,kmeans.labels_)
print('seeds数据聚%d类calinski_harabaz指数为:%f'%(i,score))
#会报错,原因暂时不知(或者说,时而报错时而不报错!)
'''
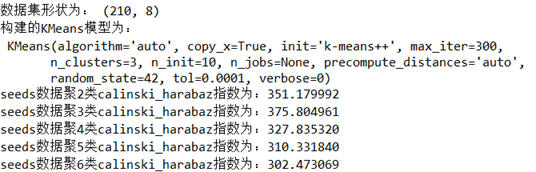
通过分析本题calinski_harabaz指数的结果可知:当数据聚类为3类的时候,其calinski_harabaz指数最大,聚类效果最好,符合任务背景的介绍!
三、P188 任务三:构建SVM分类模型
# 代码 6-22
import pandas as pd
from sklearn.svm import SVC
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
abalone = pd.read_csv('./第六章 实验数据/任务数据/data/abalone.data',sep=',')
## 将数据和标签拆开
abalone_data = abalone.iloc[:,:8]
abalone_target = abalone.iloc[:,8]
## 哑变量处理
sex = pd.get_dummies(abalone_data['sex'])
abalone_data = pd.concat([abalone_data,sex],axis = 1 )
abalone_data.drop('sex',axis = 1,inplace = True)
## 划分训练集,测试集
abalone_train,abalone_test, \
abalone_target_train,abalone_target_test = \
train_test_split(abalone_data,abalone_target,
train_size = 0.8,random_state = 42)
## 标准差标准化
stdScaler = StandardScaler().fit(abalone_train)
abalone_std_train = stdScaler.transform(abalone_train)
abalone_std_test = stdScaler.transform(abalone_test)
## 建模
svm_abalone = SVC().fit(abalone_std_train,abalone_target_train)
print('建立的SVM模型为:','\n',svm_abalone)
# 代码 6-23 输出分类报告
abalone_target_pred = svm_abalone.predict(abalone_std_test)
print('abalone数据集的SVM分类报告为:\n',
classification_report(abalone_target_test,abalone_target_pred))


SVM分类报告显示每个类别的精确率、召回率和F1值,其中对鲍鱼年龄为4预测比较好之外,其他的预测结果欠佳。进一步研究可以采用优化数据集、修改SVM核函数等方式来进一步提升准确率。
四、P194任务四:构建回归模型
# 代码 6-27
import pandas as pd
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.model_selection import train_test_split
house = pd.read_csv('./第六章 实验数据/任务数据/data/cal_housing.data',sep=',')
house_data = house.iloc[:,:-1]
house_target = house.iloc[:,-1]
house_names = ['longitude','latitude',
'housingMedianAge', 'totalRooms',
'totalBedrooms','population',
'households', 'medianIncome']
house_train,house_test,house_target_train,house_target_test = \
train_test_split(house_data,house_target,
test_size = 0.2, random_state = 42)
GBR_house = GradientBoostingRegressor().fit(house_train,house_target_train)
print('建立的梯度提升回归模型为:','\n',GBR_house)
# 代码 6-28
house_target_pred = GBR_house.predict(house_test)
from sklearn.metrics import explained_variance_score,\
mean_absolute_error,mean_squared_error,median_absolute_error,r2_score
print('california_housing数据梯度提升回归树模型的平均绝对误差为:',
mean_absolute_error(house_target_test,house_target_pred))
print('california_housing数据梯度提升回归树模型的均方误差为:',
mean_squared_error(house_target_test,house_target_pred))
print('california_housing数据梯度提升回归树模型的中值绝对误差为:',
median_absolute_error(house_target_test,house_target_pred))
print('california_housing数据梯度提升回归树模型的可解释方差值为:',
explained_variance_score(house_target_test,house_target_pred))
print('california_housing数据梯度提升回归树模型的R方值为:',
r2_score(house_target_test,house_target_pred))


通过分析数据梯度回归树模型的平均绝对误差、均方误差和中值绝对误差,或许并不能直观看出本次构建模型的合理程度,但通过分析方差和R2的值可以看出,其结果都是较为接近1的,故本次的模型算的上是一个较为有效的回归模型!
