- 分类和聚类
- 分类:最终类别是确认的,把各样本分到已有的类别中
- 聚类:最终类别是未知的,把所有样本划分出最终类别
一、K-means聚类算法
1.1 K-means算法了解
-
算法流程(推荐使用流程图:更简洁,且能降低查重)
- 流程图绘制:亿图、PPT、Visio等软件均可
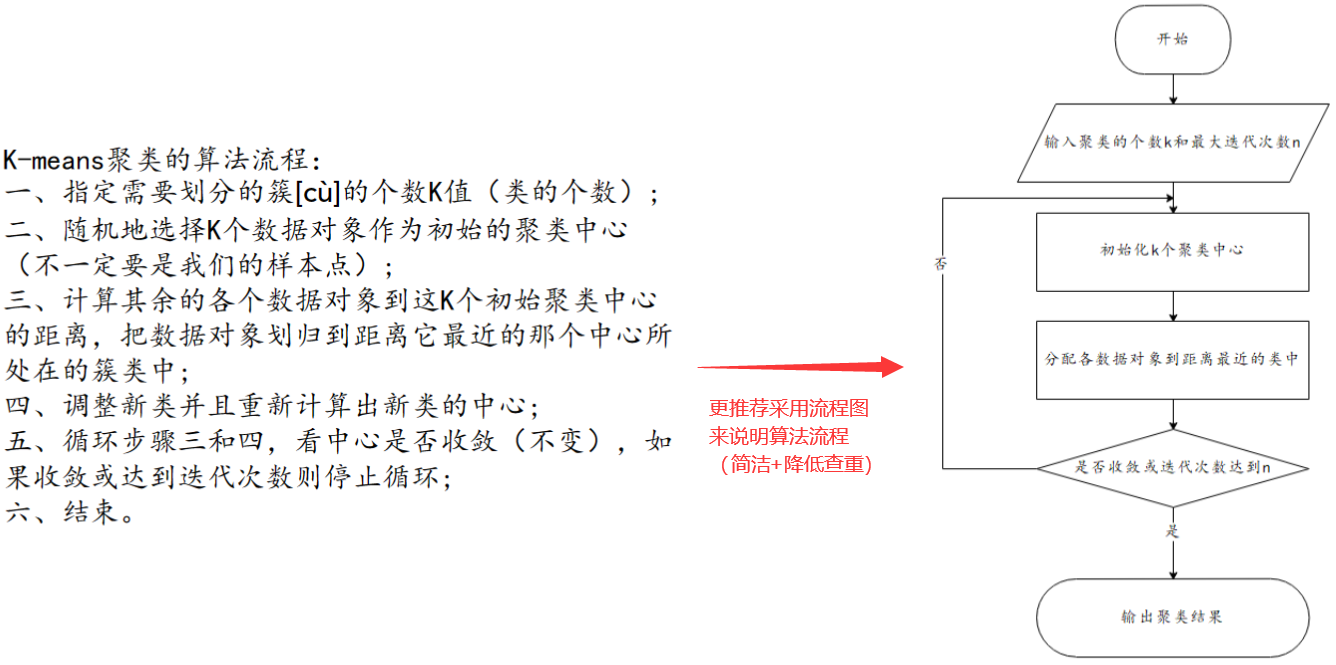
- 流程图绘制:亿图、PPT、Visio等软件均可
-
图解
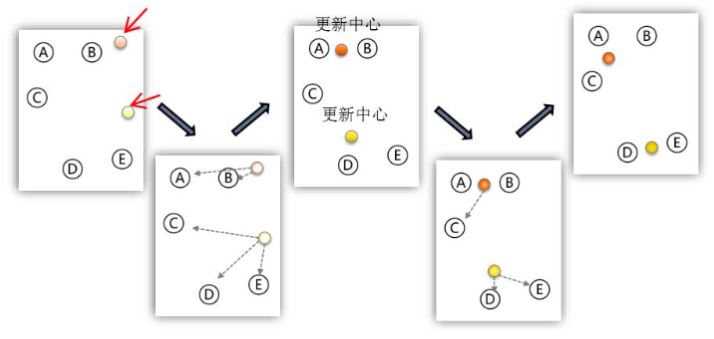
1.2 K-means算法评价
- 优点:
- ①算法简单、快速。
- ②对处理大数据集,该算法是相对高效率的。
- 缺点:
- ①要求用户必须事先给出要生成的簇的数目K。
- ②对初值敏感。
- ③对于孤立点数据敏感。
- ( ②和③能采用K-means++解决)
二、K-means++算法
2.1 K-means++算法了解
- 选择初始聚类中心的基本原则是:初始的聚类中
心之间的相互距离要尽可能的远。 - 算法流程:
- (只对K-means算法“初始化K个聚类中心” 这一步进行了优化)
- 步骤一:随机选取一个样本作为第一个聚类中心;
- 步骤二:计算每个样本与当前已有聚类中心的最短距离(即与最近一个聚类中心的距离),这个值越大,表示被选取作为聚类中心的概率较大;最后,用轮盘法(依据概率大小来进行抽选)选出下一个聚类中心;
- 步骤三:重复步骤二,直到选出K个聚类中心。选出初始点后,就继续使用标准的K-means算法了。
2.2 Spss实现K-means++
- 导入数据后的具体操作( 选中K-均值聚类,默认使用的就是K‐means++算法)
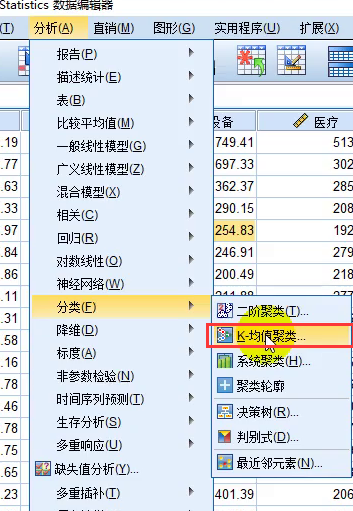
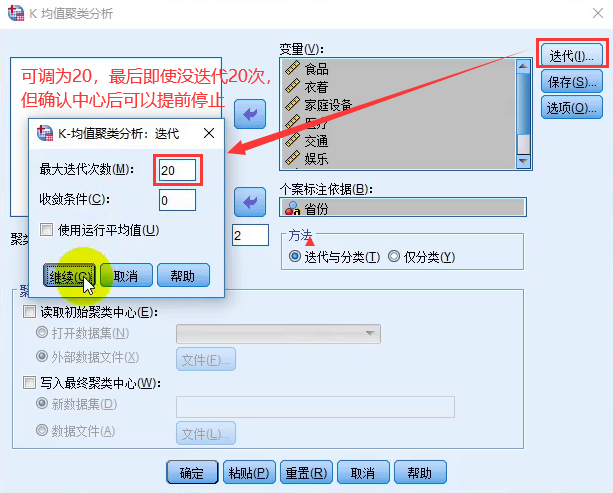
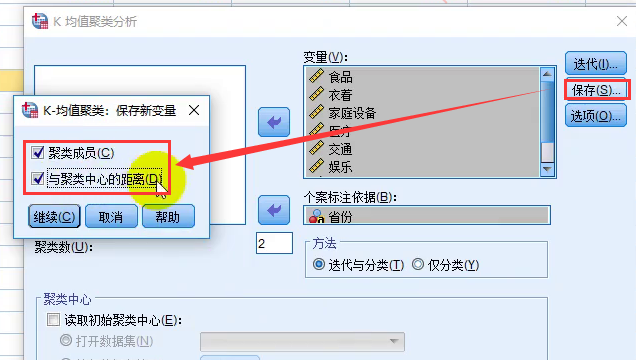
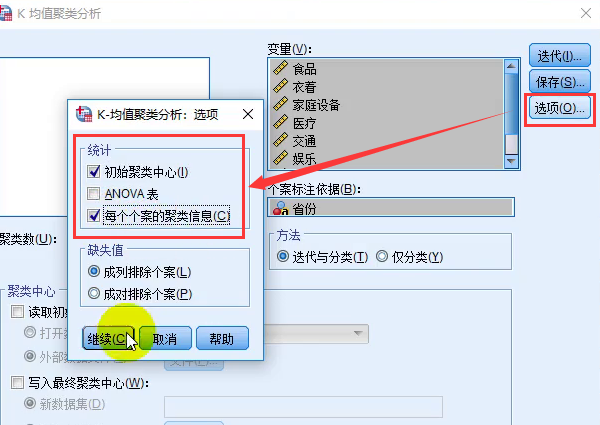
- 分析结果:
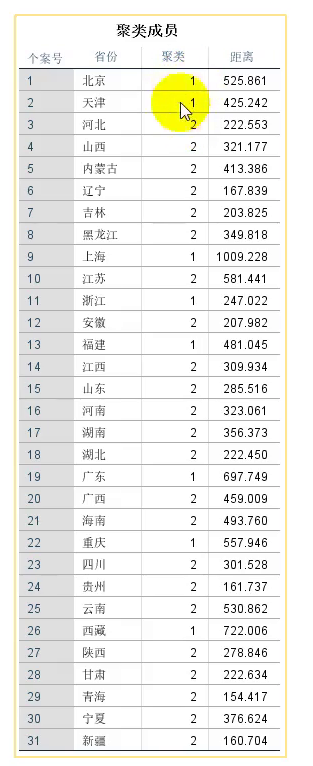
- ①聚类的结果
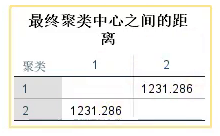
- ②分成k类后,k个聚类中心的距离
- ③各聚类中样本数
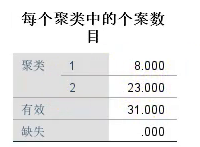
- ①聚类的结果
2.3 K-means算法的一些讨论
- ①聚类的个数K值怎么定?
- 答:分几类主要取决于个人的经验与感觉,通常的做法是多尝试几个K值,看分成几类的结果更好解释,更符合分析目的等。
- 例如:对消费群体分类,两类和三类都可以,因为分成两类可解释为高消费和低消费;分成三类可解释为高消费、中等消费和低消费。
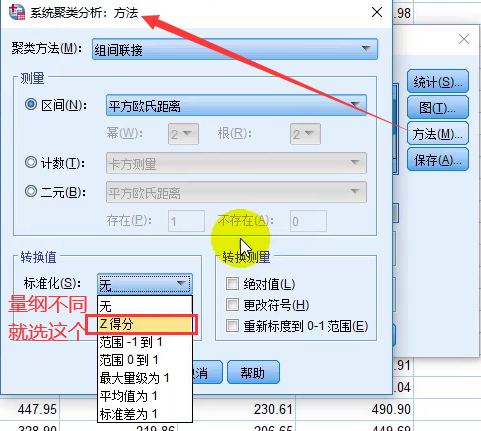
- ②数据的量纲不一致怎么办?
- 答:如果数据的量纲不一样,那么算距离时就没有意义。
- 例如:如果X1单位是米,X2单位是吨,用距离公式计算就会出现“米的平方”加上“吨的平方”再开平方,最后算出的东西没有数学意义,这就有问题了。
- 处理方式:

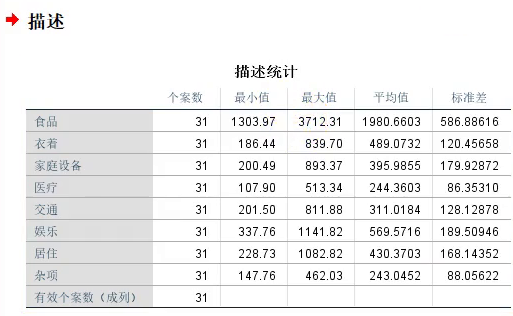
如下生成的描述性表格可放在论文中
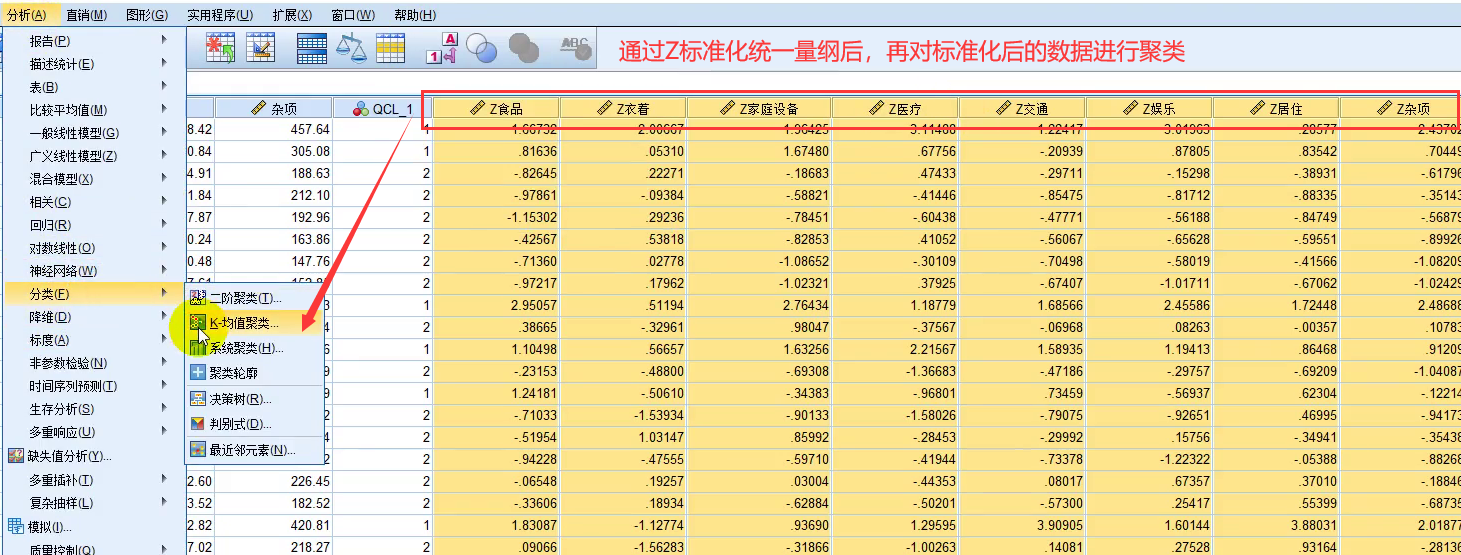
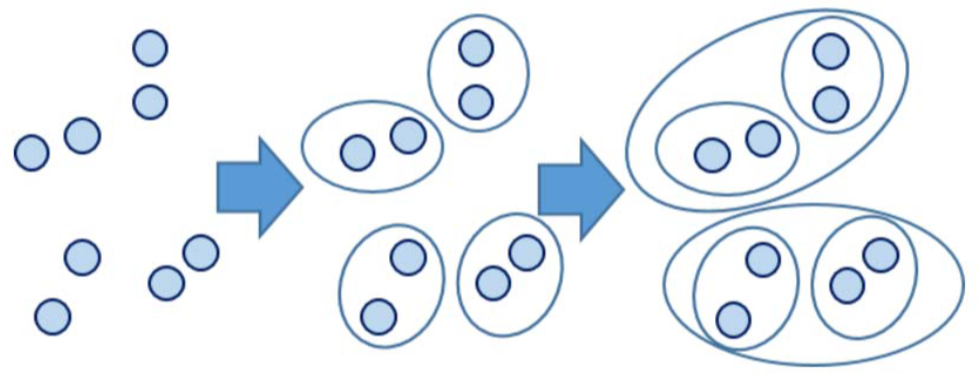
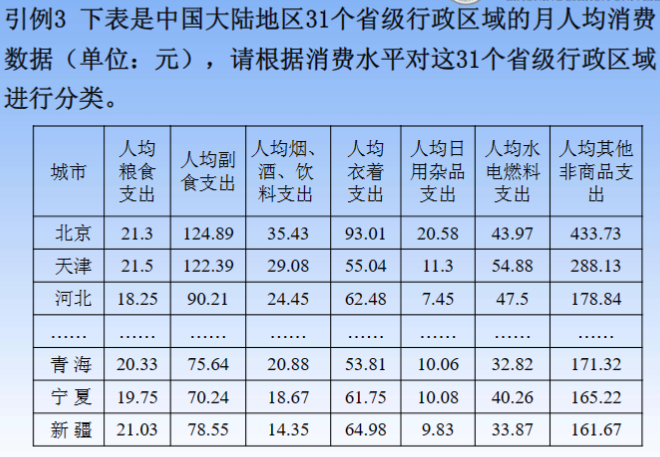
三、系统/层次聚类
- K-means聚类和K-means++聚类都需要实现人为设定最终聚类数,系统聚类则无需此步。
- 系统聚类的合并算法通过计算两类数据点间的距离,对最为接近的两类数据点进行组合,并反复迭代这一过程,直到将所有数据点合成一类,并生成聚类谱系图。
- (本节参考辽宁石油化工大学的教学pdf)
3.1 样品与样品之间的常用距离(样品i与样品j)
- 适用情况:
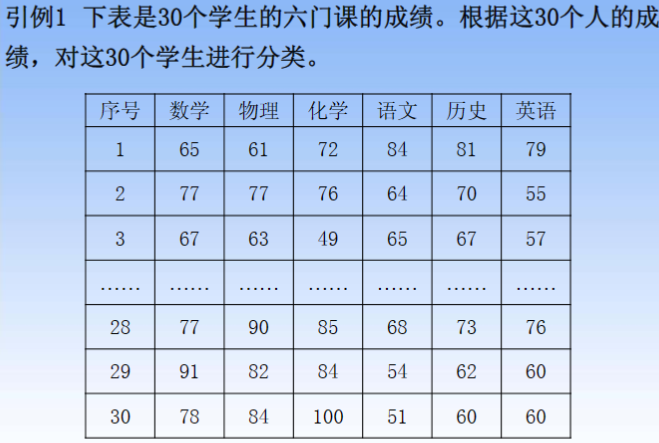
- 公式:
- 网格路径常用绝对值距离
- 其余常用欧氏距离

- 举例:

3.2 指标与指标之间的常用“距离”(指标i与指标j)
-
很少会有需要对指标进行分类的题目
-
适用情况:
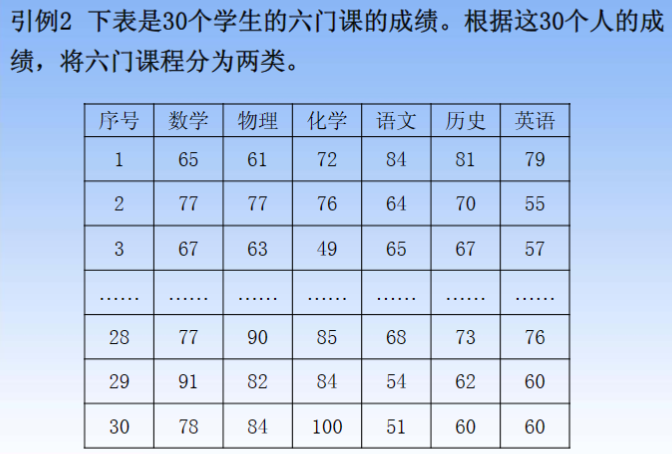
-
公式:
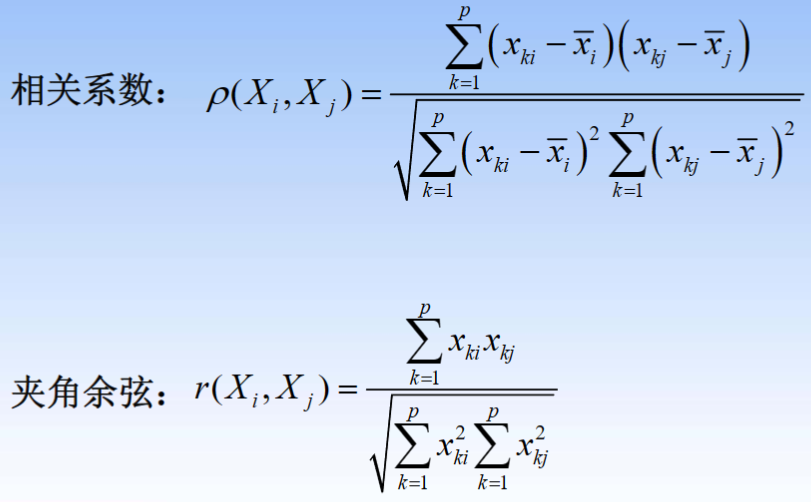
-
举例
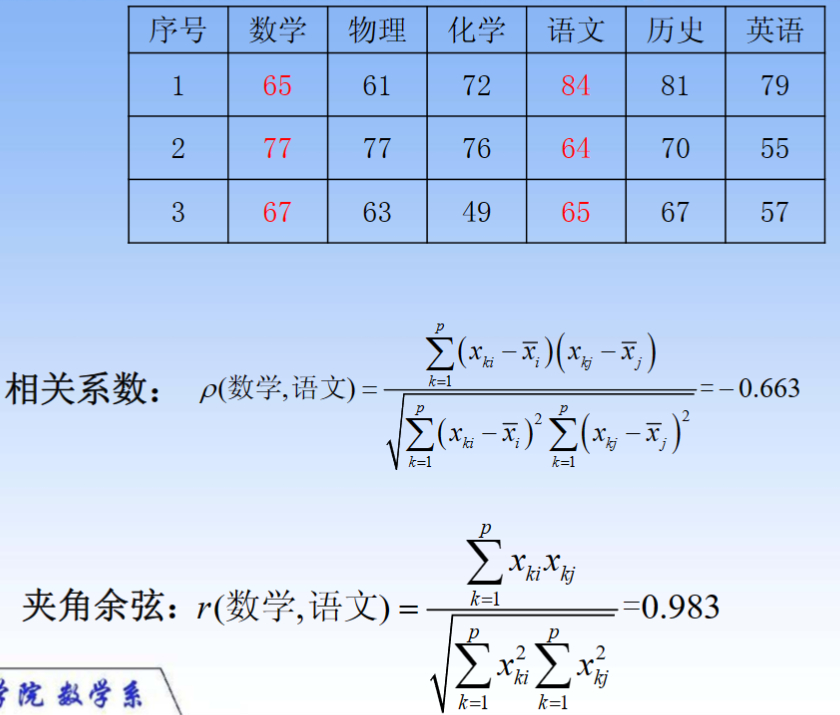
3.3 类与类之间的常用距离
-
适用情况:
-
1.由一个样品组成的类是最基本的类;如果每一类都由一个样品组成,那么样品间的距离就是类间距离。
-
2.如果某一类包含不止一个样品,那么就要确定类间距离,类间距离是基于样品间距离定义的,大致有如下几种定义方式:
- 默认的是重心法;
- 在系统聚类中组间和组内用的相对较多;
- (聚类方法选择都是多样的,只要能把模型解释得通即可)
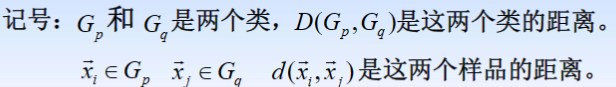
① 最短距离法
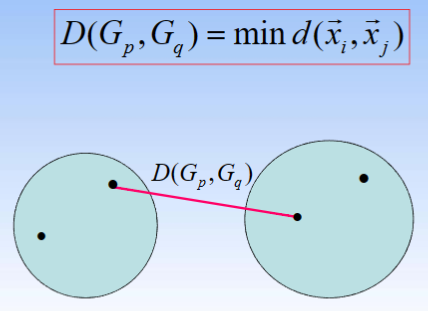
② 最长距离法
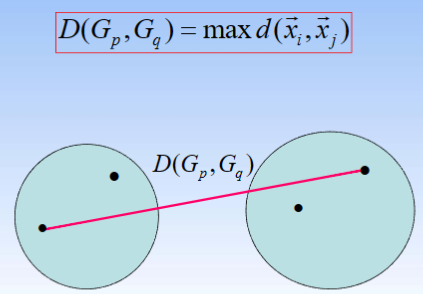
③ 组间平均连接法
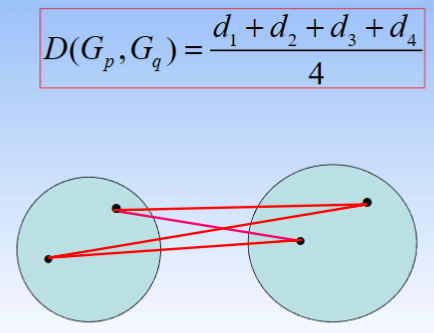
④ 组内平均连接法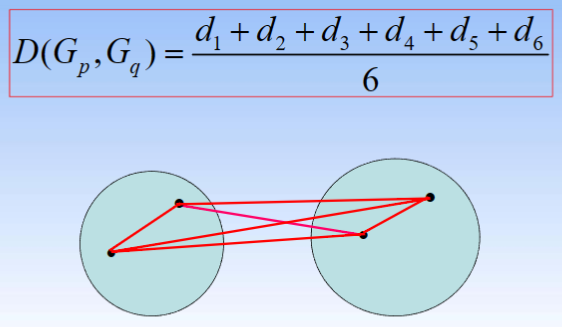
⑤ 重心法
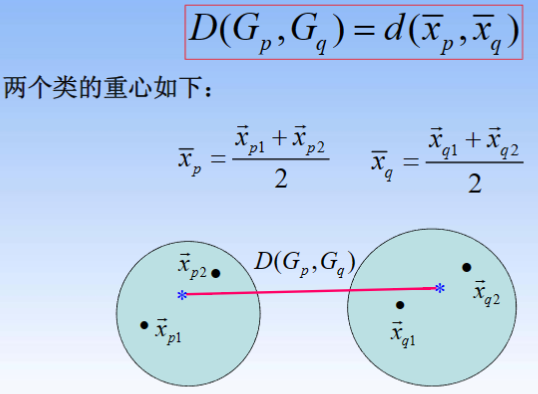
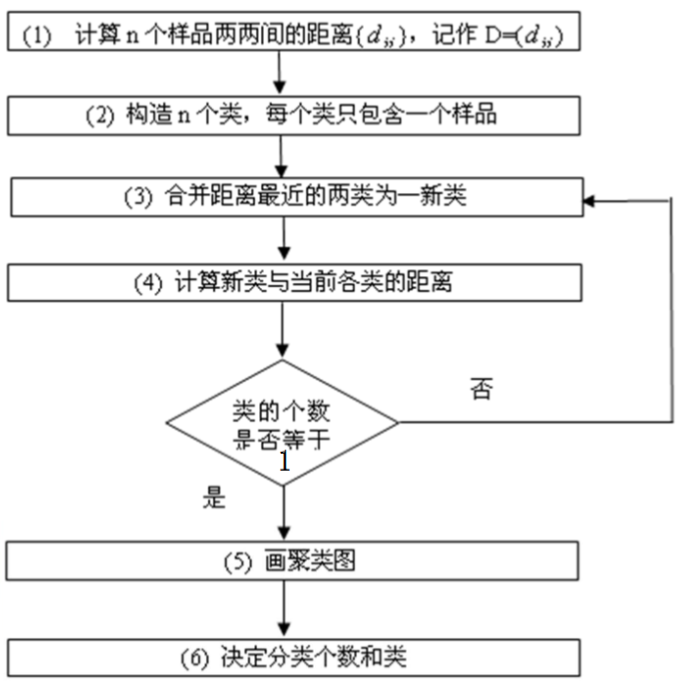
3.4 系统聚类过程
- 论文不能直接使用下图,要自己有所改动(形式与内容表述等)
- 系统(层次)聚类的算法流程:
- ① 将每个对象看作一类,计算两两之间的最小距离;
- ② 将距离最小的两个类合并成一个新类;
- ③ 重新计算新类与所有类之间的距离;
- ④ 重复二三两步,直到所有类最后合并成一类;
- ⑤ 结束。
3.5 完整解题过程
【题目】
- 根据五个学生的六门课的成绩,对这五个学生进行分类
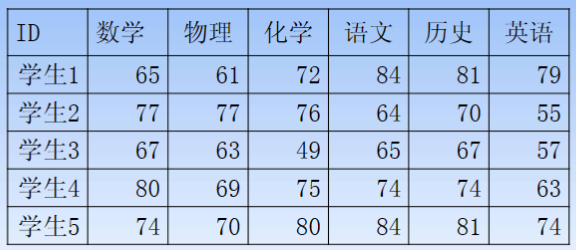
【解法一:采用最短距离系统聚类法】
-
(1)计算过程
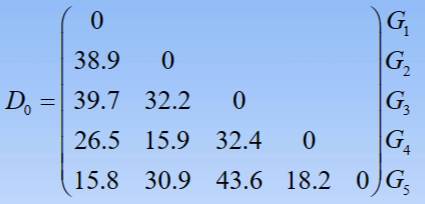
- 1.写出样品间的距离矩阵(以欧氏距离为例)
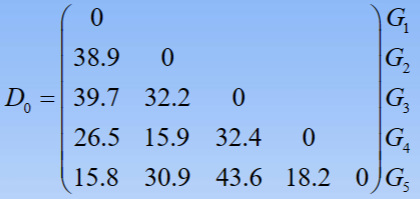
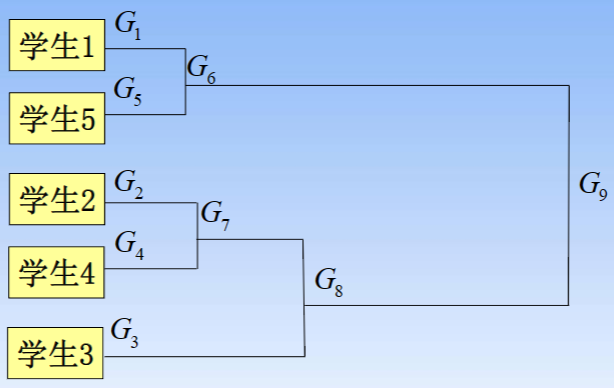
- 2.将每一个样品看做是一个类,即G1,G2,G3,G4,G5,观察D(G1,G5)=15.8最小,故将G1与G5聚为一类,记为G6。计算新类与其余各类之间的距离,得到新的距离矩阵D1
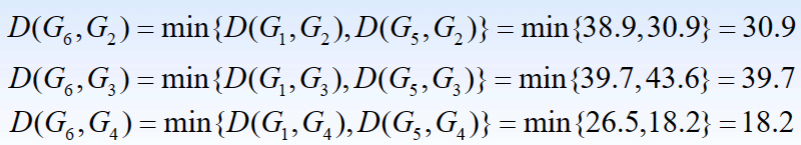
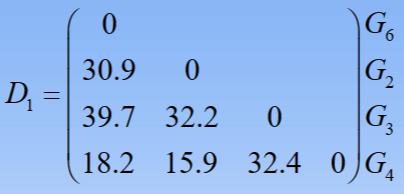
- 3.观察D(G2,G4)=15.9最小,故将G2与G4聚为一类,记为G7。计算新类与其余各类之间的距离,得到新的距离矩阵D2
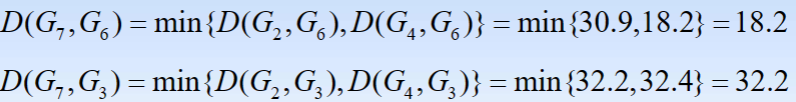

- 4.观察D(G6,G7)=18.2最小,故将G6与G7聚为一类,记为G8。计算新类与其余各类之间的距离,得到新的距离矩阵D3
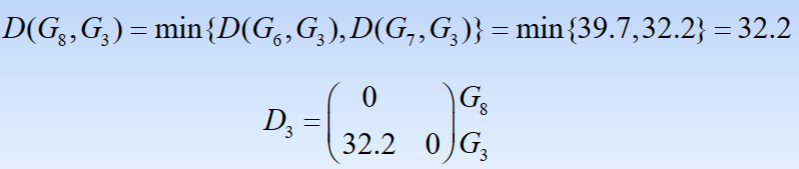
- 5.最后将G8与G3聚为一类,记为G9
- 1.写出样品间的距离矩阵(以欧氏距离为例)
-
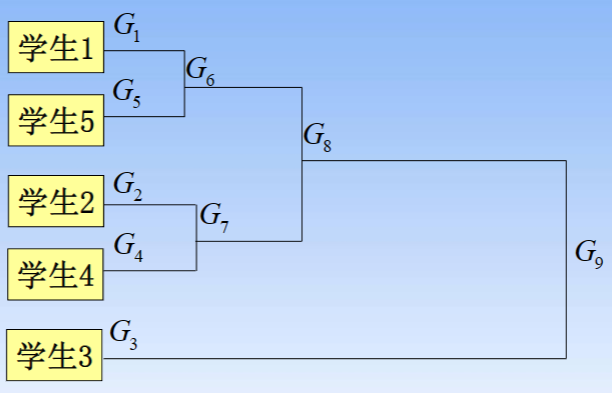
(2)聚类的谱系图(树状图)
【解法二:采用最长距离系统聚类法】
-
(1)计算过程
- 1.写出样品间的距离矩阵(以欧氏距离为例)
2.将每一个样品看做是一个类,即G1,G2,G3,G4,G5,观察D(G1,G5)=15.8最小,故将G1与G5聚为一类,记为G6。计算新类与其余各类之间的距离,得到新的距离矩阵D1
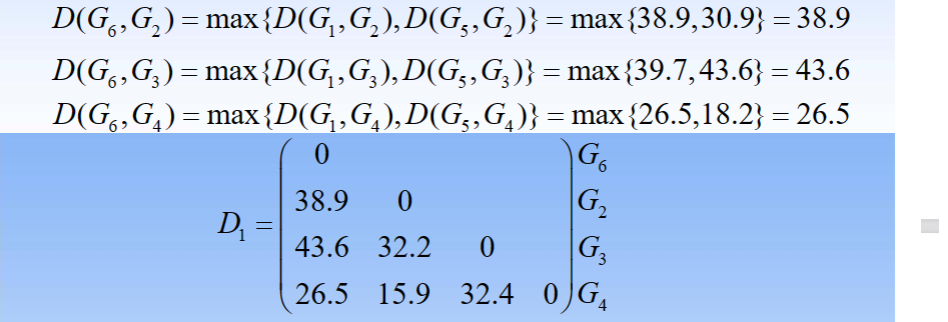
- 3.观察D(G2,G4)=15.9最小,故将G2与G4聚为一类,记为G7。计算新类与其余各类之间的距离,得到新的距离矩阵D2
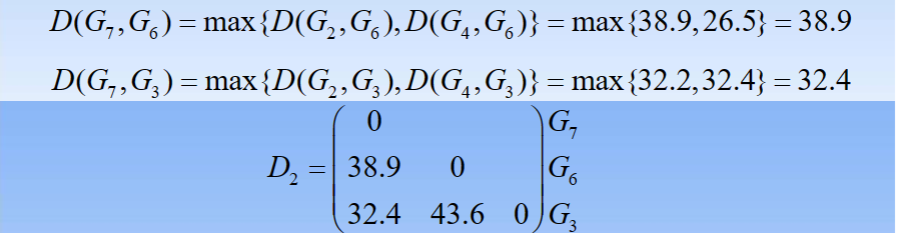
- 4.观察D(G3,G7)=32.4最小,故将G3与G7聚为一类,记为G8。计算新类与其余各类之间的距离,得到新的距离矩阵D3
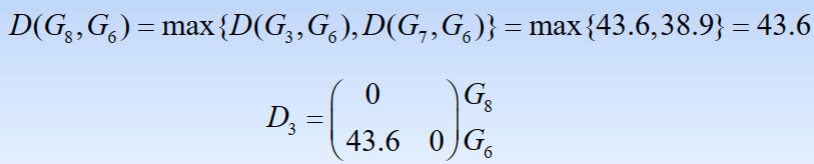
- 5.最后将G8与G6聚为一类,记为G9
- 1.写出样品间的距离矩阵(以欧氏距离为例)
-
(2)聚类的谱系图(树状图)
【其他解法】
- 组间平均连接系统聚类法
- 重心系统聚类法
- 组内平均连接系统聚类法
- 注:这些方法的差别就是在计算新类与其余各类间的距离,只要能解释的通都可以用。
3.6 聚类分析需要注意的问题
- 对于一个实际问题要根据分类的目的来选取指标,指标选取的不同分类结果一般也不同。
- 样品间距离定义方式的不同,聚类结果一般也不同。
- 聚类方法的不同,聚类结果一般也不同(尤其是样品特别多的时候)。最好能通过各种方法找出其中的共性。
- 要注意指标的量纲,量纲差别太大会导致聚类结果不合理。
- 聚类分析的结果可能不令人满意,因为我们所做的是一个数学的处理,对于结果我们要找到一个合理的解释。
3.7 系统聚类的Spss软件操作
- 具体操作
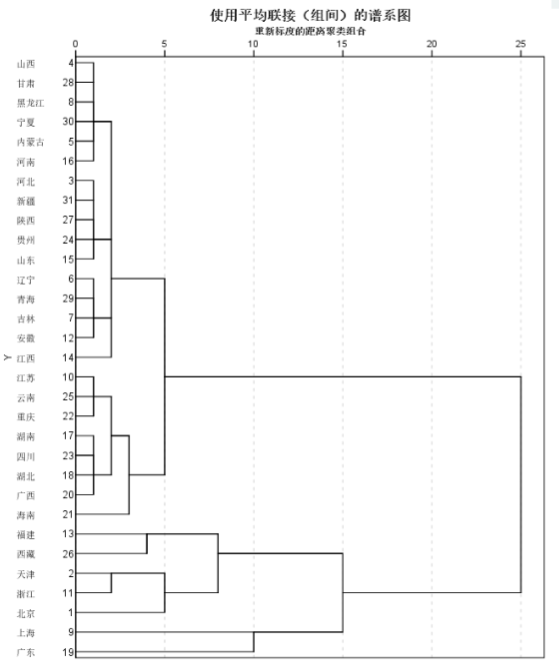
- 结果分析
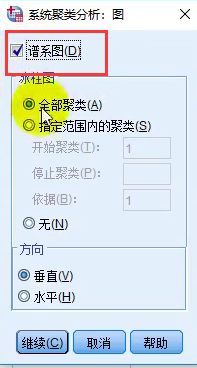
- 谱系图是较新的Spss版本添加的功能:横轴表示各类之间的距离(该距离经过了重新标度);聚类的个数可以自己从图中决定。
- Spss结果中还有一种图,被称为冰柱图,目前已经很少用了。
分类数推荐≤5类(再多不便于解释)
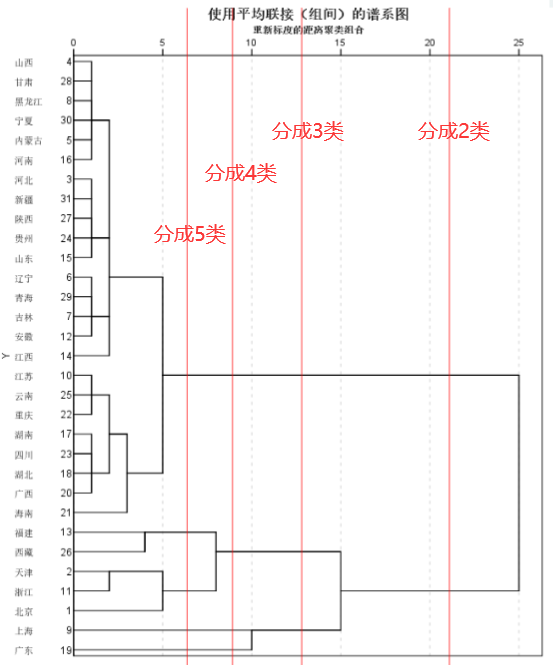
3.8 用图形估计聚类的数量
- 肘部法则(Elbow Method):通过图形大致的估计出最优的聚类数量。

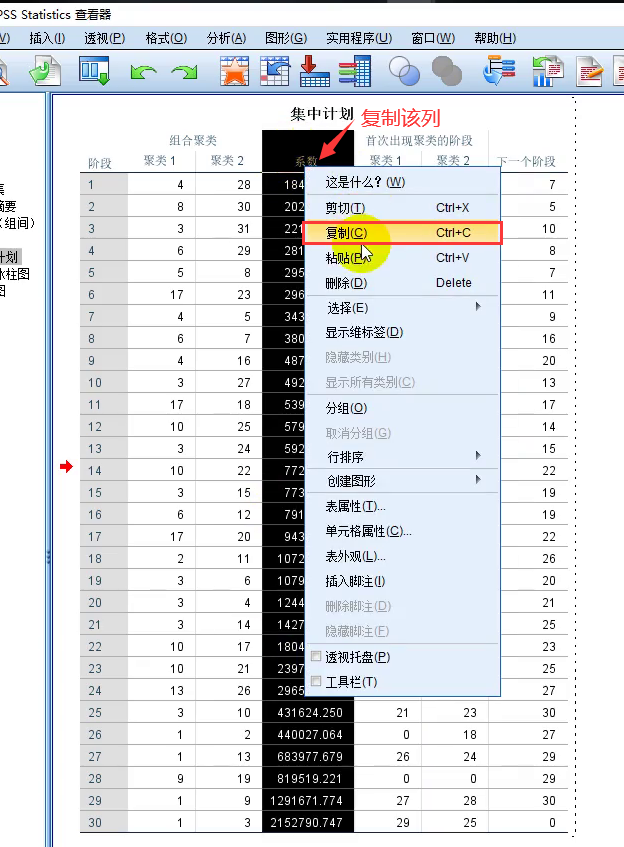
聚合系数折线图的画法
-
① 将Spss中系数列复制到新建Excel表中,并排降序
-
② 构建图表
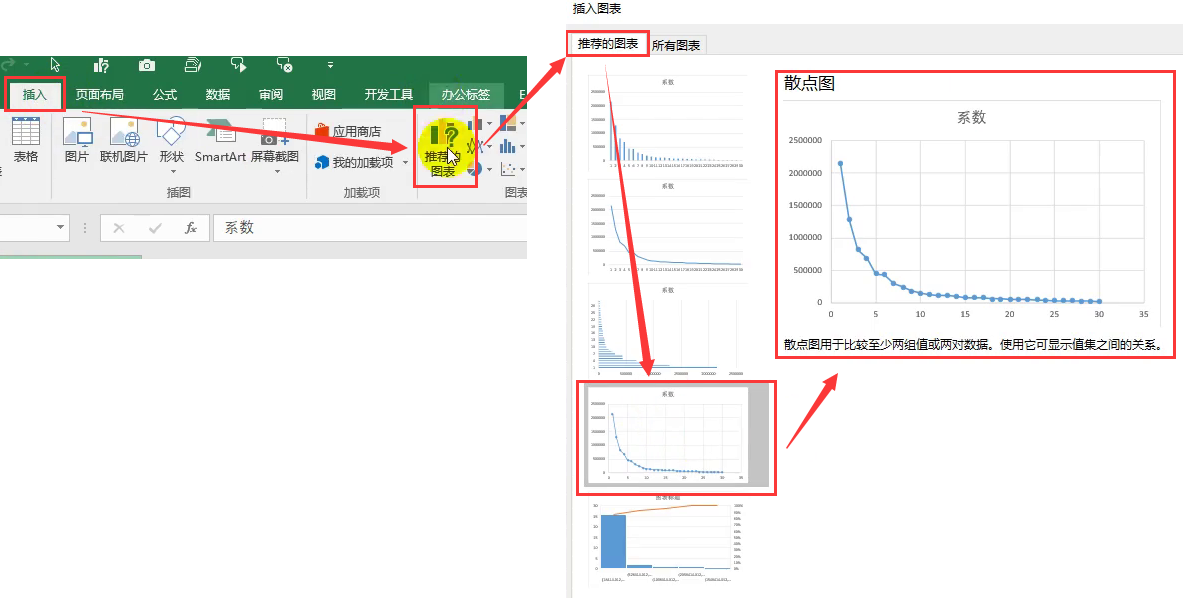
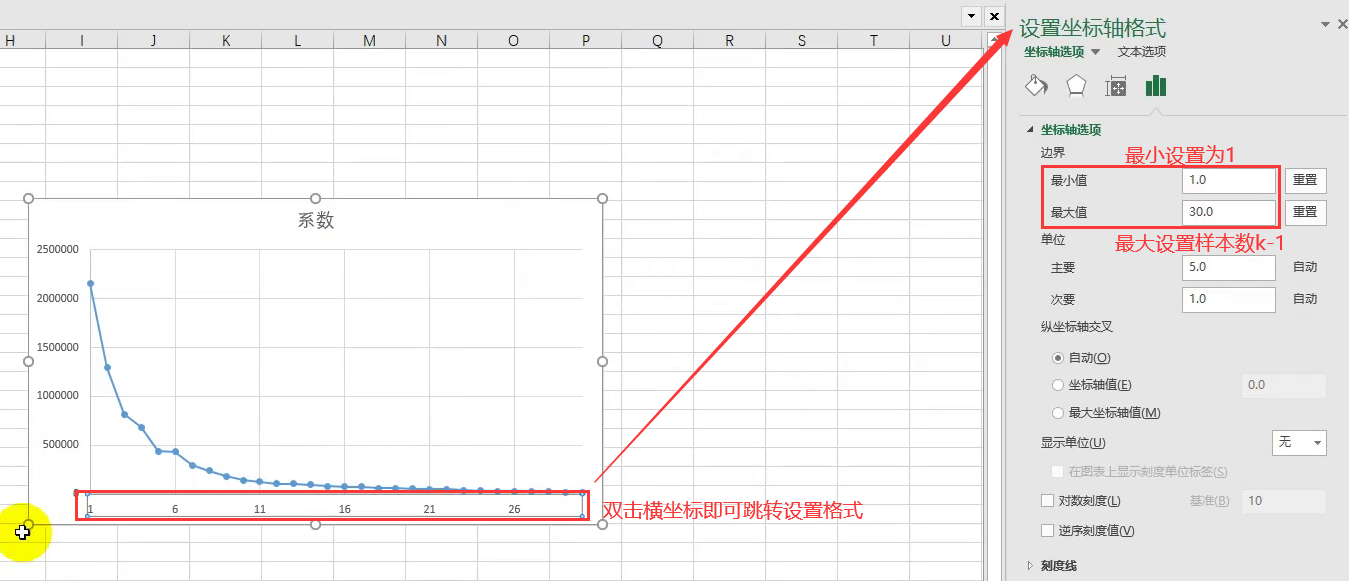
-
③解释图表
- (1) 根据聚合系数折线图可知,当类别数为5时,折线的下降趋势趋缓,故可将类别数设定为5.
- (2) 从图中可以看出, K值从1到5时,畸变程度变化最大。超过5以后,畸变程度变化显著降低。因此肘部就是 K=5,故可将类别数设定为5.(K=3也可以解释,因为3到4的下降幅度也较平缓)
- (哪种好解释采用哪种)
-
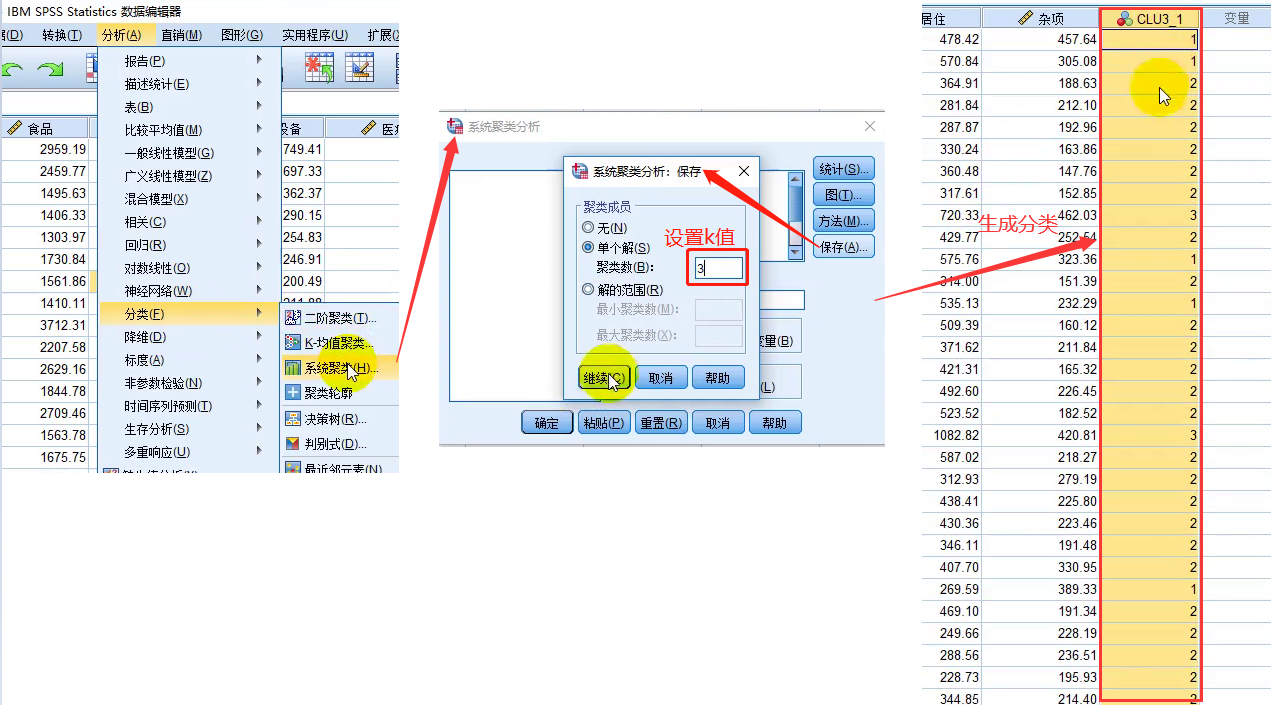
④确定K后保存聚类结果并画示意图
-
示意图说明:只有当指标个数为2或者3的时候才能画图
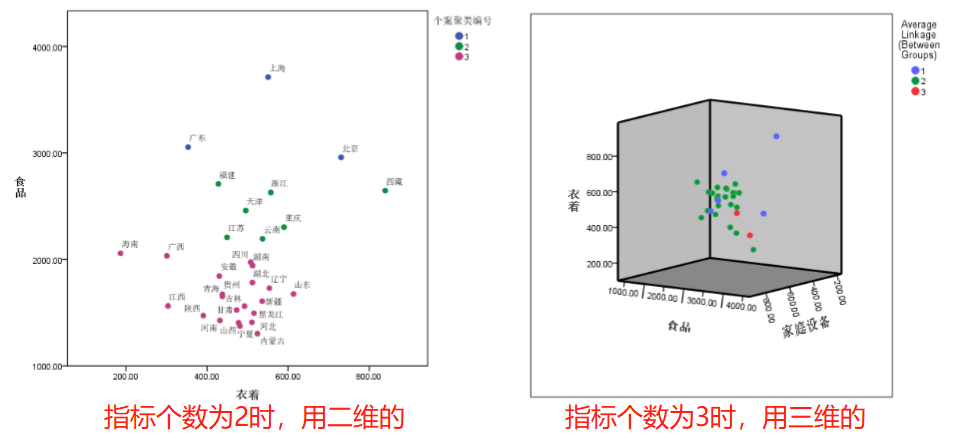
-
生成k(下图为3)个分类后,在论文中要对该k个分类进行解释(为什么分成这3类)
-
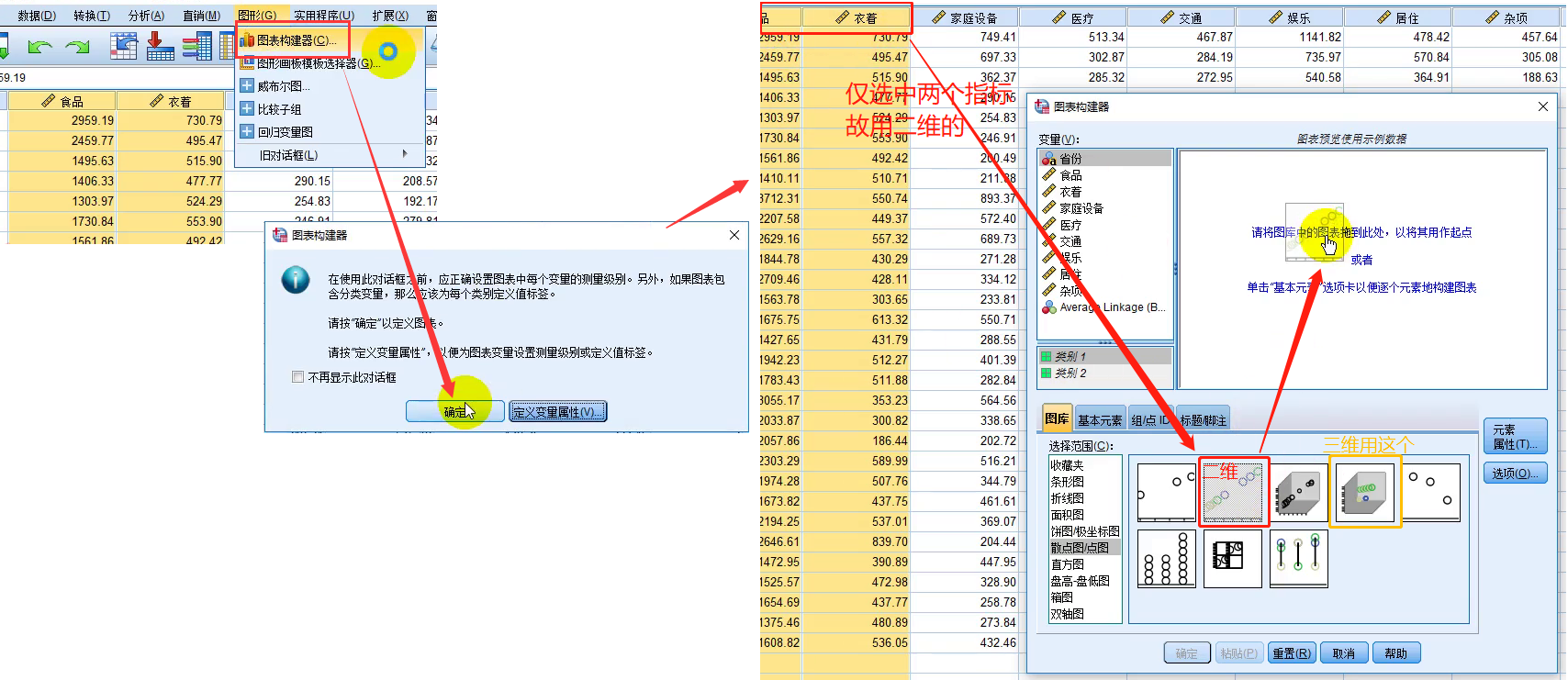
图表构建
-
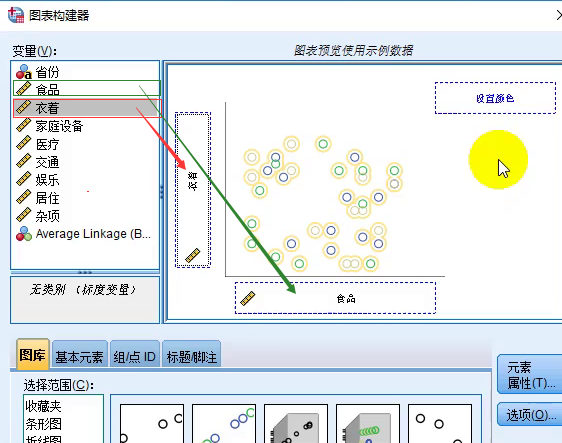
设置横纵轴标签
-
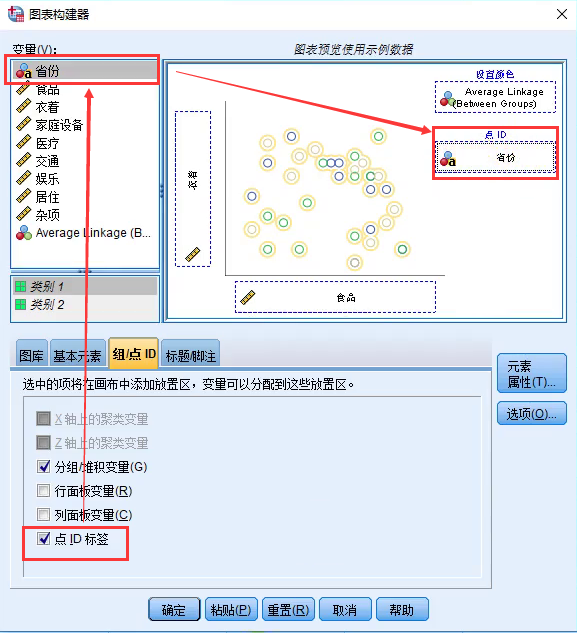
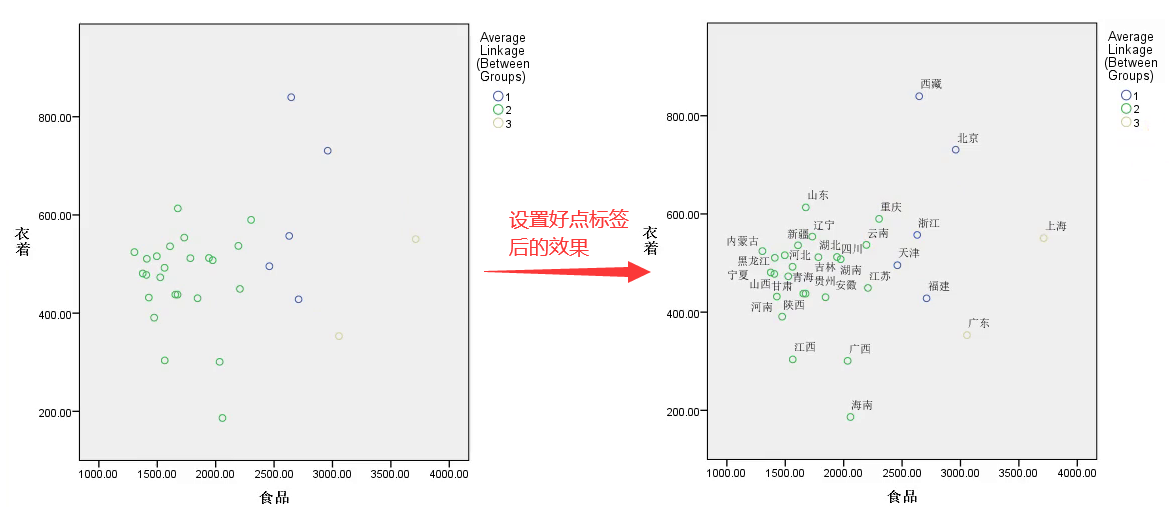
设置点标签
-
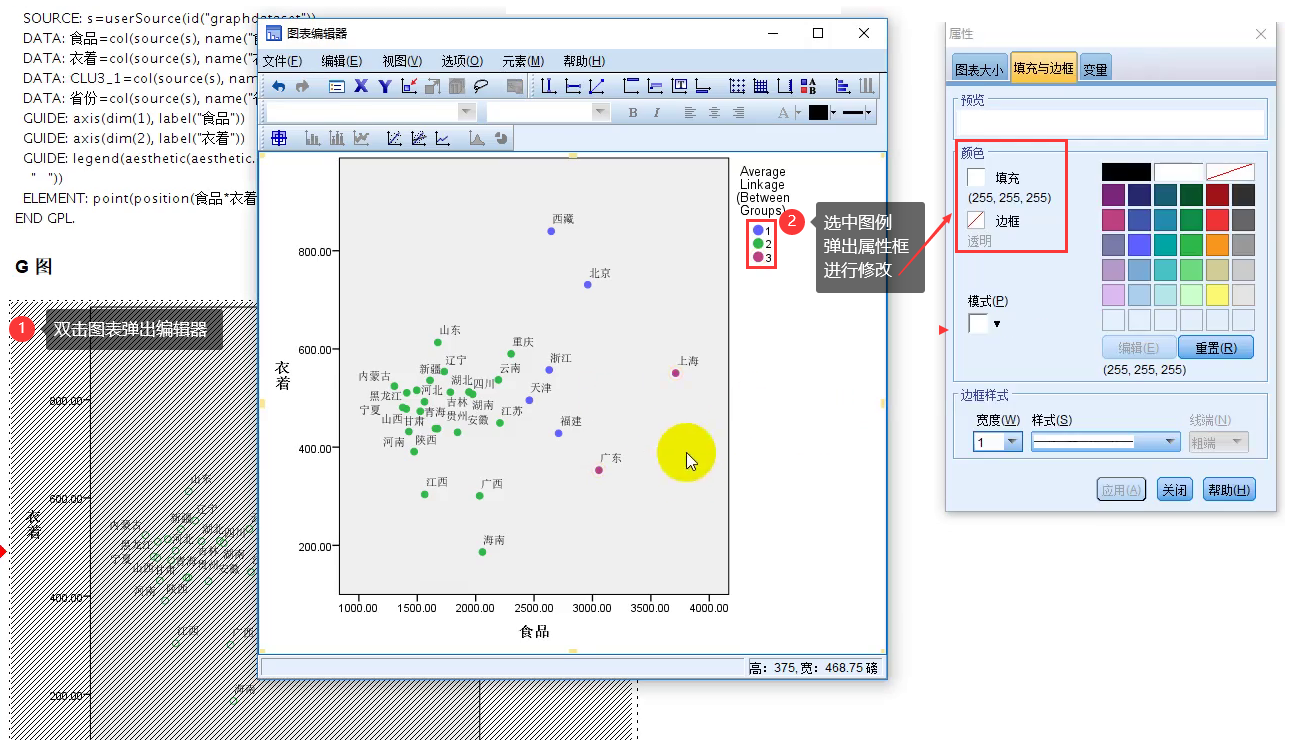
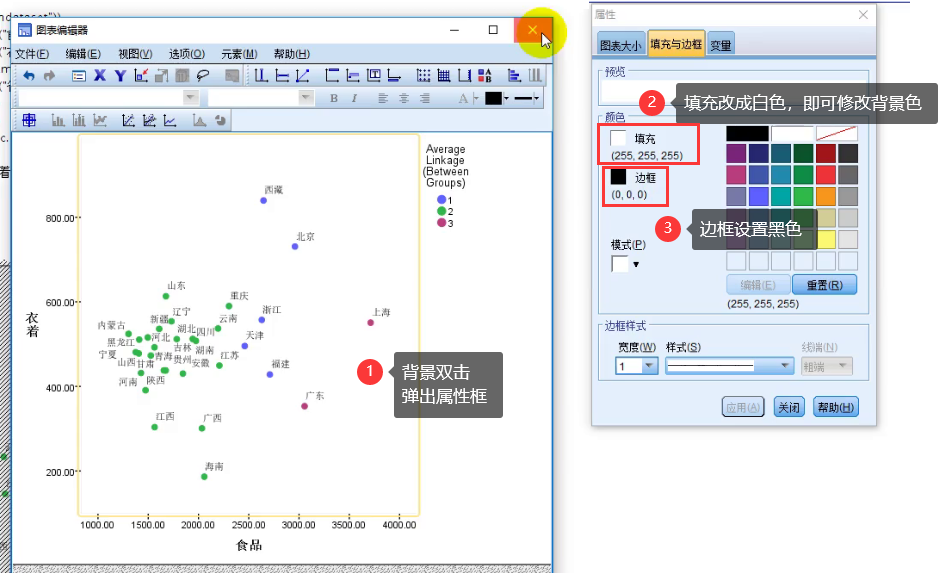
修改图的样式
-
最后直接复制即可
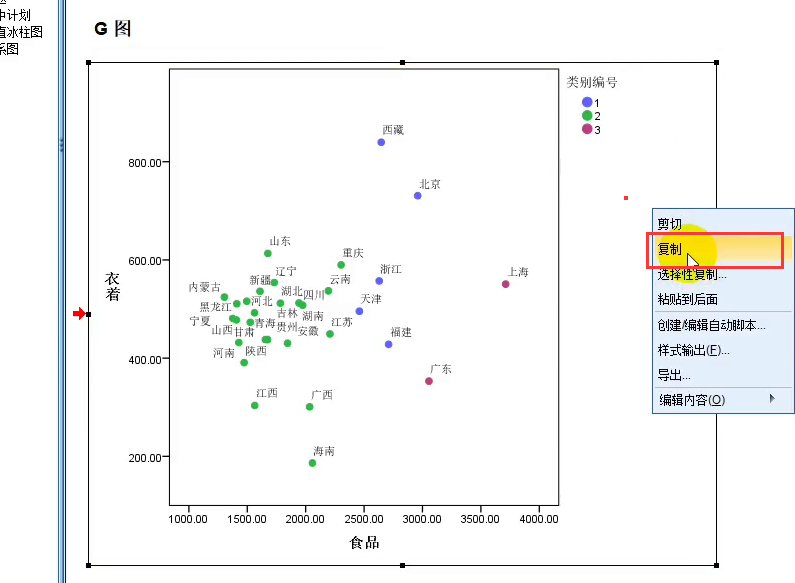
-
四、DBSCAN算法
4.1 DBSCAN算法基本概念
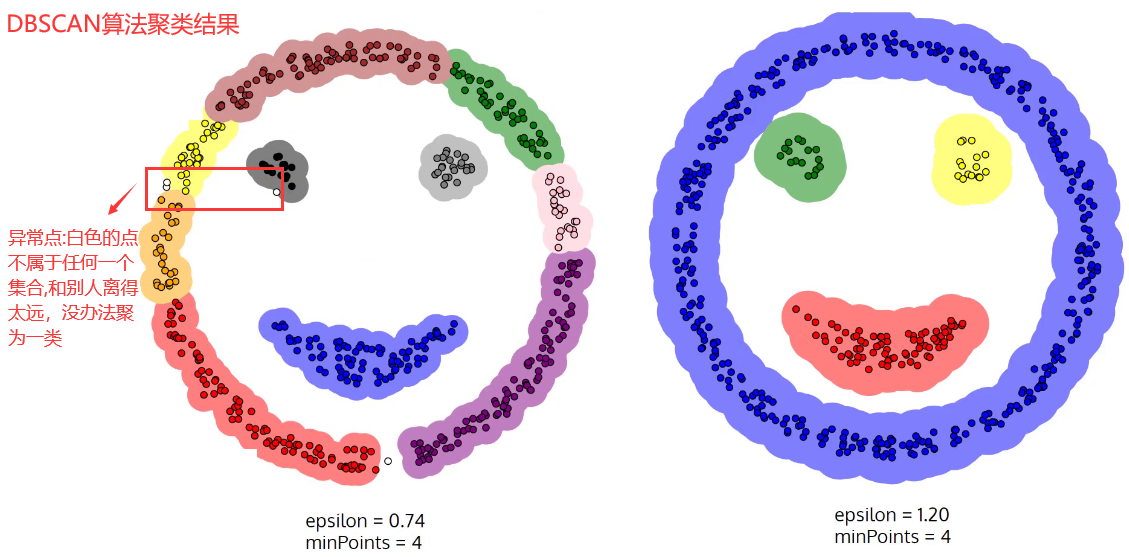
- K-means聚类和层次聚类是基于距离的聚类方法;本节的DBSCAN算法是基于密度的聚类算法
- DBSCAN算法聚类前不需要预先指定聚类的个数,生成的簇的个数不定(和数据有关)。
- 该算法利用基于密度的聚类的概念,即要求聚类空间中的一定区域内所包含对象(点或其他空间对象)的数目不小于某一给定阈值。→ “谁和我挨的近,我就是谁兄弟;兄弟的兄弟,也是我的兄弟”
- 优点:该方法能在具有噪声的空间数据库中发现任意形状的簇,可将密度足够大的相邻区域连接,能有效处理异常数据。
- DBSCAN算法可视化
4.2 分类
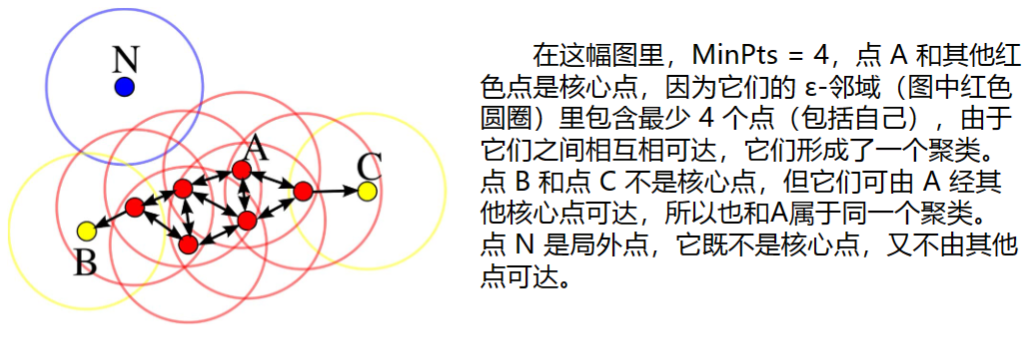
- 核心点(下图红点):在半径Eps内含有不少于MinPts数目的点
- 边界点(下图黄点):在半径Eps内点的数量小于MinPts,但是落在核心点的邻域内
- 噪音点(下图蓝点):既不是核心点也不是边界点的点
4.3 Matlab代码
% Copyright (c) 2015, Yarpiz (www.yarpiz.com)
% All rights reserved. Please read the "license.txt" for license terms.
%
% Project Code: YPML110
% Project Title: Implementation of DBSCAN Clustering in MATLAB
% Publisher: Yarpiz (www.yarpiz.com)
%
% Developer: S. Mostapha Kalami Heris (Member of Yarpiz Team)
%
% Contact Info: [email protected], [email protected]
4.4 优缺点
-
优点:
- 基于密度定义,能处理任意形状和大小的簇;
- 可在聚类的同时发现异常点;
- 与K-means比较起来,不需要输入要划分的聚类个数。
-
缺点:
- 对输入参数ε和Minpts敏感,确定参数困难;
- 由于DBSCAN算法中,变量ε和Minpts是全局唯一的,当聚类的密度不均匀时,聚
类距离相差很大时,聚类质量差; - 当数据量大时,计算密度单元的计算复杂度大。
-
清风老师的建议:
- 只有两个指标,且你做出散点图后发现数据表现得很“DBSCAN”(有形状),这时候再用DBSCAN进行聚类。
- 其他情况下,全部使用系统聚类(K‐means也可以用,不过用了的话论文上可写的东西比较少)。
附言
- 参考课程可见 B站清风数模,如上仅作个人学习后笔记整理。