时间序列分析
将某种现象的指标数值按照时间顺序排列而成的数值序列。
(1) 时间序列的基本概念
1. 组成要素
- 时间要素。
- 数值要素。
2. 时间序列的分类
- 时期序列:数值要素反映现象在一定时期内的表现。(历年的 GDP )
- 时点序列:数值要素反映现象在一定时间点上的瞬时水平。(每次模拟考试的成绩)
- 时期序列可加(相加表示更长一段时期的数值),时点序列不可加。(类比速度和加速度)
3. 时间序列的分解
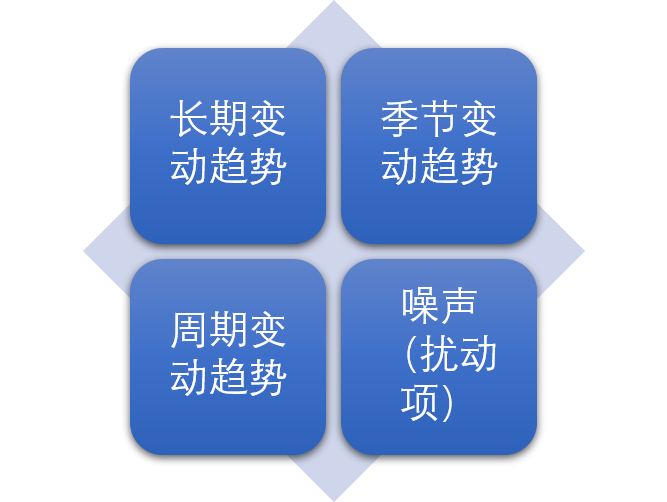
① 长期变动趋势 T
- 表示统计指标在较长一段时间,受到某些长期因素(政策,生产力等)的影响,表现持续上升或持续下降的趋势。

② 季节趋势 S
- 由于季节的转变使指标数据发生周期性的变动。季节是广义的,可以为月、季、周,但不能是年。关键的核心在于周期性。
③ 循环趋势 C
- 与季节趋势的不同在于一方面时间通常以年作为单位,另一方面表现的只是增减趋势的交替出现,而不一定有严格的周期性。
④ 不顾则变动 I
- 扰动项,没有规律也不可预测,是偶然因素导致的。
4. 时间序列的分解模型
- 叠加模型:适用于四种变动之间是相互独立的关系。 Y = T + S + L Y=T+S+L Y=T+S+L
- 乘积模型:适用于四种变动之间存在相互影响的关系。 Y = T × S × L Y=T\times S\times L Y=T×S×L
Y Y Y 表示指标数值的最终变动。 - 选取准则:
- 数据必须具有周期性。月份,季度数据可以用,但年份数据不能用。
- 不存在季节波动,两者都可以选择。
- 存在季节波动,随时间推移,季节波动变动较大可以优先考虑乘积模型,季节波动变化不大可以优先考虑叠加模型。
(2) 季节分解
- 使用 SPSS 软件,选取叠加模型还是乘积模型。
(3) 指数平滑法
1. 简单指数平滑法
- 适用于不含趋势和季节成分的情况。
- 类似于 ARIMA(0,1,1)。
- 令 x t x_t xt 为 t t t 时刻的观测数据, S t S_t St 为第 t t t 期的平滑值,再令 S t = x ^ t + 1 S_t=\hat{x}_{t+1} St=x^t+1 为第 t + 1 t+1 t+1 期的预测值。满足如下条件: x ^ t + 1 = α x t + ( 1 − α ) x ^ t \hat{x}_{t+1}=\alpha x_t+(1-\alpha)\hat{x}_t x^t+1=αxt+(1−α)x^t
其中 0 ≤ α ≤ 1 0\le \alpha \le 1 0≤α≤1 称为平滑系数。 - 代入展开式为: x ^ t + 1 = α x t + α ( 1 − α ) x t − 1 + α ( 1 − α ) 2 x t − 2 + ⋯ \hat{x}_{t+1}=\alpha x_t+\alpha(1-\alpha)x_{t-1}+\alpha(1-\alpha)^2x_{t-2}+\dotsb x^t+1=αxt+α(1−α)xt−1+α(1−α)2xt−2+⋯
- 注意:由公式形式决定,简单指数平滑只能预测一期。
2. 线性趋势模型
- 适用于线性趋势,不含季节成分。
- 类似于 ARIMA(0,2,2)。
- l t l_t lt 表示在 t t t 时期的水平估计值, b t b_t bt 表示在 t t t 时刻的趋势估计值(斜率), 0 ≤ α ≤ 1 0\le \alpha \le 1 0≤α≤1 为水平的平滑系数, 0 ≤ β ≤ 1 0\le \beta \le 1 0≤β≤1 为趋势的平滑系数。
{ l t = α x t + ( 1 − α ) ( l t − 1 + b t − 1 ) ( 水 平 平 滑 方 程 ) b t = β ( l t − l t − 1 ) + ( 1 − β ) b t − 1 ( 趋 势 平 滑 方 程 ) x ^ t + h = l t + h b t , h = 1 , 2 , 3 , ⋯ ( 预 测 方 程 ) \left\{ \begin{aligned} l_t=\alpha x_t+(1-\alpha)(l_{t-1}+b_{t-1})&&(水平平滑方程) \\ b_t=\beta(l_t-l_{t-1})+(1-\beta)b_{t-1}&&(趋势平滑方程) \\ \hat{x}_{t+h}=l_t+hb_t,h=1,2,3,\dotsb&&(预测方程) \end{aligned} \right. ⎩⎪⎨⎪⎧lt=αxt+(1−α)(lt−1+bt−1)bt=β(lt−lt−1)+(1−β)bt−1x^t+h=lt+hbt,h=1,2,3,⋯(水平平滑方程)(趋势平滑方程)(预测方程)
影响 b t b_t bt 的因素是水平的增量和上一期的 b t − 1 b_{t-1} bt−1 的值,影响 l t l_t lt 的是当前观测值 x t x_t xt,上一期的水平估计值 l t − 1 l_{t-1} lt−1 和上一期的趋势估计值 b t − 1 b_{t-1} bt−1。预测方程可以用积分做类似的理解。
3. 阻尼趋势模型
- 适用线性趋势逐渐减弱且不含季节性因素。
- 类似于 ARIMA(1,1,2)。
- l t l_t lt 表示在 t t t 时期的水平估计值, b t b_t bt 表示在 t t t 时刻的趋势估计值(斜率), 0 ≤ α ≤ 1 0\le \alpha \le 1 0≤α≤1 为水平的平滑系数, 0 ≤ β ≤ 1 0\le \beta \le 1 0≤β≤1 为趋势的平滑系数, 0 < ϕ ≤ 1 0<\phi\le1 0<ϕ≤1 为阻尼参数。
{ l t = α x t + ( 1 − α ) ( l t − 1 + ϕ b t − 1 ) ( 水 平 平 滑 方 程 ) b t = β ( l t − l t − 1 ) + ( 1 − β ) ϕ b t − 1 ( 趋 势 平 滑 方 程 ) x ^ t + h = l t + ( ϕ + ϕ 2 + ⋯ + ϕ h ) b t ( 预 测 方 程 ) \left\{ \begin{aligned} l_t=\alpha x_t+(1-\alpha)(l_{t-1}+\phi b_{t-1})&&(水平平滑方程) \\ b_t=\beta(l_t-l_{t-1})+(1-\beta)\phi b_{t-1}&&(趋势平滑方程) \\ \hat{x}_{t+h}=l_t+(\phi+\phi^2+\dotsb+\phi^h)b_t&&(预测方程) \end{aligned} \right. ⎩⎪⎨⎪⎧lt=αxt+(1−α)(lt−1+ϕbt−1)bt=β(lt−lt−1)+(1−β)ϕbt−1x^t+h=lt+(ϕ+ϕ2+⋯+ϕh)bt(水平平滑方程)(趋势平滑方程)(预测方程)
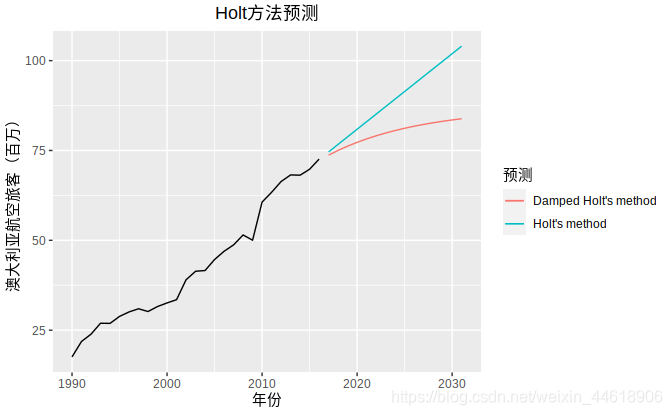
可以看出当阻尼参数越接近 0 时,对原趋势的阻碍作用越大。
下面是一张阻尼与线性的预测图。
4. 简单季节趋势模型
- 适用有稳定的季节成分、不含趋势。
- 类似于 SARIMA(0,1,1) × \times × (0,1,1)。
- l t l_t lt 表示在 t t t 时期的水平估计值, s t s_t st 表示在 t t t 时刻的季节估计值, 0 ≤ α ≤ 1 0\le \alpha \le 1 0≤α≤1 为水平的平滑系数, 0 ≤ γ ≤ 1 0\le \gamma \le 1 0≤γ≤1 为趋势的平滑系数, m m m 代表周期的长度,月为周期就是 12,季度为周期就是 4。
{ l t = α ( x t − s t − m ) + ( 1 − α ) l t − 1 ( 水 平 平 滑 方 程 ) s t = γ ( x t − l t − 1 ) + ( 1 − γ ) s t − m ( 季 节 平 滑 方 程 ) x ^ t + h = l t + s t + h − m ( k + 1 ) , k = ⌊ h − 1 m ⌋ ( 预 测 方 程 ) \left\{ \begin{aligned} l_t&=\alpha (x_t-s_{t-m})+(1-\alpha)l_{t-1}&&(水平平滑方程) \\ s_t&=\gamma(x_t-l_{t-1})+(1-\gamma) s_{t-m}&&(季节平滑方程) \\ \hat{x}_{t+h}&=l_t+s_{t+h-m(k+1)},k=\lfloor \frac{h-1}{m} \rfloor&&(预测方程) \end{aligned} \right. ⎩⎪⎪⎪⎨⎪⎪⎪⎧ltstx^t+h=α(xt−st−m)+(1−α)lt−1=γ(xt−lt−1)+(1−γ)st−m=lt+st+h−m(k+1),k=⌊mh−1⌋(水平平滑方程)(季节平滑方程)(预测方程)
5. Holt-Winters 加法模型
- 适用有稳定的季节成分、含线性趋势。
- 类似于 SARIMA(0,1,0) × \times × (0,1,1)。
- l t l_t lt 表示在 t t t 时期的水平估计值, s t s_t st 表示在 t t t 时刻的季节估计值, 0 ≤ α ≤ 1 0\le \alpha \le 1 0≤α≤1 为水平的平滑系数, 0 ≤ γ ≤ 1 0\le \gamma \le 1 0≤γ≤1 为趋势的平滑系数, m m m 代表周期的长度,月为周期就是 12,季度为周期就是 4。
{ l t = α ( x t − s t − m ) + ( 1 − α ) ( l t − 1 + b t − 1 ) ( 水 平 平 滑 方 程 ) b t = β ( l t − l t − 1 ) + ( 1 − β ) b t − 1 ( 趋 势 平 滑 方 程 ) s t = γ ( x t − l t − 1 − b t − 1 ) + ( 1 − γ ) s t − m ( 季 节 平 滑 方 程 ) x ^ t + h = l t + h b t + s t + h − m ( k + 1 ) , k = ⌊ h − 1 m ⌋ ( 预 测 方 程 ) \left\{ \begin{aligned} l_t&=\alpha (x_t-s_{t-m})+(1-\alpha)(l_{t-1}+b_{t-1})&&(水平平滑方程) \\ b_t&=\beta(l_t-l_{t-1})+(1-\beta) b_{t-1}&&(趋势平滑方程) \\ s_t&=\gamma(x_t-l_{t-1}-b_{t-1})+(1-\gamma) s_{t-m}&&(季节平滑方程) \\ \hat{x}_{t+h}&=l_t+hb_t+s_{t+h-m(k+1)},k=\lfloor \frac{h-1}{m} \rfloor&&(预测方程) \end{aligned} \right. ⎩⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎧ltbtstx^t+h=α(xt−st−m)+(1−α)(lt−1+bt−1)=β(lt−lt−1)+(1−β)bt−1=γ(xt−lt−1−bt−1)+(1−γ)st−m=lt+hbt+st+h−m(k+1),k=⌊mh−1⌋(水平平滑方程)(趋势平滑方程)(季节平滑方程)(预测方程) - 水平方程表示在 t t t 时刻,季节性调整的观察值与非季节性预测值之间的加权平均值。
- 季节性方程表示当前季节性指数和去年同一季节(即 m m m 个时间段前)的季节性指数之间的加权平均值。
5. Holt-Winters 乘法模型
- 适用不稳定的季节成分、含线性趋势。
- 不存在 ARIMA 模型。
{ l t = α x t s t − m + ( 1 − α ) ( l t − 1 + b t − 1 ) ( 水 平 平 滑 方 程 ) b t = β ( l t − l t − 1 ) + ( 1 − β ) b t − 1 ( 趋 势 平 滑 方 程 ) s t = γ x t l t − 1 + b t − 1 + ( 1 − γ ) s t − m ( 季 节 平 滑 方 程 ) x ^ t + h = ( l t + h b t ) s t + h − m ( k + 1 ) , k = ⌊ h − 1 m ⌋ ( 预 测 方 程 ) \left\{ \begin{aligned} l_t&=\alpha \frac{x_t}{s_{t-m}}+(1-\alpha)(l_{t-1}+b_{t-1})&&(水平平滑方程) \\ b_t&=\beta(l_t-l_{t-1})+(1-\beta) b_{t-1}&&(趋势平滑方程) \\ s_t&=\gamma\frac{x_t}{l_{t-1}+b_{t-1}}+(1-\gamma) s_{t-m}&&(季节平滑方程) \\ \hat{x}_{t+h}&=(l_t+hb_t)s_{t+h-m(k+1)},k=\lfloor \frac{h-1}{m} \rfloor&&(预测方程) \end{aligned} \right. ⎩⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎧ltbtstx^t+h=αst−mxt+(1−α)(lt−1+bt−1)=β(lt−lt−1)+(1−β)bt−1=γlt−1+bt−1xt+(1−γ)st−m=(lt+hbt)st+h−m(k+1),k=⌊mh−1⌋(水平平滑方程)(趋势平滑方程)(季节平滑方程)(预测方程)
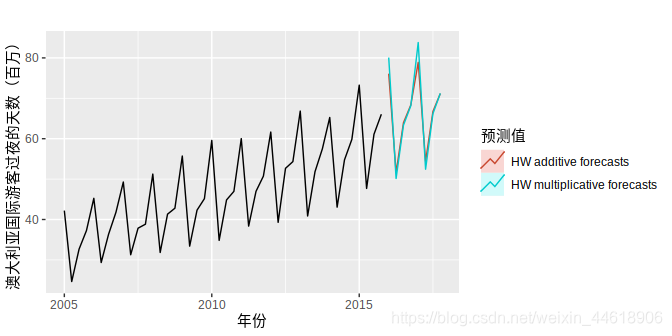
下图为分别使用乘法模型与加法模型进行的预测:
(4) ARIMA 模型
1. 平稳时间序列和白噪声序列
- 协方差平稳(弱平稳):时间序列 x t {x_t} xt 满足以下三个条件
- E ( x t ) = E ( x t − s ) = μ E(x_t)=E(x_{t-s})=\mu E(xt)=E(xt−s)=μ 均值固定为常数。
- V a r ( x t ) = v a r ( x t − s ) = σ 2 Var(x_t)=var(x_{t-s})=\sigma^2 Var(xt)=var(xt−s)=σ2 方差存在且为常数。
- C o v ( x t , x t − s ) = γ s Cov(x_t,x_{t-s})=\gamma_s Cov(xt,xt−s)=γs 协方差只与间隔 s s s 有关,与 t t t 无关。
- 白噪声:时间序列 x t {x_t} xt 满足以下三个条件
- E ( x t ) = E ( x t − s ) = 0 E(x_t)=E(x_{t-s})=0 E(xt)=E(xt−s)=0
- V a r ( x t ) = V a r ( x t − s ) = σ 2 Var(x_t)=Var(x_{t-s})=\sigma^2 Var(xt)=Var(xt−s)=σ2 方差存在且为常数。
- C o v ( x t , x t − s ) = 0 Cov(x_t,x_{t-s})=0 Cov(xt,xt−s)=0
2. 差分方程与滞后算子
① 差分
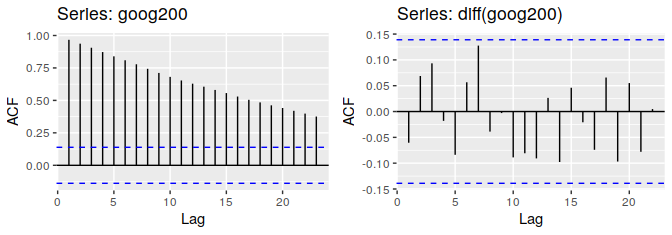
- 目的:通过作差来消除整体趋式或者季节变动的影响,比如下面 google 的股价,右边是做完差分后的状态。
② 差分方程
- 将某个时间序列变量表示为该变量的滞后项、时间和其他变量的一个函数方程。
- 自回归 A R ( p ) AR(p) AR(p) 模型 y t = α 0 + α 1 y t − 1 + ⋯ + α p y t − p + ϵ t y_t=\alpha_0+\alpha_1y_{t-1}+\dotsb+\alpha_py_{t-p}+\epsilon_t yt=α0+α1yt−1+⋯+αpyt−p+ϵt
- 移动平均 M A ( q ) MA(q) MA(q) 模型 y t = ϵ t + β 1 ϵ t − 1 + ⋯ + β q ϵ t − q y_t=\epsilon_t+\beta_1\epsilon_{t-1}+\dotsb+\beta_q\epsilon_{t-q} yt=ϵt+β1ϵt−1+⋯+βqϵt−q
- 自回归移动平均 A R M A ( p , q ) ARMA(p,q) ARMA(p,q) 模型 y t = α 0 + ∑ i = 1 p α i y t − i + ϵ t + ∑ i = 1 q β i ϵ t − i y_t=\alpha_0+\sum_{i=1}^{p}\alpha_iy_{t-i}+\epsilon_t+\sum_{i=1}^{q}\beta_i\epsilon_{t-i} yt=α0+i=1∑pαiyt−i+ϵt+i=1∑qβiϵt−i
③ 差分方程的特征方程
- 差分方程的齐次部分:只包含该变量自身及其滞后项。
- 特征方程:令齐次部分中的 y t = x t y_t=x^t yt=xt。
例如,对自回归移动平均 A R M A ( p , q ) ARMA(p,q) ARMA(p,q)模型:
齐次部分: y t = ∑ i = 1 p α i y t − i y_t=\sum_{i=1}^{p}\alpha_iy_{t-i} yt=i=1∑pαiyt−i
特征方程(代入化简): x p = α 1 x p − 1 + α 2 x p − 2 + ⋯ + α p x^p=\alpha_1x^{p-1}+\alpha_2x^{p-2}+\dotsb+\alpha_p xp=α1xp−1+α2xp−2+⋯+αp
④ 滞后算子
- 用来简化差分方程的书写。
- 用符号 L L L 来表示滞后算子, L i y t = y t − i L^iy_t=y_{t-i} Liyt=yt−i
- L C = C LC=C LC=C( C C C为常数)
- ( L i + L j ) y t = y t − i + y t − j (L^i+L^j)y_t=y_{t-i}+y_{t-j} (Li+Lj)yt=yt−i+yt−j
- L i L j y t = y t − i − j L^iL^jy_t=y_{t-i-j} LiLjyt=yt−i−j
- 差分的转化:
- 一阶差分: Δ y t = y t − y t − 1 = ( 1 − L ) y t \Delta y_t=y_t-y_{t-1}=(1-L)y_t Δyt=yt−yt−1=(1−L)yt
- 二阶差分: Δ y t = ( y t − y t − 1 ) − ( y t − 1 − y t − 2 ) = ( 1 − L ) 2 y t \Delta y_t=(y_t-y_{t-1})-(y_{t-1}-y_{t-2})=(1-L)^2y_t Δyt=(yt−yt−1)−(yt−1−yt−2)=(1−L)2yt
- k 阶差分: Δ y t = ( 1 − L ) k y t \Delta y_t=(1-L)^ky_t Δyt=(1−L)kyt
- 一阶差分: Δ y t = y t − y t − 1 = ( 1 − L ) y t \Delta y_t=y_t-y_{t-1}=(1-L)y_t Δyt=yt−yt−1=(1−L)yt
3. AR(p) 与 MA(q)
① AR(p)–p 阶自回归模型
y t = α 0 + α 1 y t − 1 + ⋯ + α p y t − p + ϵ t ⇌ ( 1 − ∑ i = 1 p L i α i ) y t = ϵ t + α 0 y_t=\alpha_0+\alpha_1y_{t-1}+\dotsb+\alpha_py_{t-p}+\epsilon_t\rightleftharpoons (1-\sum_{i=1}^pL^i\alpha_i)y_t=\epsilon_t+\alpha_0 yt=α0+α1yt−1+⋯+αpyt−p+ϵt⇌(1−i=1∑pLiαi)yt=ϵt+α0
- ϵ t \epsilon_t ϵt 是方差为 σ 2 \sigma^2 σ2的白噪声序列。
- 自回归只能适用于预测与自身前期相关的现象。
- 自回归模型只能应用于平稳的序列,如果不平稳要先转换。
- 平稳的判断:
转换成特征方程并解出 p p p 个特征根 x p = α 1 x p − 1 + α 2 x p − 2 + ⋯ + α p x^p=\alpha_1x^{p-1}+\alpha_2x^{p-2}+\dotsb+\alpha_p xp=α1xp−1+α2xp−2+⋯+αp- p p p 个特征根的模值均比 1 1 1 小,平稳。
- p p p 个特征根中有 k k k 个根模值恰好为 1 1 1,进行 k k k 阶单位根过程,就是进行 k k k 次差分。
- p p p 个特征根中存在一个根的模值比 1 1 1 大,不平稳。
② MA(q)–q 阶移动平均模型
y t = ϵ t + β 1 ϵ t − 1 + ⋯ + β q ϵ t − q ⇌ y t = ϵ t + ( 1 + ∑ i = 1 q L i β i ) ϵ t y_t=\epsilon_t+\beta_1\epsilon_{t-1}+\dotsb+\beta_q\epsilon_{t-q}\rightleftharpoons y_t=\epsilon_t+(1+\sum_{i=1}^qL^i\beta_i)\epsilon_t yt=ϵt+β1ϵt−1+⋯+βqϵt−q⇌yt=ϵt+(1+i=1∑qLiβi)ϵt
- 可以与AR模型之间相互转化。
- 平稳的判断:只要 q q q 不取 ∞ \infin ∞ 就平稳。
③ ARMA(p,q)–自回归移动平均模型
y t = α 0 + ∑ i = 1 p α i y t − i + ϵ t + ∑ i = 1 q β i ϵ t − i ⇌ ( 1 − ∑ i = 1 p L i α i ) y t = α 0 + ( 1 + ∑ i = 1 q L i β i ) ϵ t y_t=\alpha_0+\sum_{i=1}^{p}\alpha_iy_{t-i}+\epsilon_t+\sum_{i=1}^{q}\beta_i\epsilon_{t-i}\rightleftharpoons (1-\sum_{i=1}^pL^i\alpha_i)y_t=\alpha_0+(1+\sum_{i=1}^qL^i\beta_i)\epsilon_t yt=α0+i=1∑pαiyt−i+ϵt+i=1∑qβiϵt−i⇌(1−i=1∑pLiαi)yt=α0+(1+i=1∑qLiβi)ϵt
- 平稳性的判断:只与 AR§部分有关。
4. ACF与PACF
两个相关系数存在的条件都是时间序列是平稳的。
① ACF自相关系数
- 定义
ρ s = c o v ( x t , x t − s ) V a r ( x t ) V a r ( x t − s ) = γ s γ 0 \rho_s=\frac{cov(x_t,x_{t-s})}{\sqrt{Var(x_t)}\sqrt{Var(x_{t-s})}}=\frac{\gamma_s}{\gamma_0} ρs=Var(xt)Var(xt−s)cov(xt,xt−s)=γ0γs 由平稳时间序列的定义转化到 γ \gamma γ 的比值,表明在一个平稳的时间序列中相隔 s s s 期的两个时间点之间的相关系数。 - 样本的自相关系数 r s = ρ ^ s = ∑ t = s + 1 T ( x t − x ‾ ) ( x t − s − x ‾ ) ∑ t = 1 T ( x t − x ‾ ) 2 r_s=\hat{\rho}_s=\frac{\sum_{t=s+1}^T(x_t-\overline{x})(x_{t-s}-\overline{x})}{\sum_{t=1}^T(x_t-\overline{x})^2} rs=ρ^s=∑t=1T(xt−x)2∑t=s+1T(xt−x)(xt−s−x)
- 如果时间序列是白噪声序列
ρ s = { 1 s = 0 0 s ≠ 0 \rho_s=\left\{ \begin{aligned} 1&&s=0 \\ 0&&s\not ={0} \end{aligned} \right. ρs={ 10s=0s=0
② PACF偏自相关系数
- 它衡量的是在移除滞后量 1 , 2 , ⋯ , k − 1 1,2,\dotsb,k-1 1,2,⋯,k−1 的影响的情况下, y t y_t yt 和 y t − k y_{t-k} yt−k 的关系,而之前 ACF在求 y t y_t yt 和 y t − k y_{t-k} yt−k 的关系时并未去除中间变量的影响。
③ 使用PACF与ACF判断模型



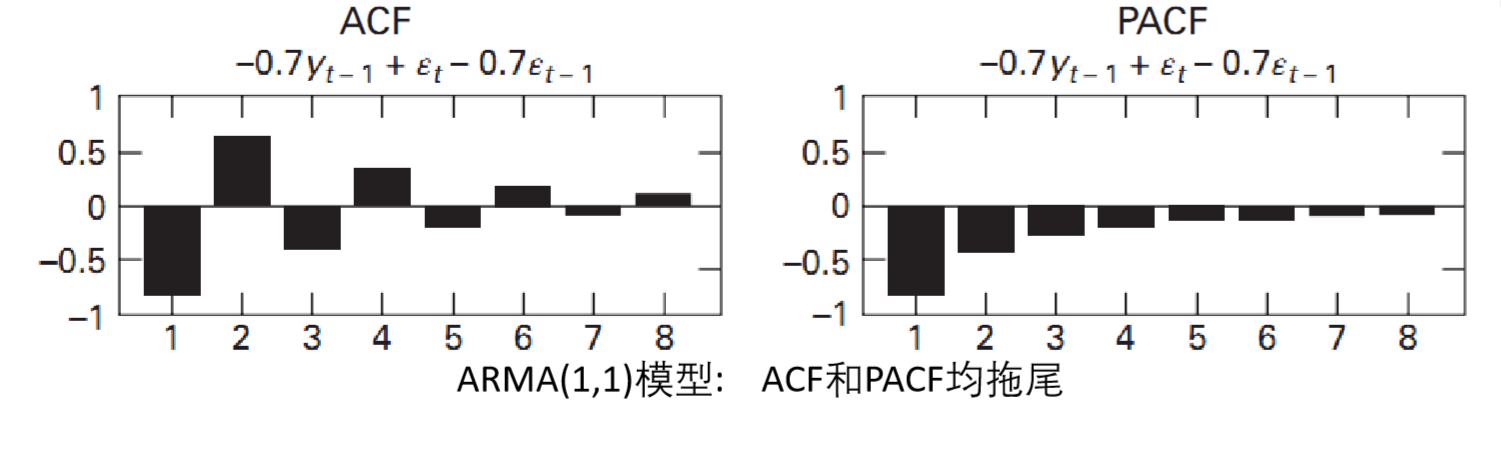
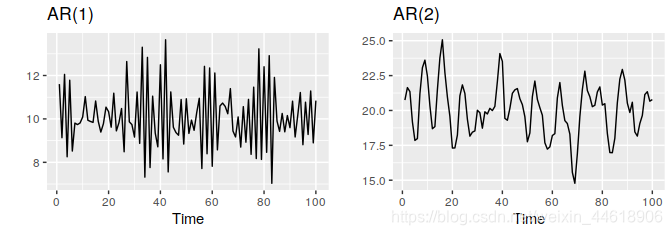
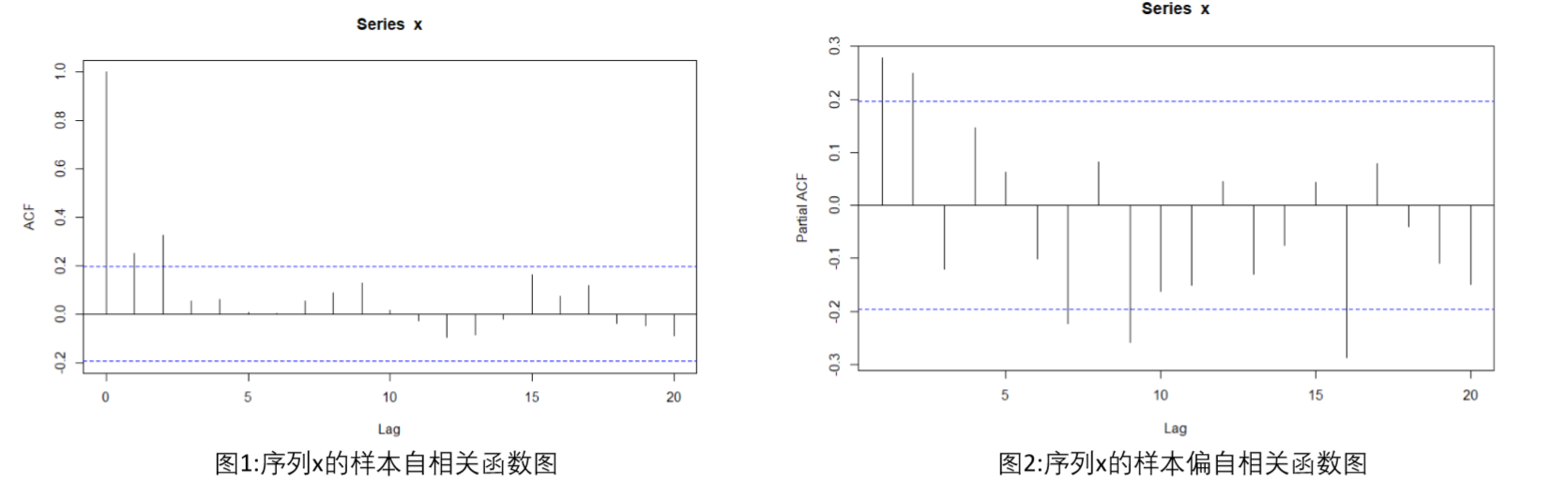
具体到数据图中:
- 自相关函数图拖尾,偏自相关函数图 3 3 3 阶截止,因此为 AR(3)。

- 偏自相关函数图拖尾,自相关函数图 2 2 2 阶截止,因此为 MA(2)。
5. 模型选择准则
- 赤池信息准则 AIC
A I C = 2 ( 模 型 中 参 数 的 个 数 ) − 2 l n ( 模 型 的 极 大 似 然 函 数 值 ) AIC=2(模型中参数的个数)-2ln(模型的极大似然函数值) AIC=2(模型中参数的个数)−2ln(模型的极大似然函数值) - 贝叶斯信息准则 BIC
B I C = l n ( T ) ( 模 型 中 参 数 的 个 数 ) − 2 l n ( 模 型 的 极 大 似 然 函 数 值 ) BIC=ln(T)(模型中参数的个数)-2ln(模型的极大似然函数值) BIC=ln(T)(模型中参数的个数)−2ln(模型的极大似然函数值)
T T T:样本个数。
模型中参数个数:反映模型的复杂程度。
模型的极大似然函数值:反映模型对于数据的拟合程度。
6. 判断模型是否识别完全
- 对残差进行检验,如果是白噪声说明识别完全,否则表示识别不完全。
- Q 检验
- H 0 : ρ 1 = ρ 2 = ⋯ = ρ s = 0 , H 1 : H_0:\rho_1=\rho_2=\dotsb=\rho_s=0,H_1: H0:ρ1=ρ2=⋯=ρs=0,H1: 至少有一个 ρ i \rho_i ρi 不为 0 0 0。
- 构造统计量 Q = T ( T + 2 ) ∑ k = 1 s r k 2 T − k ∼ χ 2 ( s − n ) Q=T(T+2)\sum _{k=1}^s\frac{r_k^2}{T-k}\sim \chi^2(s-n) Q=T(T+2)k=1∑sT−krk2∼χ2(s−n)
- T T T 表示样本的个数, n n n 表示模型中未知参数的个数(ARMA(p,q) n=p+q+1), s s s 根据样本量大小进行选取。
7. ARIMA(p,d,q)
- 目的:处理非平稳有 d d d 阶单位根的数据,进行 d d d 阶差分。
y t ′ = Δ d y t = ( 1 − L ) d y t y'_t=\Delta^dy_t=(1-L)^dy_t yt′=Δdyt=(1−L)dyt
y t ′ = α 0 + ∑ i = 1 p α i y t − i ′ + ϵ t + ∑ i = 1 q β i ϵ t − i ⇌ ( 1 − ∑ i = 1 p L i α i ) ( 1 − L ) d y t = α 0 + ( 1 + ∑ i = 1 q L i β i ) ϵ t y'_t=\alpha_0+\sum_{i=1}^{p}\alpha_iy'_{t-i}+\epsilon_t+\sum_{i=1}^{q}\beta_i\epsilon_{t-i}\rightleftharpoons (1-\sum_{i=1}^pL^i\alpha_i)(1-L)^dy_t=\alpha_0+(1+\sum_{i=1}^qL^i\beta_i)\epsilon_t yt′=α0+i=1∑pαiyt−i′+ϵt+i=1∑qβiϵt−i⇌(1−i=1∑pLiαi)(1−L)dyt=α0+(1+i=1∑qLiβi)ϵt
下面是 ARIMA(1,1,1)的曲线图
8. SARIMA模型
- 目的:增加对季节性因素的考虑。
S A R I M A ( p , d , q ) ( P , D , Q ) m SARIMA(p,d,q)(P,D,Q)_m SARIMA(p,d,q)(P,D,Q)m m m m 表示周期数。
