第一节:概论
1.1 what is NLP?
NLP=NLU+NLG
- NLU: 语音/文本=>meaning (understanding)
- NLG: 意思=> 文本/语音 (generation)
1.2 why NLP is harder?
- challenge: multiple ways to express
- challenge2: ambiguity:一词多义,需要解决词在不同语境下的意思
今天参观了苹果公司/现在正好是苹果季节
1.3 how to solve ambiguity
对于interest的意思
- bank loan
- concern fascination
- part ownership

interest在文本中的语义为concern fascination的概率为80%
1.4 solving ambiguity:learning from data
观测该词在句子中的语境,看到data时,更新对于词义的认知
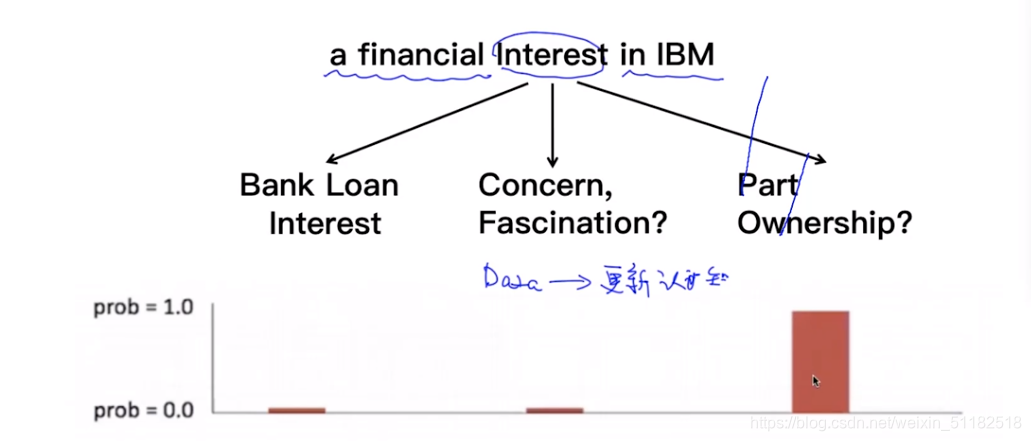
考虑了上下文,前面词为financial,后面的词为IBM,interest的词义为part ownership的概率大幅度增加。通过context information定义词的语意。
1.5 Case study: Machine Translation 机器翻译
使用每个单词对应的另外一种语言的单词从而构建整体语句翻译的缺点:
- slow : 使用模型解决
- 语意
- 没有考虑上下文
- 语法错误
- 需要规则统计
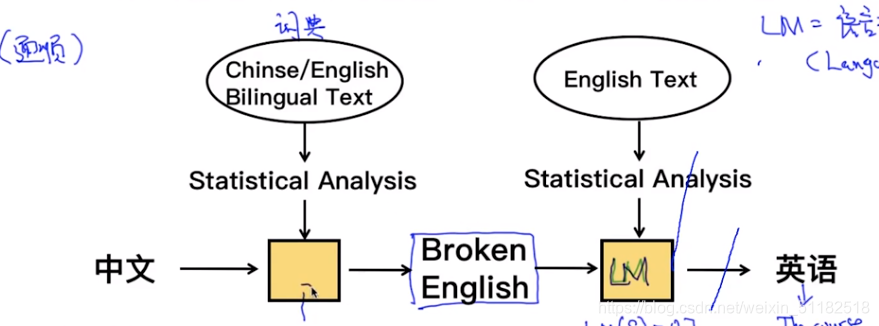
1.6 statistical machine translation
- 1、分词:
今晚的课程有意思===> 今晚 / 的 / 课程 / 有意思 - 2、翻译:
tonight / of / the course / interesting 得到的是broken English - 3、可以将broken English排列组合
选择最合适的句子 - 4、如何判断最适合的模型:(LM:传入一个句子,输出一个概率,概率代表是不是一句原话)
LM:language model,判断翻译的话有多大概率是人话。
tonight of interesting course:0.3
of tonight,interesting,course:0.15
the course of tonight,interesting:0.85
综上,第三个句子有最大的概率符合原话的语法,选择它作为翻译后的结果。
- 5、结果:
the course of tonight interesting
Figure.1: statistical machine translation
使用该方法的缺点:
计算量很大,对于四个单词的句子,所有可能的组合为4!对于100个单词的组合句子,所有的可能为100!,时间复杂度很高 O ( 2 n ) O(2^n) O(2n), 指数级的复杂度是不好的。
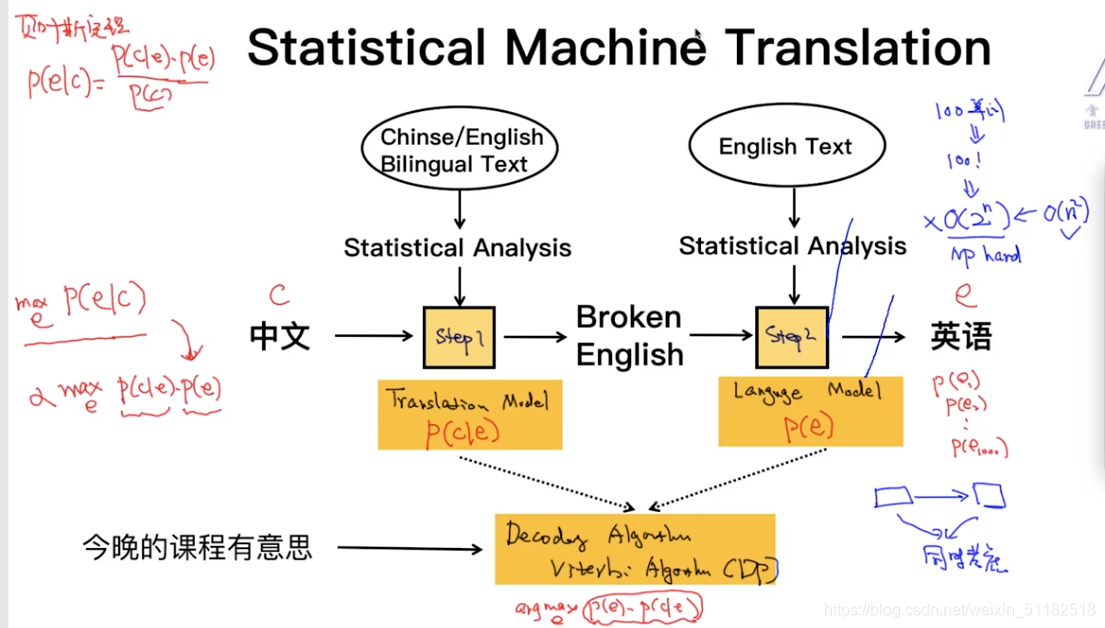
1.7 Decoding algorithm:Viterbi algori(DP:动态规划)
translation model+language model
贝叶斯定理

条件概率:给定一个中文,找到使他概率最大化的那个英文。
同时考虑给定e时,c的概率和后续的出现的e的概率
Three problems
语言模型:
- 给定一句英文e,计算概率
- 如果是符合英文文法的,p(e)会高
- 如果是随即语句,p(e)会低
翻译模型:
- 给定一对<c,e>计算p(c|e)
- 语意相似度高,则p会大
- 语义相似度低,则p会小
decoding algorithm
- 给定语言模型,翻译模型和f,找出最优的使得p(e)p(c|e)最大
对于一个好的模型
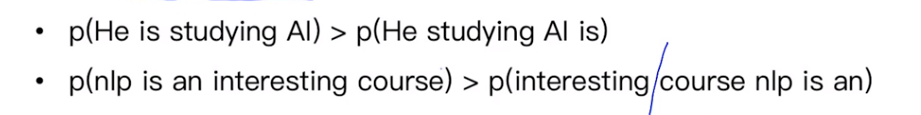
如何计算p(.)

- 第一个 Uni-gram:每一个单词出现是独立的
- 第二个 Bi-gram:每一个单词出现的概率会参考上一个单词
- 第三个 Tri-gram:每一个单词出现的概率会参考前两个单词
语言模型的训练就是训练每个词的概率
本质在于怎么把 p ( x 1 , x 2 , x 3 , x 4 ) p(x_1,x_2,x_3,x_4) p(x1,x2,x3,x4)的联合概率表示出来
p ( x 1 , x 2 , x 3 , x 4 ) = p ( x 1 ) p ( x 2 ∣ x 1 ) p ( x 3 ∣ x 2 , x 1 ) p ( x 4 ∣ x 3 , x 2 , x 1 ) p(x_1,x_2,x_3,x_4)=p(x_1)p(x_2|x_1)p(x_3|x_2,x_1)p(x_4|x_3,x_2,x_1) p(x1,x2,x3,x4)=p(x1)p(x2∣x1)p(x3∣x2,x1)p(x4∣x3,x2,x1)
Markoev assumption:简化联合分布的条件
unigram:不考虑条件概率,每个x条件独立
bi-gram:当前词出现的概率只由前一个所影响
tri-gram:当前词出现的概率只有前两个词所影响,与其他词条件独立
1.7 NLP的应用场景:
- Question answering
- Sentiment analysis(情感分析)
股票价格预测
产品评论
事件检测 - Machine Translation (机器翻译)
auto-encoder+LSTM - text summarization (自动提取摘要)
- chatbot (聊天机器人)
- Information Extraction (信息抽取)
1.8 NLP关键技术
NLP可以归为四个维度
- Phonetics 声音
- Morphology 单词
分词
pos(词性)
NER 命名实体识别
这一层的技术是NLP的基础架构 - Syntax 句子结构
词与词之间的关系
句法分析:主谓宾拆分
依存分析:dependency,给定一句话,分析每个单词之间的关系。 - Semantic 语义
NLU: 理解语意
word segmentation(分词)
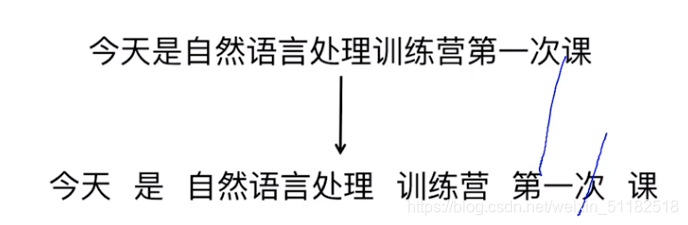
part-of-speech (词性)
重要的特征
Named Entity Recognition(命名实体识别)
命名实体基本都为名词
今天是1月22日,暂时课程以zoom的方式直播
对于医疗行业,可以抽取药品名字和症状
nldk开源库
parsing 句法分析
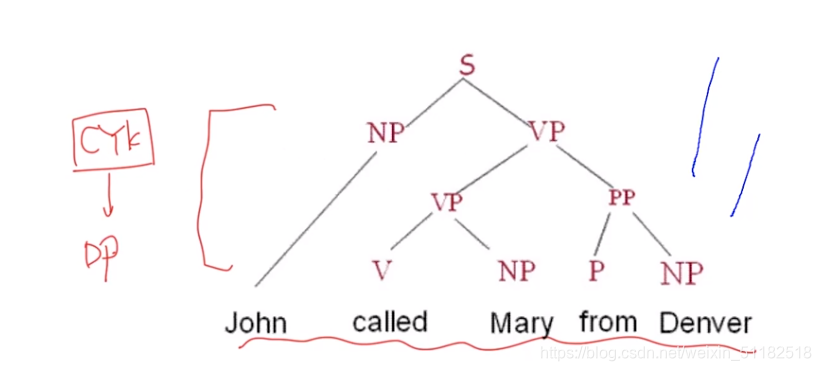
Dependency Parsing(依存分析)
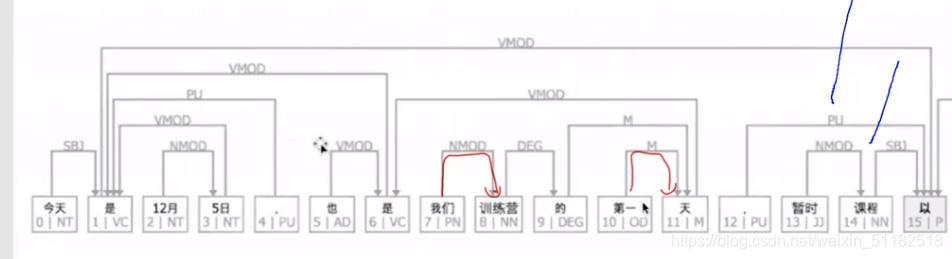
分析句子中词与词之间的依赖关系
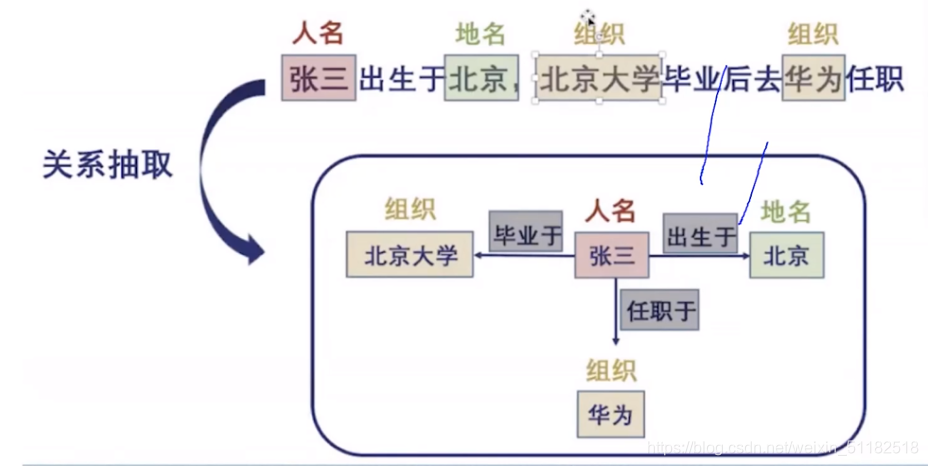
Relation Extraction(关系抽取)