论文题目:Region Proposal by Guided Anchoring
arXiv: https://arxiv.org/abs/1901.03278
参考文章:https://zhuanlan.zhihu.com/p/55854246
简单介绍
这篇论文主要是对RPN存在的缺点的改进,说是改进也不准确,因为两者的方法是有很大区别的,但他们做的工作时相同的,都是为了得到候选区域。。
本篇论文提出来一种新的方法,不需要使用预先设定的anchor box

论文介绍
RPN的缺点
(1)anchor 的尺度和长宽比需要预先定义,这是一个对性能影响比较大的超参,而且对于不同数据集和方法需要单独调整。如果尺度和长宽比设置不合适,可能会导致 recall 不够高,或者 anchor 过多影响分类性能和速度;
(2)大部分的 anchor 都分布在背景区域,对 proposal 或者检测不会有任何正面作用;
(3)预先定义好的 anchor 形状不一定能满足极端大小或者长宽比悬殊的物体。
GA-RPN
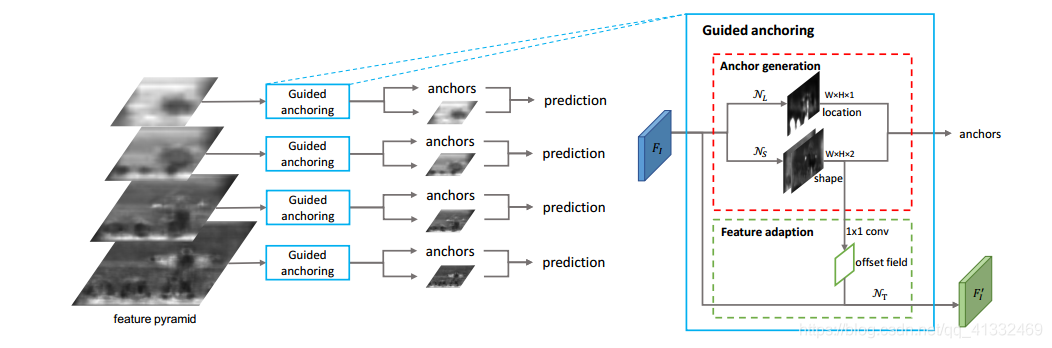 这是模型的总体结构,主要的关注点是在右侧guided anchoring这个部分,这也这篇论文的精华所在。
这是模型的总体结构,主要的关注点是在右侧guided anchoring这个部分,这也这篇论文的精华所在。
中心点预测
在拿到feature map 之后,传统方法就开始进行滑动窗口,把每个像素点都当做中心产生候选区域,前边已经说过这种方法的缺点,大量背景也产生了大量无效的候选区,如何避免这个问题呢?
我们需要有针对行的把一些像素点当做中心就可以了,具体怎么做呢,就是上图的NL部分,通过对feature map进行1×1的卷积,然后对卷积后的值进行sigmoid,就得到了一个概率图(probability map),而概率图中每个点的值代表这个点为目标中心点的概率,然后设定一个阈值,大于某个概率即说明这个点很有可能作为某个目标的中心点,接下来以这个点为中心,针对性的产生候选框即可,从而避免了滑动窗口的缺点。
那么如何学习(训练)到这样一个模型呢?
论文将整个 feature map 的区域分为物体中心区域,外围区域和忽略区域,大概思路就是将 ground truth 框的中心一小块对应在 feature map 上的区域标为物体中心区域,在训练的时候作为正样本(target = 1),其余区域按照离中心的距离标为忽略或者负样本(target = 0),这样,有了目标值,训练即可,论文使用Focal loss来训练这个分支。
这样我们就得到了一个产生中心点概率图的模型NL,接下来要在中心点上产生边框(确定w和h的值)
形状预测
形状预测模型为上图中的Ns部分,具体是采用1×1的卷积核,产生一个双通道的feature map,但直接预测w和h不好预测,你所以转而预测dw和dh,之后经过公式转换得到w和h,公式如下:
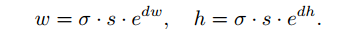
拿如何训练这个预测模型呢?
训练过程最重要的是要找到w和h的目标值,对于以前常规的 anchor,w和h是事先规定好的,我们可以直接计算它和所有 ground truth 的 IoU,然后将它分配给 IoU 最大的那个 gt,gt的w和h即为目标值。但是很不幸现在的 anchor 的 w 和 h 是不确定的,是一个需要预测的变量,该怎么办呢?sample anchor。
论文将这个 anchor 和某个 gt 的 IoU 表示为:
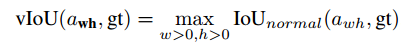
我们不可能真的把所有可能的 w 和 h 遍历一遍然后求 IoU 的最大值,所以采用了近似的方法,也就是 sample 一些可能的 w 和 h。理论上 sample 得越多,近似效果越好,但出于效率的考虑,所以 sample 了常见的 9 组 w 和 h。
形状预测损失函数:

这样Ns位置预测分支也准备好了可以画框了。
可以看到,anchor 基本都集中在有目标的区域,确实产生了不错的效果。

Feature Adaption 模块
但是我们发现一个不合理的地方,大家都是同一层 conv 的特征,凭啥我就可以比别人优秀一些,代表一个又长又大的 anchor,你就只能代表一个小小的 anchor。
不合理的原因一方面在于,在同一层 conv 的不同位置,feature 的 receiptive field 是相同的,在原来的 RPN 里面,大家都表示相同形状的 anchor,所以相安无事,但是现在每个 anchor 都有自己独特的形状大小,和 feature 就不是特别好地 match。另一方面,对原本的特征图来说,它并不知道形状预测分支预测的 anchor 形状,但是接下来的分类和回归却是基于预测出的 anchor 来做的,可能会比较懵逼。
我们增加了一个 Feature Adaption 模块来解决这种问题,把 anchor 的形状信息直接融入到特征图中,这样新得到的特征图就可以去适应每个位置 anchor 的形状。我们利用一个 3x3 的 deformable convolution 来修正原始的特征图,而 deformable convolution 的 offset 是通过 anchor 的 w 和 h 经过一个 1x1 conv 得到的。(此处应该划重点,如果是像正常的 deformable convolution 一样,用特征图来预测 offset,则提升有限,因为没有起到根据 anchor 形状来 adapt 的效果)
通过这样的操作,达到了让 feature 的有效范围和 anchor 形状更加接近的目的,同一个 conv 的不同位置也可以代表不同形状大小的 anchor 了。