&论文概述
论文题目:Region Proposal by Guided Anchoring
作者&出处:Jiaqi Wang, Kai Chen, Shuo Yang, Chen Change Loy, Dahua Lin || CUHK-Sense Time Joint Lab, The Chinese University of Hong Kong, Amazon Rekognition, Nanyang Technological University
获取地址:https://arxiv.org/abs/1901.03278
&总结与个人观点
提出了Guided Anchoring机制,利用语义特征来指导anchor的生成。通过结合对location以及shape的独立预测,生成非一致的有任意shape的anchor。该方法相比于使用滑动窗后机制的RPN来说,提升了9.1%的recall以及生成的anchor数量减少了10%,可以应用与基于anchor的检测器,也能提升2.7%。
这篇论文中,我还存在很多没弄明白的地方,不过大致的思路很好,尤其是将anchor的计算分成location以及shape,然后考虑两者之间的相关性,使得anchor的生成数量大大减少以及质量也随之提升。
&贡献
1) 提出能够预测非定形及任意形状的anchor的新策略,而不是使用预定义及紧密排列的anchor集合;
2) 将联合anchor分布分解为两个条件分布,并分别设计了模型;
3) 研究特征与响应anchor对齐的重要性,设计了特征调节模型以精炼基于潜在anchor形状的特征。
&拟解决的问题
问题:当前使用的统一的预设定的anchor策略并不是最优的
分析:
一个合理的anchor的设计有2个原则:alignment & consistency:
1) 为使用卷积特征作为anchor的表征,anchor的中心需要与特征图中对应位置的中心对齐。这里指的是在原图中每一个anchor的中心,在经过下采样/卷积池化过程时,不能出现位置偏移,即anchor中心位置是stride的整数倍。从这个观点上来说,直接将对应特征图中的像素作为其anchor的中心点,然后再根据anchor的size与纵横比进行选取即可,这也是当前基于anchor的方法采用的主流思想;
2) 感受野与语义范围(scope)应当与特征图上不同位置的anchor的尺度与形状一致。如此说来,基于有效感受野的S3FD岂非违背了该原则,其使用的有效感受野的范围与anchor的尺度与形状不一致。
基于这两个原则,当前使用的统一的anchor的策略为:在特征图上的每个位置都有预定义尺度以及aspect ratios的k个anchor。而这并不是一个最优的方法,其中仍然存在缺陷:
- 对于不同的问题需要预定义固定的aspect ratios的anchor集合,而错误的设计可能阻碍检测器的速度以及精度;
- 为保持足够高的召回率,需要使用大量的anchor,然而大部分都是negative anchor,且导致极大的计算开销,尤其是在对候选区域使用heavy的分类器时。
根据观察分析,在图片中的目标并不是均匀分布的,目标的尺度与图片的内容、自身的位置以及场景中的几何形状密切相关。因此,为减轻手工选择的先验(hand-picked pirors)问题,提出方法:先确定可能包含目标的子域,再在不同的位置确定anchor的形状。
而这种方法中的尺度与纵横比是可变的,因此不同的特征图像素需要学习合适(fit)相应anchor的适应性表征。这破坏了anchor的一致性原则。提出一个基于anchor几何特征的有效模块。
| Previous methods |
GA |
| 通过滑动窗口的选取密集的、归一化的anchors |
去除滑动窗口机制,使用更优的机制来指导生成稀疏的anchors |
| 级联的检测器采用多余1个阶段以逐步精炼检测bbox,引入更多的模型参数,降低推断时的速度;使用RoI Pooling/Align为bbox提取对应的特征,这对于一阶段检测器以及候选区域生成的花销都过大 |
|
| Anchor-free的方法采用简单的pipelines,使用单阶段生成最终的检测结果。由于anchors以及对基于anchor的精炼的缺乏,不能处理复杂场景以及实例 |
关注点在于使用稀疏的,非定形的anchor选取机制,使用高质量的候选区域以提高检测性能。因此需要解决misalignment & inconsistency问题。 |
| 一些single-shot检测器使用多回归与分类以精炼anchors |
不逐步精炼anchor,而是直接预测anchor的分布,该部分被分解为location以及shape预测 |
| 未考虑anchor与特征间的对齐,因此多次回归anchor,破坏了alignment & consistency |
之预测anchor的shape,固定anchor的中心,然后基于预测的形状来调整特征。 |
&框架及主要方法
1、主要模型
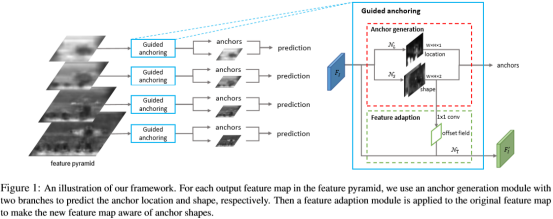
2、联合分布分解
p(x, y, w, h | I) = p(x, y | I)p(w, h | x, y, I)
从这个分解的概率分布可以得到两个重要的信息:1) 图片中的目标可能存在于特征的区域;2) 目标的形状,如尺度与纵横比,与位置紧密相关。同时,通过上述的概率分解可以将图片中对于anchor的预测,分解为anchor中心预测,以及中心处形状的预测。
3、Anchor的位置预测
该分支预测得到一个可能性分布p(·| FI),得到特征图FI中的每个location可能为目标中心的概率。P(x, y | FI)在图像I中的相应位置为((x+1/2)s, (y+1/2)s),及对应在原图中的感受野的中心处,其中s是特征图的stride。
在这个子网络中对FI使用1×1卷积来获得目标得分图,然后通过元素级的sigmoid函数转化为对应的可能性。使用更深的子网络能够获得更精准的预测,且在卷积层后使用sigmoid变换能够在效率与精度间达到一个好的平衡。

对这个可能性图中,设定阈值,能够过滤90%的区域同时保留相同召回率。如上图为可能性图。由于不需要考虑排除的区域,为更高效的推荐,将ensuring卷积层替换为masked卷积。
4、Anchor的形状预测
在anchor的shape预测分支中,预测每个位置的w与h,使得能够与最近的ground truth box的覆盖率最大。但由于直接预测(w, h)的范围太大,最后的精度也不准,故使用下面的转换形式:
w = σ·s·edw,h = σ·s·edh
最后转换为预测(dw, dh),此时σ=8,整体将[0, 1000]的范围转换为[-1, 1],使得预测的结果更稳定也更简单。


每个location仅与一个动态预测shape的anchor相关联;由于其能够允许任意的aspect ratios,该方法能够更好地捕获过高或过宽的目标。上图(左)为预测的anchor的纵横比的变化,(右)是通过location以及shape对应生成的anchor的显示。
5、Anchor-Guided特征适配
传统的RPN或者单阶段检测器使用预定义的anchor,每个位置共享相同尺度与纵横比的anchor,因此特征图可以学习一致的表征。而此时每个location上的anchor的shape各不相同,故直接使用传统方法的网络处理anchor并不适当。
根据分析,大的anchor会编码较大范围的内容,对应的,小的anchor编码的范围也较小。因此提出anchor-guided feature adaption来对在每个独立的基于潜在的anchor形状的location上的特征做变换:
fi’ = NT(fi, wi, hi)
其中fi是location(xi, yi),NT是一个3×3的可变形卷积层。
首先从预测的shape分支的输出预测offset field,然后使用这个offset对原始的特征图使用可变形卷积获得fi’,在调整的特征后可再做分类与bbox回归。
6、损失设置
L = λ1Lloc + λ2Lshape + Lcls + Lreg
上方为总的损失函数,在分类与回归的基础上添加了location以及shape的损失。
1) Location的损失计算
对于每张图片需要一个二值标签图,其中1表示定位anchor的有效location。在这个过程中,使用ground truth指到二值标签的生成,希望在目标的邻域能够有着更多的有效location,越远则越少。使用(xg, yg, wg, hg)表示ground truth box,(xg’, yg’, wg’, hg’)表示ground truth box映射到对应的特征图尺度的结果。R(x, y, w, h)表示以(x, y)为中心,(w, h)分别为宽和高的矩形。希望Anchor能够放置在靠近bbox中心的位置,以获得更大的初始化IoU,因此对每个bbox定义3种类型的区域如下:
- CR=R(xg’, yg’, σ1w’, σ1h’)表示bbox的中心区域,这部分区域视为正样本;
- IR=R(xg’, yg’, σ2w’, σ2h’)\CR表示除CR外更大的区域,这部分为忽略的区域,类似于Gray Zone的概念;
- OR是除了CR与IR外的区域,为负样本。

由于使用了FPN中的多层特征层,也考虑相邻层级中的相互影响,设定每个特征层只关注特定尺度范围内的目标,因此CR只在特征图匹配特征尺度范围的目标时才存在,相邻层的相同区域也设置为IR,具体如上图所示。在多目标重叠时,CR会抑制IR,同时IR会抑制OR。因为CR只存在于整个特征图的一小部分,故使用Focal Loss来训练location分支。
2) Shape的损失计算
首先将anchor与相应的ground truth进行匹配,然后预测能够与匹配的ground truth有最大IoU的w与h。
awh={(x0, y0, w, h) | w>0, h>0},gt=(xg, yg, wg, hg)
vIoU=max IoUnormal(awh, gt)
对于任意的location与ground truth来说,计算vIoU是相当复杂的,而且很难有效地设计一个端到端地网络。因此使用一个近似的方法:对于给定的(x0, y0),取样一些常用的w,h值来模拟对所有w,h的枚举。然后计算取样的anchor与gt的vIoU。在实验中,选取了9组(w, h),如RetinaNet中的尺度与纵横比。最终的损失计算如下:
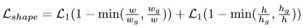
7、实验结果
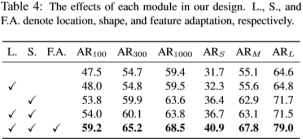
对于anchor的两个原则:alignment & consistency进行实验验证其对于整体结果的影响,如下表所示,在保证这两个原则的情况下能够对召回率的提升起到较大的作用。其中AR后的100、300、1000为proposal的数量。

针对文中提出的三种tricks,location、shape以及feature adaption的消融实验,实验表明将anchor的选取分成两个部分:location与shape进行计算对结果有着较大的提升,且经过feature adaption结果差不多增加了5个点左右。
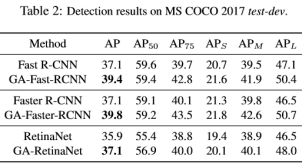
下表为在不同的检测方法中使用GA生成anchor与原先方法的对比,从中可以看出使用了GA的平均能够提升2个点左右。
下图分别是ground truth以及使用GA、sliding Window分别生成的anchor的尺度以及纵横比的分布比较,由于sliding window使用的是预定义的尺度以及纵横比,所以在下图中生成的anchor不具有多样性,而通过GA生成的anchor更符合ground truth boxes的分布。

下表是针对Faster R-CNN中的RPN模块与使用了GA的RPN模块,即对于RPN使用了更高质量的anchor的结果对比,可以看出使用了GA的RPN策略明显更胜一筹,同时下图也对RPN与GA-RPN生成的anchor显示出来进行对比,相对于RPN来说,GA-RPN生成的anchor的质量更高,而且数量更少。


&遇到的问题
1、在location分支中,对每个位置计算的物体的可能性,如何计算的,会不会出现有的物体没有识别出来的情况?如果阈值设置的不合理,结果也会与真实值出现偏离,阈值应该如何选取?
2、此时使用的anchor是根据location与shape获得的,若是按照正常情况来看,shape预测分支也仅能预测出一组(w, h),这里怎么进行可变形操作?
3、如果使用与RetinaNet相同的anchor的设定,那么是否可以意味着使用着类似的anchor设定的方法都有达到这种结果的潜力,相比来说,如果RetinaNet直接对9个anchor进行最大IoU的计算,岂非和GA的shape预测的结果相同?那GA方法相对于RPN的性能增加主要是增加在location与offset方面?
4、计算vIoU时,求的是达到覆盖率最大的w,h,如果同一个区域被2个或以上的GT覆盖,应当如何处理?
&思考与启发
这篇论文中最亮的点是将anchor的预测分解成对location以及shape的分别预测,之后进行整合的操作,而通过对shape的预测,又能得到各式各样的尺度以及纵横比,大大提高了对困难检测样本的检测精度。将一个任务分解为多个任务可能对原先的任务起到了提高性能的作用。
这里面还存在一些问题,没有搞懂,需要看一下对应的代码部分,之后再整合。