展示了一个能更好地处理常见错误情况的广义翘曲算子(generalized warping operator) (Q: 这是什么东东?)。
提出尺度空间流,这是光流的直观概括,它添加了尺度参数以允许网络更好地对不确定性进行建模
双线性翘曲(bilinear warping)通过2通道位移场\((f_x,f_y)\)来直接从2D源图像采样
这篇论文对双线性翘曲做了扩展,通过3通道位移+标度场(displacements+scale field)\((g_x,g_y,g_z)\)来对三维标度空间体积进行三线性采样
(Q: 位移场怎么定义怎么求? 标度场怎么定义怎么求? 三线性采样具体怎么采样?)
Bilinear Warping:
Given an image \(x\) shape \(H \times W\) and a flow field \(f=(f_x,f_y)\)
We refer to the flow channels \(f_x,f_y \in \mathbb{R}^{H \times W}\) as the x- and y- displacement fields of the flow \(f\).
Construct a fixed-resolution scale-space volume \(X=[x,x*G(\sigma_0),x*G(2\sigma_0),...,x*G(2^{M-1} \sigma_0)]\)
\(x*G(\sigma)\)表示\(x\)经过尺度为\(\sigma\)的Gaussian kernel卷积后得到的结果
\(X\)为一堆逐渐模糊的\(x\)的叠加, 尺寸为\(H \times W \times (M+1)\)
通过三线性插值(trilinear interpolation),可以在连续坐标\((x,y,z)\)下采样
Scale-space Warping:
Define a scale-space flow field as a 3-channel field \(g:=(g_x,g_y,g_z)\)
scale-space warp of image \(x\) is:
第三维\(g_z\)称为scale-space flow \(g\)的scale field.
We set \(M=5\) in all of our experiments.
Trilinear interpolation:
In-between two levels \(i<=z<i+1\), with corresponding Gaussian kernel sizes \(\sigma_a\) and \(\sigma_b\)
So when given a desired effective kernel size \(0<\sigma<2^{M-1}\sigma_0\), we can easily solve for the corresponding value:
Compression Model:
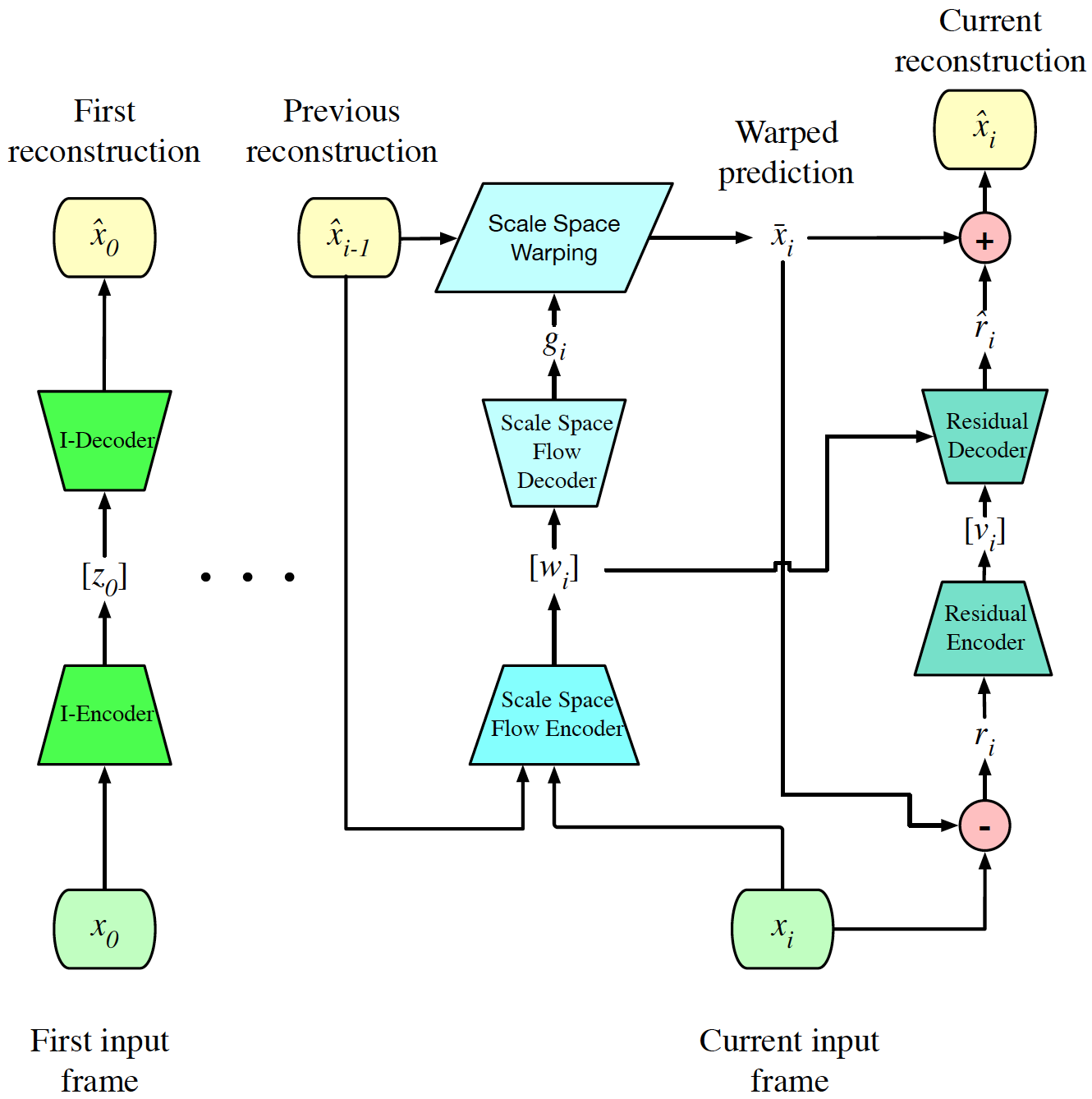
Given a sequence of frames \(x_0,...,x_N\)
- 将第一帧(I)编码为潜变量\(z_0\), \(z_0\)量化为一个整数\([z_0]\), 再得到重构\(\hat{x}_0\)
- 对于当前给定的帧(P), 用单个神经网络来联合估计和编码量化the quantized scale-space warp latents \([w_i]\), 从中解码得到scale-space flow \(g_i\)
- 对前面的重构\(\hat{x}_{i-1}\)进行scale-space warp, 获得当前帧的估计\(\overline{x}_i\)
- 但是\(\overline{x}_i\)是不完美的,另一个分支会对残差\(r_i=x_i-\overline{x}_i\)进行编码, 得到潜变量\([v_i]\),并解码得到\(\hat{r}_i\), 最终的重建为\(\hat{x}_i=\overline{x}_i+\hat{r}_i\)
总共有三个潜变量:
- image latent \(z_0\)
- motion compensation latents \(w_i\)
- residual latents \(v_i\)
对每个潜变量, 用一个单独的超先验(hyperprior)来建模相应的密度
Optimize the whole system for the total rate-distortion loss unrolled over N frames:
\(H(.)\)表示各个潜变量的熵估计(entropy estimate),包括超先验提取的边缘信息,\(d\)表示失真度量如MSE或MS-SSIM.
Overview of this end-to-end optimized low-latency compression system: