Based on VAE
Steps:
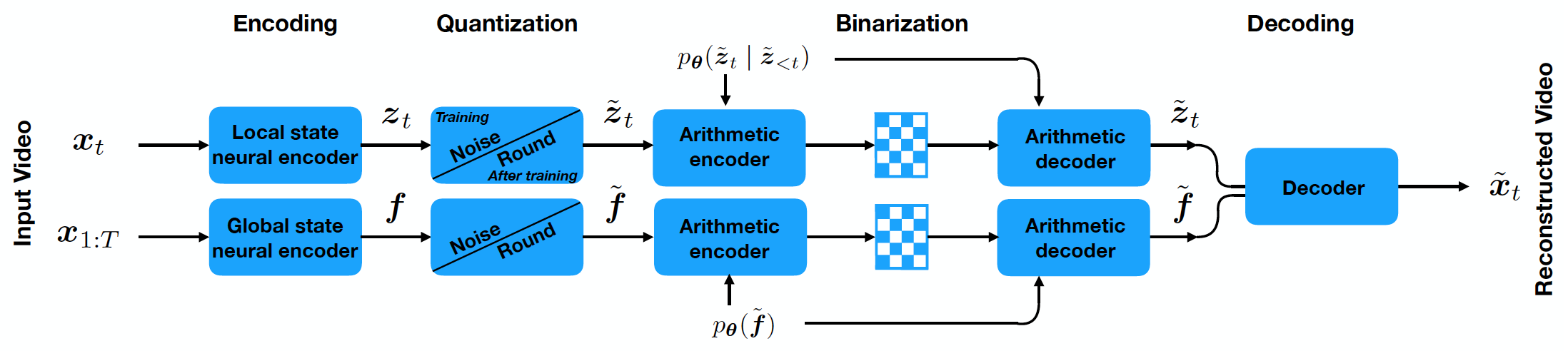
- Transform a sequence of frames \(x_{1:T}=(x_1,...,x_T)\) to a sequence of latent states \(z_{1:T}\) and optionally a global state \(f\). This transformation is lossy, but the video is not optimally compressed as there are still correlations in the latent space variables.
- So the latent space must be entropy coded into binary.
- The bit stream can then be sent to a receiver where it is decoded into video frames.
(Q: 为什么要先变成latent variables? 直接entropy coding不行吗?)
So we need two models:
- optimal lossy transformation into the latent space.
- predictive model required for entropy coding.
Temporal model is most important for videos, because video exhibit strong temporal correlations in addition to the spatial correlations present in images.
So we propose to learn a temporally-conditioned prior distribution parameterized by a deep generative model to efficiently code the latent variables associated with each frame.
Notation:
\(x_{1:T}=(x_1,...,x_T)=\)video sequence, \(z_{1:T}=\)associated latent variables, \(f=\)global variables(optionally)
Arithmetic coding:
Coding the entire sequence of discretized latent states \(z_{1:T}\) into a single number. Use conditional probabilities \(p(z_t|z_{<t})\) to iteratively refine the real number interval \([0,1)\) into a progressively smaller interval. (Q: 具体怎么调整的?) After a final (very small) interval is obtained, a binarized floating point number from the final interval is stored to encode the entire sequence of latents.
Decoder: f(latent)=data
Use a stochastic recurrent variational autoencoder(随机循环变分自编码器) that transforms a sequence of local latent variables \(z_{1:T}\) and a global state \(f\) into the frame sequence \(x_{1:T}\)
Encoder:
Use amortized variational inference(平摊变分推理) to predict a distribution over latent codes given the input video.
采用以均值为中心的固定宽度均匀分布:
均值通过附加的编码器神经网络得到:
The mean for the global state is parametrized by convolutions over \(x_{1:T}\), followed by a bi-directional LSTM which is then processed by a MLP.
The encoder mean for the local state is simpler, consisting of convolutions over each frame followed by a MLP.
论文中假设全局先验\(p_\theta(f)\)是固定的,而\(p_\theta(z_{1:T})\)由时间序列模型组成
有两种方法可以对潜变量序列\(z_{1:T}\)建模:
- A recurrent LSTM prior architecture for \(p_\theta(z_t^i|z_{<t})\) which conditions on all previous frames in a segment.
- 单帧上下文, \(p_\theta(z_t^i|z_{<t})=p_\theta(z_t^i|z_{t-1})\), 本质上是一个Kalman filter
通过最大化\(\beta-VAE\)目标函数,可以联合学习encoder(变分模型)和decoder(生成模型)
第一项表示失真,第二项表示近似后验和先验的交叉熵
模型: