MCMC是我不太容易理解的一个技术点,需要多做一些联系。
MLaPP第24.2.3节介绍了一个使用Gibbs Sampling确定Gaussian Mixture Model(GMM)的范例,但过于简单;同时代码库中提供了一个范例函数gaussMissingFitGibbs,但并未详细介绍如何使用。
我在此范例程序的基础上,修改完成一个针对GMM数据的聚类程序。
下列程序与范例相比gaussMissingFitGibbs相比,1. 删除了x数据有缺失的部分代码;2. 完成了完整的GMM聚类过程(因此需要引入Dirichlet抽样);3. 增加了自动生成聚类数的代码(但是,这部分不太稳定,还需要继续研究)。
在这个过程中,除了理解Gibbs Sampling算法之外,个人认为最重要的是找到必须的抽样函数,包括Dirichlet抽样和IW抽样,这两部分都是使用了MLaPP提供的范例函数。
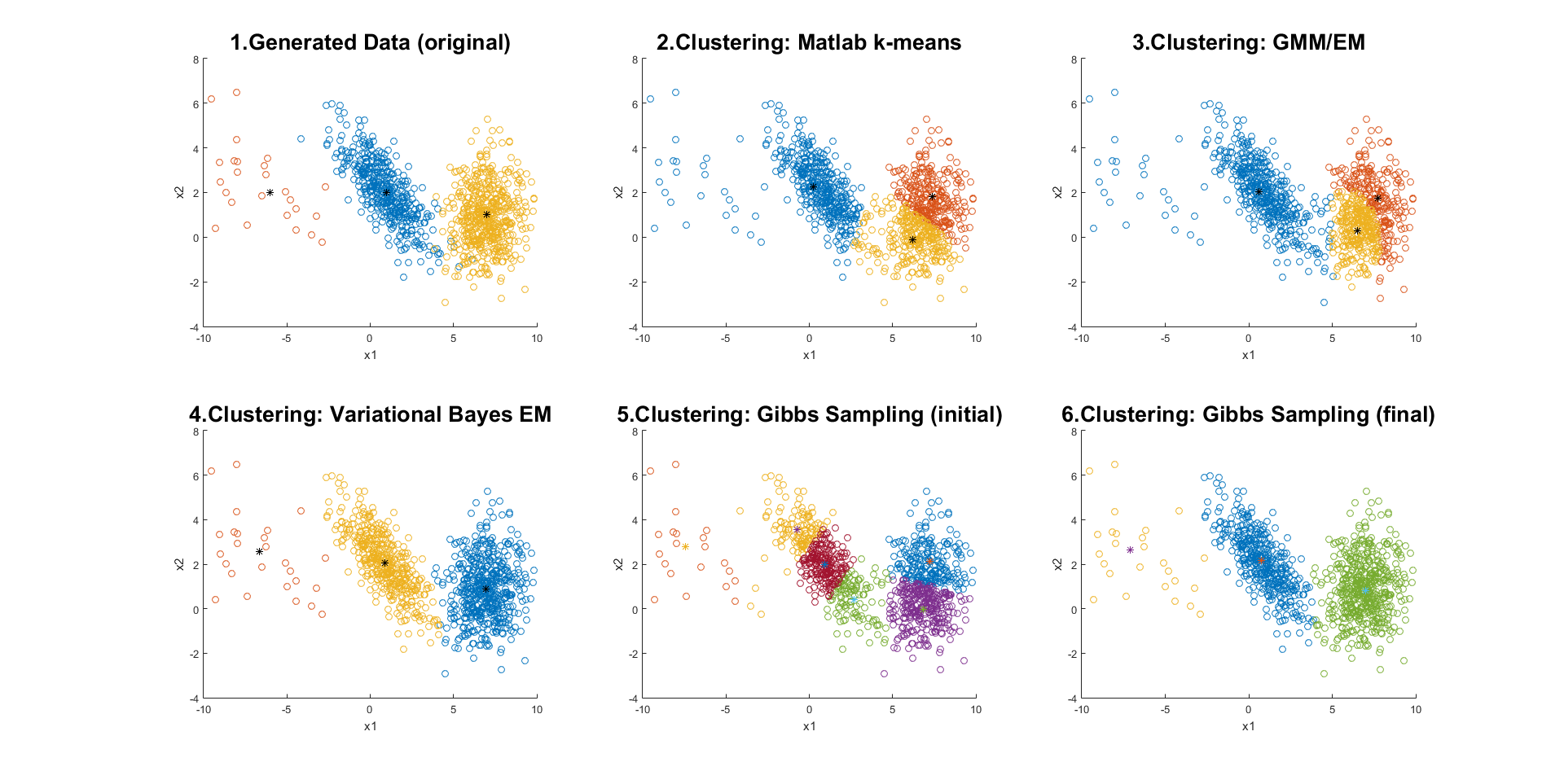
输出结果如下:
代码(主程序)
clear all;
close all;
rng(2);
%% Parameters
N = 1000; % 总数据量
D = 2; % 数据维度
K = 3; % 类别数目
Pi = rand([K,1]); % 随机生成各类比例
Pi = Pi/sum(Pi);
% 数据初始化,与之前的EM聚类程序相同
mu = [1 2; -6 2; 7 1];
sigma=zeros(K,D,D);
sigma(1,:,:)=[2 -1.5; -1.5 2];
sigma(2,:,:)=[5 -2.; -2. 3];
sigma(3,:,:)=[1 0.1; 0.1 2];
%% Data Generation and display
x = zeros(N,D);
PzCDF1 = 0;
figure(1); subplot(2,3,1); hold on;
figure(2); hold on;
for ii = 1:K,
PzCDF2 = PzCDF1 + Pi(ii);
PzIdx1 = round(PzCDF1*N);
PzIdx2 = round(PzCDF2*N);
x(PzIdx1+1:PzIdx2,:) = mvnrnd(mu(ii,:), squeeze(sigma(ii,:,:)), PzIdx2-PzIdx1);
PzCDF1 = PzCDF2;
figure(1); subplot(2,3,1); hold on;
plot(x(PzIdx1+1:PzIdx2,1),x(PzIdx1+1:PzIdx2,2),'o');
end;
[~, tmpidx] = sort(rand(N,1));
x = x(tmpidx,:); % shuffle data
figure(1); subplot(2,3,1);
plot(mu(:,1),mu(:,2),'k*');
axis([-10,10,-4,8]);
title('1.Generated Data (original)', 'fontsize', 20);
xlabel('x1');
ylabel('x2');
figure(2);
plot(x(:,1),x(:,2),'o');
figure(2);
plot(mu(:,1),mu(:,2),'k*');
axis([-10,10,-4,8]);
title('Generated Data (original)');
xlabel('x1');
ylabel('x2');
fprintf('\n$$ Data generation and display completed...\n');
save('GMM_data.mat', 'x', 'K');
%% clustering: Matlab k-means
clear all;
load('GMM_data.mat');
[N,D] = size(x);
k_idx=kmeans(x,K); % 使用Matlab现有k-means算法
figure(1); subplot(2,3,2); hold on;
for ii=1:K,
idx=(k_idx==ii);
plot(x(idx,1),x(idx,2),'o');
center = mean(x(idx,:));
plot(center(1),center(2),'k*');
end;
axis([-10,10,-4,8]);
title('2.Clustering: Matlab k-means', 'fontsize', 20);
xlabel('x1');
ylabel('x2');
fprintf('\n$$ K-means clustering completed...\n');
%% clustering: EM
% Refer to pp.351, MLaPP
% Pw: weight
% mu: u of Gaussion distribution
% sigma: Covariance matrix of Gaussion distribution
% r(i,k): responsibility; rk: sum of r over i
% px: p(x|mu,sigma)
% 上面的聚类结果作为EM算法的初始值
Pw=zeros(K,1);
for ii=1:K,
idx=(k_idx==ii);
Pw(ii)=sum(idx)*1.0/N;
mu(ii,:)=mean(x(idx,:));
sigma(ii,:,:)=cov(x(idx,1),x(idx,2));
end;
px=zeros(N,K);
for jj=1:100, % 简单起见,直接循环,不做结束判断
for ii=1:K,
px(:,ii)=GaussPDF(x,mu(ii,:),squeeze(sigma(ii,:,:)));
% 使用Matlab自带的mvnpdf,有时会出现sigma非正定的错误
end;
% E step
temp=px.*repmat(Pw',N,1);
r=temp./repmat(sum(temp,2),1,K);
% M step
rk=sum(r);
Pw=rk'/N;
mu=r'*x./repmat(rk',1,D);
for ii=1:K
sigma(ii,:,:)=x'*(repmat(r(:,ii),1,D).*x)/rk(ii)-mu(ii,:)'*mu(ii,:);
end;
end;
% display
[~,clst_idx]=max(px,[],2);
figure(1); subplot(2,3,3); hold on;
for ii=1:K,
idx=(clst_idx==ii);
plot(x(idx,1),x(idx,2),'o');
center = mean(x(idx,:));
sigma(ii,:,:)=cov(x(idx,1),x(idx,2));
plot(center(1),center(2),'k*');
end;
axis([-10,10,-4,8]);
title('3.Clustering: GMM/EM', 'fontsize', 20);
xlabel('x1');
ylabel('x2');
fprintf('\n$$ Gaussian Mixture using EM completed...\n');
%% Variational Bayes EM
% Refer to ch.10.2, PRML
% x: visible variable, N * D
% z: latent variable, N * K
% z: Pz, Ppi, alp0, alpk
% Pz = P(z|pi); PRML(10.37)
% Ppi = Dir(pi|alp0) PRML(10.39)
% x: Px, Pz, Ppi, mu, lambda, m0, beta0, W0, nu0
% Px = P(x|z, mu, lambda); 高斯分布 PRML(10.38)
% P(mu, lambda) = P(mu|lambda)*P(lambda) PRML(10.40)
% = N(mu|m0, (beta0*lambda)^-1) * Wi(lambda|W0, nu0)
% rho: N*K,定义参见PRML(10.46)
% r: N*K, responsibility; 归一化之后的rho,定义参见PRML(10.49)
% N_k: sum of r over n 定义参见PRML(10.51)
% xbar_k: 定义参见PRML(10.52)
% S_k 定义参见PRML(10.53)
clear all;
load('GMM_data.mat');
[N,D] = size(x);
K = 6; % 增加分类数,利用VBEM自动选择分类数
k_idx=kmeans(x,K); % 使用Matlab自带的k-means聚类,结果作为VBEM的初始值
for ii=1:K,
idx=(k_idx==ii);
mu(ii,:) = mean(x(idx,:));
sigma(ii,:,:)=cov(x(idx,1),x(idx,2));
px(:,ii)=GaussPDF(x,mu(ii,:),squeeze(sigma(ii,:,:)));
% 使用Matlab自带的mvnpdf,有时会出现sigma非正定的错误,特使用自编函数GaussPDF
end;
% 初始化,具体定义参见PRML式(10.40)
alp0 = 0.0001; % alpha0,应<<1,以实现类别数自动筛选
m0 = 0;
beta0 = rand()+0.5; % 拍脑袋初始化
W0 = squeeze(mean(sigma));
W0inv = pinv(W0);
nu0 = D*2; % 拍脑袋初始化
S_k = zeros(K,D,D);
W_k = zeros(K,D,D);
E_mu_lmbd = zeros(N,K); % 即PRML中式(10.64)的等号左侧
r = px./repmat(sum(px,2),1,K); % N*K
N_k = ones(1,K)*(-100);
for ii = 1:1000,
% M-step
N_k_new = sum(r); % 1*K,式(11.51)
N_k_new(N_k_new<N/1000.0)=1e-4; % 避免出现特别小或为零的Nk
if sum(abs(N_k_new-N_k))<0.001,
break; % early stop,如果Nk基本没变化了,则停止迭代
else
N_k = N_k_new;
end;
xbar_k = r'*x./repmat(N_k', 1, D); % K*D,PRML式(10.52)
for jj = 1:K,
dx = x-repmat(xbar_k(jj,:), N, 1); % N*D
S_k(jj,:,:) = dx'*(dx.*repmat(r(:,jj),1,D))/N_k(jj); % D*D,PRML式(10.53)
end;
alp_k = alp0 + N_k; % PRML式(10.58)
beta_k = beta0 + N_k; % PRML式(10.60)
m_k = (beta0*m0 + repmat(N_k',1,D).*xbar_k)./...
repmat(beta_k',1,D); % K*D,PRML式(10.61)
for jj = 1:K,
dxm = xbar_k(jj,:)-m0;
Wkinv = W0inv + N_k(jj)*squeeze(S_k(jj,:,:)) + ...
dxm'*dxm*beta0*N_k(jj)/(beta0+N_k(jj));
W_k(jj,:,:) = pinv(Wkinv); % K*D*D,PRML式(10.62)
end;
nu_k = nu0 + N_k; % 1*K,PRML式(10.63)
% E-step: 迭代计算r
alp_tilde = sum(alp_k);
E_ln_pi = psi(alp_k) - psi(alp_tilde); % PRML式(10.66)
E_ln_lambda = D*log(2)*ones(1,K);
for jj = 1:D,
E_ln_lambda = E_ln_lambda + psi((nu_k+1-jj)/2);
end;
for jj = 1:K,
E_ln_lambda(jj) = E_ln_lambda(jj) + ...
log(det(squeeze(W_k(jj,:,:)))); % PRML式(10.65)
dxm = x-repmat(m_k(jj,:),N,1); % N*D
Dbeta = D/beta_k(jj);
for nn = 1:N,
E_mu_lmbd(nn,jj) = Dbeta+nu_k(jj)*(dxm(nn,:)*...
squeeze(W_k(jj,:,:))*dxm(nn,:)'); % PRML式(10.64)
end;
end;
rho = exp(repmat(E_ln_pi,N,1)+repmat(E_ln_lambda,N,1)/2-...
E_mu_lmbd/2); % PRML式(10.46)
r = rho./repmat(sum(rho,2),1,K); % PRML式(10.49)
end;
[~,clst_idx]=max(r,[],2);
figure(1); subplot(2,3,4); hold on;
Nclst = 0;
for ii=1:K,
idx=(clst_idx==ii);
if sum(idx)/N>0.01,
Nclst = Nclst+1;
plot(x(idx,1),x(idx,2),'o');
center = mean(x(idx,:));
plot(center(1),center(2),'k*');
end;
end;
fprintf('\n$$ GMM using VBEM completed, and totally %d clusters found.\n', Nclst);
axis([-10,10,-4,8]);
title('4.Clustering: Variational Bayes EM', 'fontsize', 20);
xlabel('x1');
ylabel('x2');
%% Gibbs sampling for Gaussian Mixture Model
% Latent Variables:
% z: N*K, x所处的类别
% mu:1*K, 第k类分布的均值
% sig:K*D*D,第k类分布的方差
% pz:N*K,z(i)属于K类的分布概率
clear all; rng(1);
load('GMM_data.mat');
[N,D] = size(x);
K = 6; % 增加分类数,自动选择分类数?
Nth = N/K/20; % 阈值threshold,当某一分类样本数少于此值时,抛弃此分类
k0 = 0.0;
dof = 0;
Nsmpl = 60; % 总抽样数
Nbnin = 20; % 前面需要扔掉的抽样数,只取后面的抽样(稳定后的抽样)
z = zeros(N,K); % z(i)中只有一个为1,其它为0
pz = zeros(N,K); % z(i)属于K类的概率,用于最终聚类
pi = ones(1,K)/K; % K类的总概率
px = zeros(N,K); % N(x(i)|mu(k),sigma(k))
pxtmp = zeros(size(px));
mu = zeros(K,D);
sig = zeros(K,D,D);
xbar = zeros(1,D);
Nk = zeros(1,K);
ClstMask = ones(1,K); % Cluster Mask
piSamples = zeros(Nsmpl-Nbnin, K);
muSamples = zeros(Nsmpl-Nbnin, K, D);
sigSamples = zeros(Nsmpl-Nbnin, K, D, D);
k_idx=kmeans(x,K); % 使用Matlab自带的k-means聚类,结果作为GS的初始值
figure(1); subplot(2,3,5); hold on;
for ii=1:K,
idx=(k_idx==ii);
mu(ii,:) = mean(x(idx,:));
sig(ii,:,:)=cov(x(idx,1),x(idx,2));
px(:,ii)=GaussPDF(x,mu(ii,:),squeeze(sig(ii,:,:)));
% 使用Matlab自带的mvnpdf,有时会出现sigma非正定的错误,因此使用自编函数GaussPDF
plot(x(idx,1),x(idx,2),'o');
plot(mu(ii,1),mu(ii,2),'*');
end;
axis([-10,10,-4,8]);
title('5.Clustering: Gibbs Sampling (initial)', 'fontsize', 20);
xlabel('x1');
ylabel('x2');
for s = 1:Nsmpl,
% need to be refreshed: pi, px, mu, sig
pz_k = px.*repmat(pi,N,1);
[~,tmpidx] = max(pz_k,[],2);
z = zeros(N,K);
for ii = 1:K,
idx=(tmpidx==ii);
z(idx,ii) = 1;
Nk(ii) = sum(z(:,ii));
if Nk(ii)<Nth, % 如果某一分类样本数少于阈值Nth,则抛弃
ClstMask(ii) = 0;
Nk(ii) = 0;
px(:,ii) = 0;
break;
end;
% 如下代码借鉴了MLaPP所附gaussMissingFitGibbs函数
xbar = mean(x(idx,:));
muPost = (Nk(ii)*xbar + k0*mu(ii,:)) / (Nk(ii) + k0);
sigPost = squeeze(sig(ii,:,:)) + Nk(ii)*cov(x(idx,:),1) + ...
Nk(ii)*k0/(Nk(ii)+k0) * (xbar - mu(ii,:))*(xbar - mu(ii,:))';
sig(ii,:,:) = invWishartSample(struct('Sigma', sigPost, 'dof', k0 + Nk(ii)));
mu(ii,:) = mvnrnd(muPost, squeeze(sig(ii,:,:))/(k0 + Nk(ii)));
px(:,ii)=GaussPDF(x,mu(ii,:),squeeze(sig(ii,:,:)));
end;
pi = dirichlet_sample(Nk).*ClstMask;
pi = pi/sum(pi);
if s > Nbnin,
muSamples(s - Nbnin,:,:) = mu;
sigSamples(s - Nbnin,:,:,:) = sig;
piSamples(s - Nbnin,:) = pi;
end;
end;
muMean = squeeze(mean(muSamples));
sigMean = squeeze(mean(sigSamples));
piMean = squeeze(mean(piSamples)).*ClstMask;
for ii = 1:K,
if ClstMask(ii)==1,
px(:,ii)=GaussPDF(x,muMean(ii,:),squeeze(sigMean(ii,:,:)));
else
px(:,ii)=0;
end;
end;
pz_k = px.*repmat(piMean,N,1);
[~,tmpidx] = max(pz_k,[],2);
figure(1); subplot(2,3,6); hold on;
Nclst = 0;
for ii = 1:K,
idx=(tmpidx==ii);
if sum(idx)>=Nth,
Nclst = Nclst + 1;
plot(x(idx,1),x(idx,2),'o');
plot(muMean(ii,1),muMean(ii,2),'*');
end;
end;
axis([-10,10,-4,8]);
fprintf('\n$$ GMM using Gibbs sampling completed, and totally %d clusters found.\n\n', Nclst);
title('6.Clustering: Gibbs Sampling (final)', 'fontsize', 20);
xlabel('x1');
ylabel('x2');
函数Dirichlet抽样:
function r = dirichlet_sample(a,n)
% DIRICHLET_SAMPLE Sample from Dirichlet distribution.
%
% DIRICHLET_SAMPLE(a) returns a probability vector sampled from a
% Dirichlet distribution with parameter vector A.
% DIRICHLET_SAMPLE(a,n) returns N samples, collected into a matrix, each
% vector having the same orientation as A.
%
% References:
% [1] L. Devroye, "Non-Uniform Random Variate Generation",
% Springer-Verlag, 1986
% This is essentially a generalization of the method for Beta rv's.
% Theorem 4.1, p.594
if nargin < 2
n = 1;
end
row = (size(a, 1) == 1);
a = a(:);
y = gamrnd(repmat(a, 1, n),1);
% randgamma is faster
%y = randgamma(repmat(a, 1, n));
%r = col_sum(y);
r = sum(y,1);
r(find(r == 0)) = 1;
r = y./repmat(r, size(y, 1), 1);
if row
r = r';
end
end
函数IW抽样:
function S = invWishartSample(model, n)
% S(:, :, 1:n) ~ IW(model.Sigma, model.dof)
% This file is from pmtk3.googlecode.com
if nargin < 2, n = 1; end
Sigma = model.Sigma;
dof = model.dof;
d = size(Sigma, 1);
C = chol(Sigma)';
S = zeros(d, d, n);
for i=1:n
if (dof <= 81+d) && (dof==round(dof))
Z = randn(dof, d);
else
Z = diag(sqrt(2.*randg((dof-(0:d-1))./2))); % randgamma改为randg
Z(utri(d)) = randn(d*(d-1)/2, 1);
end
[Q, R] = qr(Z, 0);
M = C / R;
S(:, :, i) = M*M';
end
end
函数(IW抽样函数需要用到的一个小函数,不知道用途)
function ndx = utri(d)
% Return the indices of the upper triangluar part of a square d-by-d matrix
% Does not include the main diagonal.
% This file is from pmtk3.googlecode.com
ndx = ones(d*(d-1)/2,1);
ndx(1+cumsum(0:d-2)) = d+1:-1:3;
ndx = cumsum(ndx);
end
函数GaussPDF(等效于Matlab自带的mvnpdf函数,之前用mvnpdf有时会出现非正定矩阵问题)
function p = GaussPDF(x, mu, sigma)
[N, D] = size(x);
x_u = x-repmat(mu, N, 1);
p = zeros(N,1);
for ii=1:N,
p(ii) = exp(-0.5*x_u(ii,:)*pinv(sigma)*x_u(ii,:)')/...
sqrt(det(sigma)*(2*pi)^D);
end;
end