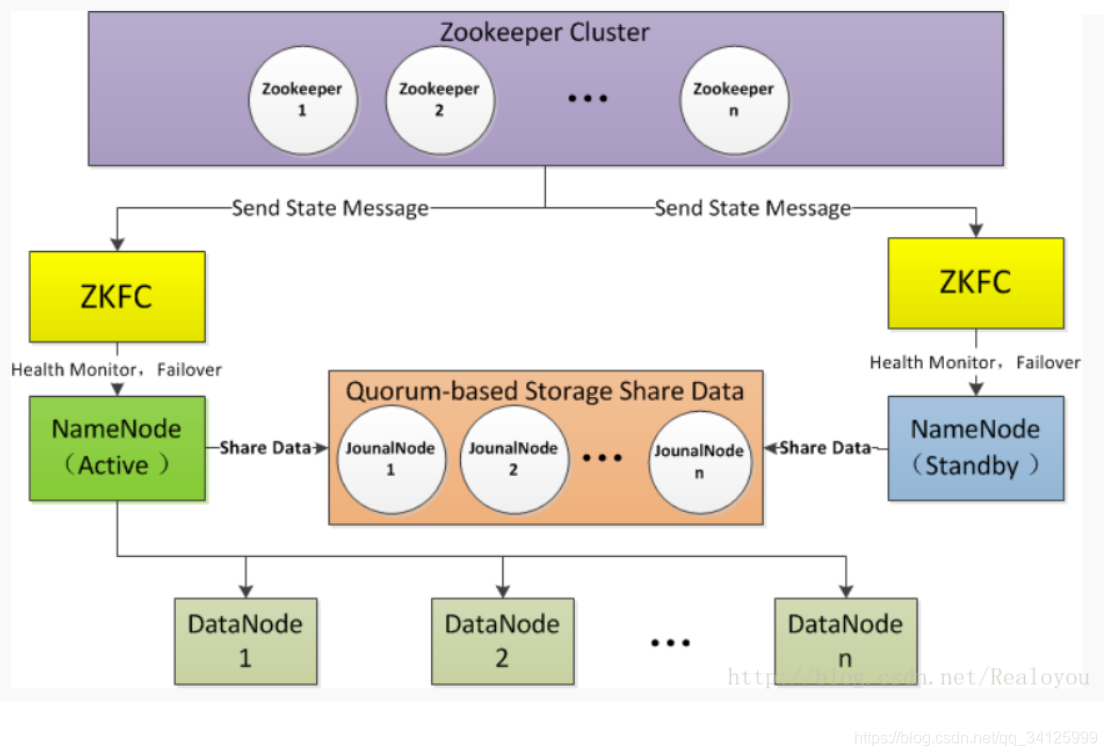
1 Hadoop 高可用概述
1)Active NameNode 和 Standby NameNode:两台 NameNode 形成互备,一台处于 Active 状态,为主 NameNode,另外一台处于 Standby 状态,为备 NameNode,只有主 NameNode 才能对外提供读写服务。
2)主备切换控制器 ZKFailoverController:ZKFailoverController 作为独立的进程运行,对 NameNode 的主备切换进行总体控制。ZKFailoverController 能及时检测到 NameNode 的健康状况,在主 NameNode 故障时借助 Zookeeper 实现自动的主备选举和切换,当然 NameNode 目前也支持不依赖于 Zookeeper 的手动主备切换。
3)Zookeeper 集群:为主备切换控制器提供主备选举支持。
4)JounalNode:用于Active NameNode,Standby NameNode同步数据,本身由一组JounnalNode结点组成,该组结点基数个,支持Paxos协议,保证高可用,是CDH5唯一支持的共享方式(相对于CDH4 促在NFS共享方式)
2 高可用搭建
2.1 环境准备
#node1,node2免登陆其余节点
node1 jdk hadoop zookeeper NameNode zkfc ResourceManager
node2 jdk hadoop NameNode zkfc ResourceManager
node3 jdk hadoop DataNode NodeManager JournalNode
node4 jdk hadoop DataNode NodeManager JournalNode
node5 jdk hadoop DataNode NodeManager JournalNode
2.2 安装单机节点zookeeper(比较easy安装步骤略)
2.3 修改core-site.xml
cd /usr/local/hadoop-2.8.5/etc/hadoop
vim core-site.xml
<configuration>
<!--namenode名称-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://nameservice/</value>
</property>
<!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>node1:2181</value>
</property>
</configuration>
2.4 修改hdfs-site.xml
vim hdfs-site.xml
<configuration>
<!--指定hdfs的nameservice为bi,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>nameservice</value>
</property>
<!-- nameservice下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.nameservice</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.nameservice.nn1</name>
<value>node1:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.nameservice.nn1</name>
<value>node1:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.nameservice.nn2</name>
<value>node2:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.nameservice.nn2</name>
<value>node2:50070</value>
</property>
<!--nameNode的edits元数据在机器本地磁盘的存放位置 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/data/datanode</value>
</property>
<!-- 指定NameNode的共享edits元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node3:8485;node4:8485;node5:8485/nameservice</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/local/data/journaldata</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.nameservice</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
2.5 修改mapred-site.xml
vim mapred-site.xml
<configuration>
<!--提交job时在yarn上计算-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
2.6 修改yarn-site.xml
vim yarn-site.xml
<configuration>
<!-- 开启RM高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定RM的逻辑名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node2</value>
</property>
<!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>node1:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
2.7 修改slaves
#node1
vim slaves
node3
node4
node5
2.8 把当前节点配置文件复制到其它节点上
#node1把配置文件复制到其它节点上
cd /usr/local/hadoop-2.8.5/etc
scp -r ./hadoop node2:/usr/local/hadoop-2.8.5/etc
scp -r ./hadoop node3:/usr/local/hadoop-2.8.5/etc
scp -r ./hadoop node4:/usr/local/hadoop-2.8.5/etc
scp -r ./hadoop node5:/usr/local/hadoop-2.8.5/etc
2.9 启动
1)启动zk

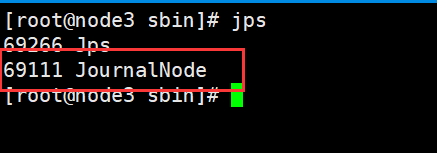
2)启动journalnode
#必须先启动journalnode,node3 node4 node5。
cd /usr/local/hadoop-2.8.5/sbin
./hadoop-daemon.sh start journalnode
#查看
jps
3)格式化namenode
#node1
cd /usr/local/hadoop-2.8.5/bin
./hadoop namenode -format
#为了保持node2和node1数据一致那么把namenode1的格式化数据复制过去
cd /usr/local/data
scp -r namenode/ node2:/usr/local/data/
4)格式化zkfc
#node1
cd /usr/local/hadoop-2.8.5/bin
#格式化
./hdfs zkfc -formatZK


5)启动hdfs集群5)启动hdfs集群
#进入目录
cd /usr/local/hadoop-2.8.5/sbin
#开启hdfs集群
./start-dfs.sh
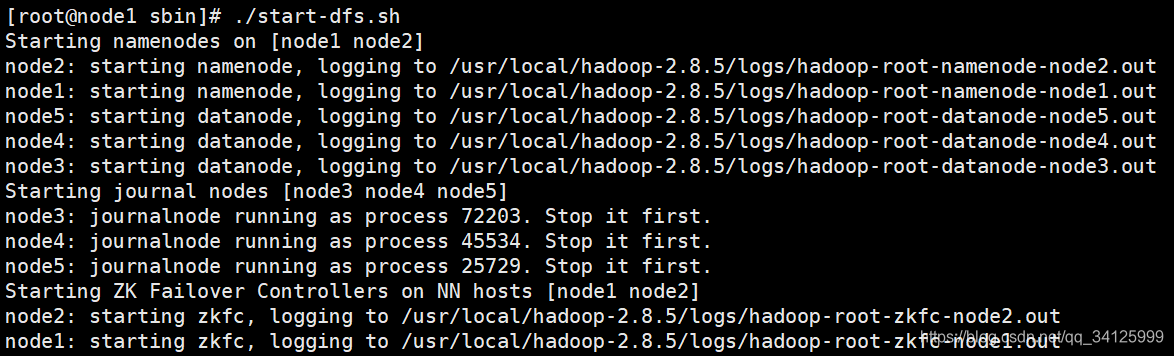
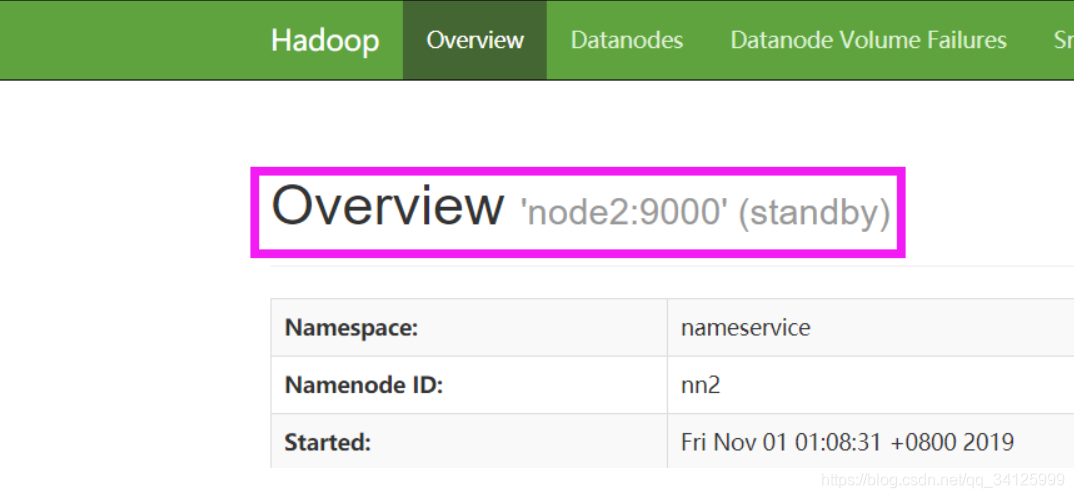
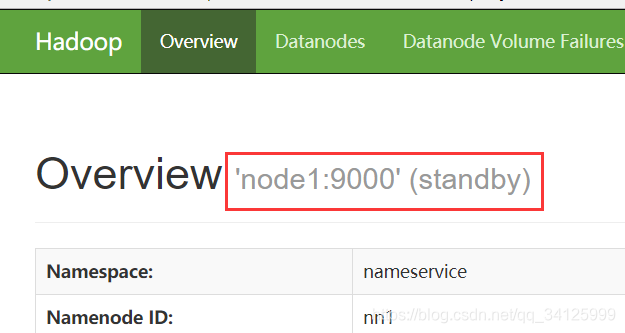
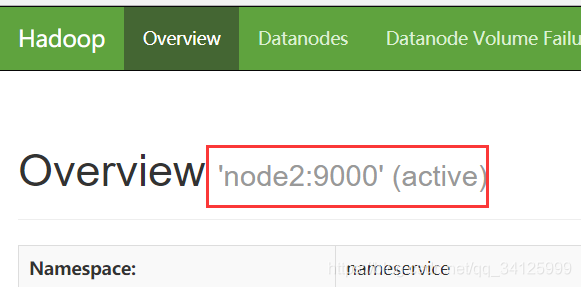
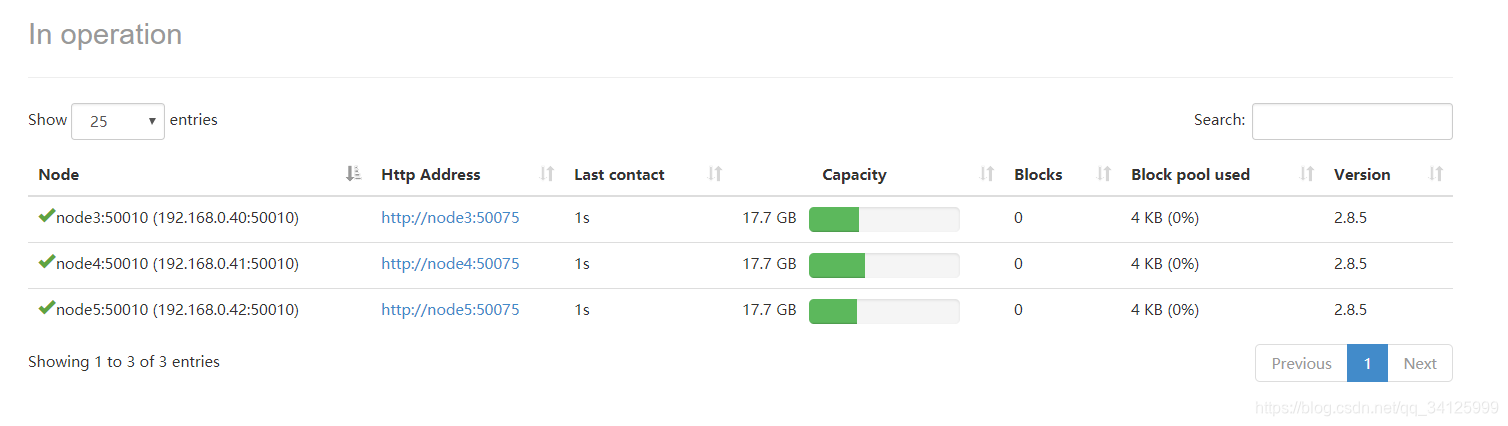
6)查看web界面
http://192.168.0.38:50070
http://192.168.0.39:50070
7)启动yarn
#node1
cd /usr/local/hadoop-2.8.5/sbin
./start-yarn.sh
#node2
cd /usr/local/hadoop-2.8.5/sbin
./yarn-daemon.sh start resourcemanager
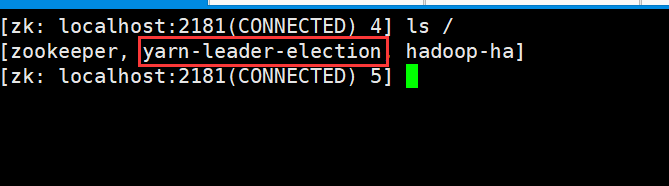
8)关闭acitve机器
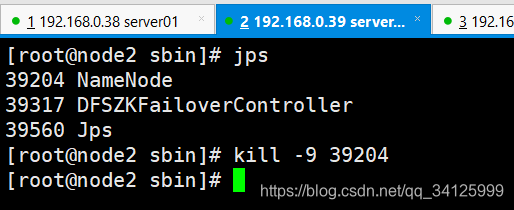
node2 jps 杀进程,node1变成了主节点
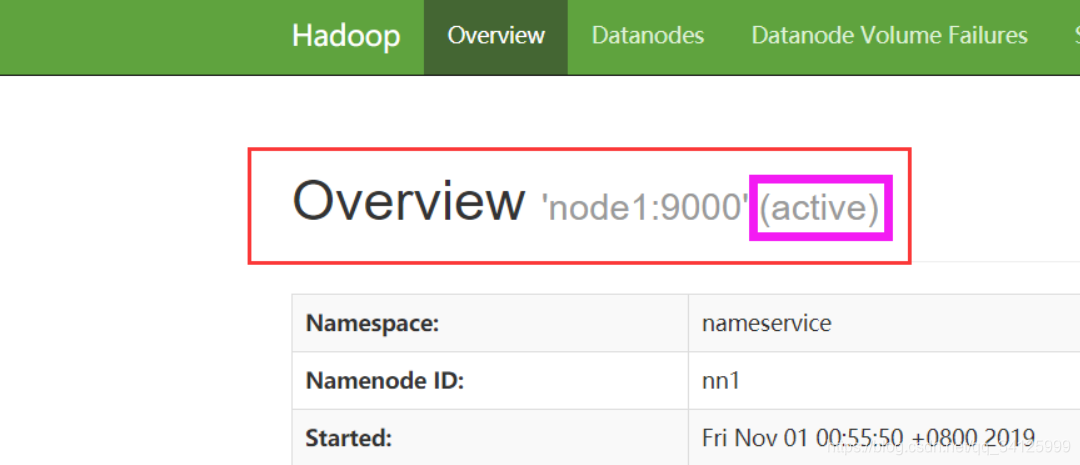
9)恢复node2
#恢复挂掉相关日志
cd /usr/local/hadoop-2.8.5/bin
./hadoop namenode -recover
cd /usr/local/hadoop-2.8.5/sbin
./hadoop-daemon.sh start namenode
#访问URL
http://192.168.0.38:50070/dfshealth.html#tab-overview