问题与数据说明
-
任务
本次赛题主要是通过房产市场、租赁市场、市场需求以及房屋配置来做出合理的房租预测,以应对市场变化对运营商和房产机构带来的影响。命题方向为运用机器学习、人工智能等模型算法,结合模型的创新能力,来实现准确预测的目的。 -
数据
线上比赛要求参赛选手根据给定的数据集,建立模型,预测房屋租金。
数据集中的数据类别包括租赁房源、小区、二手房、配套、新房、土地、人口、客户、真实租金等。
平台提供的数据包括训练集、预测试集(Test A)、正式测试集(Test B),详见数据集说明。
对于小区信息中,关于city、region、plate三者的关系:city>region>plate
土地数据中,土地楼板面积是指在土地上建筑的房屋总面积

赛题链接:城市-房产租金预测
这比赛好像很小众的样子,队伍数不多,这其实也就意味着大佬不多,开源节流。。
数据处理
导入数据
先导入大致需要用到的包,编程环境为Windows,代码为:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import OneHotEncoder, LabelEncoder
import sys
import warnings
if not sys.warnoptions:
warnings.simplefilter("ignore")
from IPython.core.interactiveshell import InteractiveShell
"""
win下显示所有结果与中文
"""
InteractiveShell.ast_node_interactivity = "all"
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
然后导入本次比赛的数据与初步分析:
train = pd.read_csv(r"data\train_data.csv")
test = pd.read_csv(r"data\test_a.csv")
df = pd.concat([train,test],ignore_index=True)
train.head()
y_train = train["月租金"]
train.info()
train.describe()
大概对数据有了一个全面的了解,另外可以把数值型还有类别型进行统一划分:
# 根据特征含义和特征一览,大致可以判断出数值型和类别型特征如下
categorical_feas = ['rentType', 'houseType', 'houseFloor', 'region', 'plate', 'houseToward', 'houseDecoration',
'communityName','city','region','plate','buildYear']
numerical_feas=['ID','area','totalFloor','saleSecHouseNum','subwayStationNum',
'busStationNum','interSchoolNum','schoolNum','privateSchoolNum','hospitalNum',
'drugStoreNum','gymNum','bankNum','shopNum','parkNum','mallNum','superMarketNum',
'totalTradeMoney','totalTradeArea','tradeMeanPrice','tradeSecNum','totalNewTradeMoney',
'totalNewTradeArea','tradeNewMeanPrice','tradeNewNum','remainNewNum','supplyNewNum',
'supplyLandNum','supplyLandArea','tradeLandNum','tradeLandArea','landTotalPrice',
'landMeanPrice','totalWorkers','newWorkers','residentPopulation','pv','uv','lookNum']
当然,如果再往下划分,还能将数据分为离散型特征、连续型特征、混合型特征、缺失、异常型特征,这些我有在之前的一篇博文提到过,这里就不解释了,时间不充裕。

数据分析
缺失值分析
missing_data = train.isnull().sum().sort_values(ascending=False)
missing_rate = (missing_data / len(train))*100
train_missing = pd.DataFrame({"缺失率":missing_rate})
# train_missing = missing_rate.drop(missing_rate[missing_rate==0].index).sort_values(ascending=False)
# train_missing = pd.DataFrame({"缺失率":train_missing})
train_missing
"""
缺失率
uv 0.043436
pv 0.043436
"""
发现高维数据下只有两列的数据有缺失,感觉有点吃惊,然后感觉可以统计0的数量为缺失值,但想了想还是要从长计议。那便可以先对这两列做处理,因为比较少量,用中位数来代替:
df["pv"] = df["pv"].fillna(value=int(df["pv"].median()))
df["uv"] = df["uv"].fillna(value=int(df["uv"].median()))
单调特征列
不太懂这个专有名词是啥意思,看了下解析,它很大可能指时间,代码为:
def incresing(vals): # 后一个值大于前一个值,计数器加1
cnt = 0
len_ = len(vals)
for i in range(len_-1):
if vals[i+1] > vals[i]:
cnt += 1
return cnt
fea_cols = [col for col in train.columns]
for col in fea_cols:
cnt = incresing(train[col].values)
if cnt / train.shape[0] >= 0.55: # 经统计大于总数的0.55视为单调特征值
print('单调特征:',col)
print('单调特征值个数:', cnt)
print('单调特征值比例:', cnt / data_train.shape[0])
嗯,学到了,但不知道有啥用。结果如下:
单调特征: tradeTime # 确实只有时间是单调特征值
单调特征值个数: 24085
单调特征值比例: 0.5812017374517374
label处理
还有特征nunique分布,统计特征值出现频次大于100的特征。前者还是没听过啥意思,原谅我知识浅薄。。后者感觉没意义,然后我们看标签的分布情况,因为不是二分类问题,如果是二分类,可能就一句:
# 二分类
# sns.countplot(x='tradeMoney',data=train)
# Labe 分布
fig,axes = plt.subplots(2,3,figsize=(20,5))
fig.set_size_inches(20,12)
sns.distplot(train['tradeMoney'],ax=axes[0][0])
sns.distplot(train[(train['tradeMoney']<=20000)]['tradeMoney'],ax=axes[0][1])
sns.distplot(train[(train['tradeMoney']>20000)&(train['tradeMoney']<=50000)]['tradeMoney'],ax=axes[0][2])
sns.distplot(train[(train['tradeMoney']>50000)&(train['tradeMoney']<=100000)]['tradeMoney'],ax=axes[1][0])
sns.distplot(train[(train['tradeMoney']>100000)]['tradeMoney'],ax=axes[1][1])
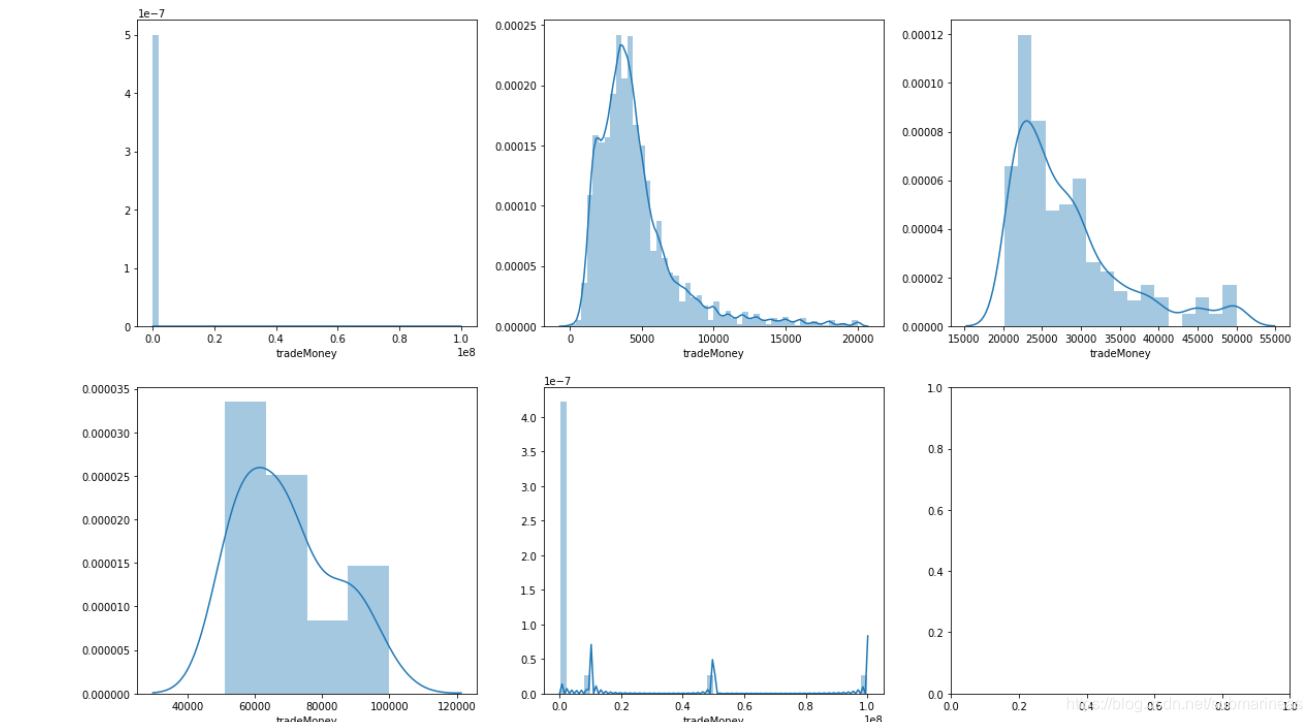
看起来还行,虽然有点偏态分布,我们继续对其进行分析:
print('峰度(Kurtosis): ', train['tradeMoney'].kurt())
print('偏度(Skewness): ', train['tradeMoney'].skew())
"""
峰度(Kurtosis): 27724.03357394935
偏度(Skewness): 162.01436633929143
"""
发现果然有偏度,那么对其取np.log就ok了。
数据总表
看了下鱼佬在知乎开源的代码,学到了可以将上述EDA统一为:
stats = []
for col in train.columns:
stats.append((col, train[col].nunique(), train[col].isnull().sum() * 100 / train.shape[0], train[col].value_counts(normalize=True, dropna=False).values[0] * 100, train[col].dtype))
stats_df = pd.DataFrame(stats, columns=['Feature', 'Unique_values', 'Percentage of missing values', 'Percentage of values in the biggest category', 'type'])
stats_df.sort_values('Percentage of missing values', ascending=False)[:10]
部分结果为:
Feature Unique_values Percentage of missing values Percentage of values in the biggest category type
47 uv 649 0.043436 0.926641 float64
46 pv 709 0.043436 0.926641 float64
0 ID 41440 0.000000 0.002413 int64
37 supplyLandNum 4 0.000000 87.731660 int64
28 totalTradeArea 705 0.000000 1.020753 float64
数据清洗
编码问题
关于楼层的中低高,很容易想到是取0.33一份,代码为:
def house_floor(x):
if x == '低':
r = 0
elif x == '中':
r = 0.3333
else:
r = 0.6666
return r
df['houseFloor_ratio'] = df['houseFloor'].apply(lambda x: house_floor(x))
df['所在楼层'] = df['totalFloor'] * df['houseFloor_ratio']
对出租方式来讲,好像不仅仅是三种,还有一种"–",有5个,可以将其作为异常值处理为:
df['rentType'] = df['rentType'].replace("--","未知方式")
df['rentType'].value_counts()
然后我们就可以看到rentType就只有三种类型了,而其实关于未知方式,可以用租房的面积大小,我们根据它的平均值来将其划分为整租还是合租,代码为:
rentType_group_area = {}
for index, group in df.groupby(by="rentType"):
rentType_group_area[index] = group["area"].mean()
def replace_UnknownType(data):
if data["rentType"] == "未知方式":
if data["area"] >= rentType_group_area["整租"]:
return "整租"
else:
return "合租"
else:
return data["rentType"]
df['rentType'] = df.apply(lambda data: replace_UnknownType(data), axis=1)
print(df['rentType'].value_counts())
"""
合租 24728
整租 19181
Name: rentType, dtype: int64
"""
另外房租类型也是一个很需要更改的地方,我们先对其和楼层的处理一样:
house_type_nums = df['houseType'].value_counts().to_dict()
def check_type(x):
if house_type_nums[x]>=1000:
return "high_num"
elif house_type_nums[x]<1000 and house_type_nums[x]>=100:
return "median_num"
else:
return "low_num"
df['houseType_num']=df['houseType'].apply(lambda x:check_type(x))
df['houseType_num'].value_counts()
"""
high_num 39232
median_num 3780
low_num 897
Name: houseType, dtype: int64
"""
或者将houseType进行求和,这里想了一下是否加权,但不管怎样,厕所或者大厅也是室,前两个月看房还是被中介坑得不要不要的,那么一切从简吧,可以用正则或者其它办法将其弄出来,代码为:
df['houseType_num2'] = df['houseType'].apply(lambda data: sum(map(int,filter(str.isdigit, data))))
df["houseType_num2"]
结果为:
0 4
1 7
2 7
3 3
4 8
..
43904 4
43905 2
43906 3
43907 3
43908 4
Name: houseType_num, Length: 43909, dtype: int64
还有关于南北朝向,可以用OneHotEncoder编码,同时我看到一个房价预测的大佬这样做转换,我将其用成本文的数据格式为:
df['东'] = df.houseToward.map(lambda x : 1 if '东' in x else 0)
df['西'] = df.houseToward.map(lambda x : 1 if '西' in x else 0)
df['南'] = df.houseToward.map(lambda x : 1 if '南' in x else 0)
df['北'] = df.houseToward.map(lambda x : 1 if '北' in x else 0)
df['东南'] = df.houseToward.map(lambda x : 1 if '东南' in x else 0)
df['西南'] = df.houseToward.map(lambda x : 1 if '西南' in x else 0)
df['东北'] = df.houseToward.map(lambda x : 1 if '东北' in x else 0)
df['西北'] = df.houseToward.map(lambda x : 1 if '西北' in x else 0)
# print(df[])
# df.drop('houseToward',axis=1,inplace = True)
其余详细操作见参考链接,结果为:
houseType_num 东 西 南 北 东南 西南 东北 西北
43904 0 0 0 1 0 0 0 0 0
43905 0 0 0 1 0 0 0 0 0
43906 0 0 0 1 0 0 0 0 0
43907 0 0 0 1 0 0 0 0 0
43908 0 0 0 1 0 0 0 0 0
异常值处理
uv、PV这种很明显的缺失值比较好处理,比较难定义的是一些中文字符比如说前面的未知方式等,这种可以根据常识来判断是否是整租或合租。然后就是训练集中的预测值tradeMoney来进行异常值筛选,运用孤立森林:
Comparing anomaly detection algorithms for outlier detection on toy datasets
iForest (Isolation Forest)孤立森林 异常检测 入门篇
# clean data
from sklearn.ensemble import IsolationForest
def IF_drop(train):
IForest = IsolationForest(contamination=0.01) # 设置异常值的比例,contamination可以说是阈值,在0-0.5以内,默认值从0.20更改为'auto'0.22
IForest.fit(train["tradeMoney"].values.reshape(-1,1)) # 初始化一个拟合估算器。
y_pred = IForest.predict(train["tradeMoney"].values.reshape(-1,1)) # 执行异常值检测
drop_index = train.loc[y_pred==-1].index # 取异常值的索引值
# print(drop_index)
train.drop(drop_index,inplace=True)
return train
data_train = IF_drop(train)
data_train["tradeMoney"].describe()
"""
count 41037.000000
mean 4576.514146
std 2966.076086
min 0.000000
25% 2800.000000
50% 3900.000000
75% 5360.000000
max 22000.000000
Name: tradeMoney, dtype: float64
"""
我们还可以根据主观判断来清洗异常值:
def dropData(train):
# 丢弃部分异常值
train = train[train.area <= 200]
train = train[(train.tradeMoney <=16000) & (train.tradeMoney >=700)]
train.drop(train[(train['totalFloor'] == 0)].index, inplace=True)
return train
#数据集异常值处理
data_train = dropData(data_train)
深度清洗
没有看懂,可能是业务逻辑太深了,另外感觉如果非图,会更加长,所以在这里以50%的比例贴出来:

建模过程
特征工程
这部分看的参考代码,没有baseline,然后大部分特征工程方法实在太长,很多我也没看懂,所以只能是贴一部分,后期如果理解到位了再重新写:
def newfeature(data):
# 将houseType转为'Room','Hall','Bath'
def Room(x):
Room = int(x.split('室')[0])
return Room
def Hall(x):
Hall = int(x.split("室")[1].split("厅")[0])
return Hall
def Bath(x):
Bath = int(x.split("室")[1].split("厅")[1].split("卫")[0])
return Bath
data['Room'] = data['houseType'].apply(lambda x: Room(x))
data['Hall'] = data['houseType'].apply(lambda x: Hall(x))
data['Bath'] = data['houseType'].apply(lambda x: Bath(x))
data['Room_Bath'] = (data['Bath']+1) / (data['Room']+1)
# 填充租房类型
data.loc[(data['rentType'] == '未知方式') & (data['Room'] <= 1), 'rentType'] = '整租'
# print(data.loc[(data['rentType']=='未知方式')&(data['Room_Bath']>1),'rentType'])
data.loc[(data['rentType'] == '未知方式') & (data['Room_Bath'] > 1), 'rentType'] = '合租'
data.loc[(data['rentType'] == '未知方式') & (data['Room'] > 1) & (data['area'] < 50), 'rentType'] = '合租'
data.loc[(data['rentType'] == '未知方式') & (data['area'] / data['Room'] < 20), 'rentType'] = '合租'
# data.loc[(data['rentType']=='未知方式')&(data['area']>60),'rentType']='合租'
data.loc[(data['rentType'] == '未知方式') & (data['area'] <= 50) & (data['Room'] == 2), 'rentType'] = '合租'
data.loc[(data['rentType'] == '未知方式') & (data['area'] > 60) & (data['Room'] == 2), 'rentType'] = '整租'
data.loc[(data['rentType'] == '未知方式') & (data['area'] <= 60) & (data['Room'] == 3), 'rentType'] = '合租'
data.loc[(data['rentType'] == '未知方式') & (data['area'] > 60) & (data['Room'] == 3), 'rentType'] = '整租'
data.loc[(data['rentType'] == '未知方式') & (data['area'] >= 100) & (data['Room'] > 3), 'rentType'] = '整租'
return new_train, new_test
train, test = gourpby(train, test)
计算统计特征:
#计算统计特征
def featureCount(train,test):
train['data_type'] = 0
test['data_type'] = 1
data = pd.concat([train, test], axis=0, join='outer')
def feature_count(data, features=[]):
new_feature = 'count'
for i in features:
new_feature += '_' + i
temp = data.groupby(features).size().reset_index().rename(columns={0: new_feature})
data = data.merge(temp, 'left', on=features)
return data
data = feature_count(data, ['communityName'])
data = feature_count(data, ['buildYear'])
data = feature_count(data, ['totalFloor'])
data = feature_count(data, ['communityName', 'totalFloor'])
data = feature_count(data, ['communityName', 'newWorkers'])
data = feature_count(data, ['communityName', 'totalTradeMoney'])
new_train = data[data['data_type'] == 0]
new_test = data[data['data_type'] == 1]
new_train.drop('data_type', axis=1, inplace=True)
new_test.drop(['data_type'], axis=1, inplace=True)
return new_train, new_test
train, test = featureCount(train, test)
log平滑:
# 过大量级值取log平滑(针对线性模型有效)
big_num_cols = ['totalTradeMoney','totalTradeArea','tradeMeanPrice','totalNewTradeMoney', 'totalNewTradeArea',
'tradeNewMeanPrice','remainNewNum', 'supplyNewNum', 'supplyLandArea',
'tradeLandArea','landTotalPrice','landMeanPrice','totalWorkers','newWorkers',
'residentPopulation','pv','uv']
for col in big_num_cols:
train[col] = train[col].map(lambda x: np.log1p(x))
test[col] = test[col].map(lambda x: np.log1p(x))
然后还有一些很长一大段的就不介绍了,之后我们就可以用相关系数法、Wrapper、Embedded中的Lasso(l1)和Ridge(l2)和mean decrease impurity随机森林来做选择,结果为:
# Lasso回归
from sklearn.linear_model import Lasso
lasso=Lasso(alpha=0.1)
lasso.fit(np.mat(train),target_train)
#预测测试集和训练集结果
y_pred_train=lasso.predict(train)
y_pred_test=lasso.predict(test)
#对比结果
from sklearn.metrics import r2_score
score_train=r2_score(y_pred_train,target_train)
print("训练集结果:",score_train)
score_test=r2_score(y_pred_test, target_test)
print("测试集结果:",score_test)
"""
训练集结果: 0.7360747254713682
测试集结果: 0.8274062824814048
"""
"""
Wrapper:
(40134, 173)
(40134, 150)
(2469, 150)
训练集结果: 0.7239099316450097
测试集结果: 0.8102638445780519
"""
Embedded中的Lasso(l1)和Ridge(l2)为:
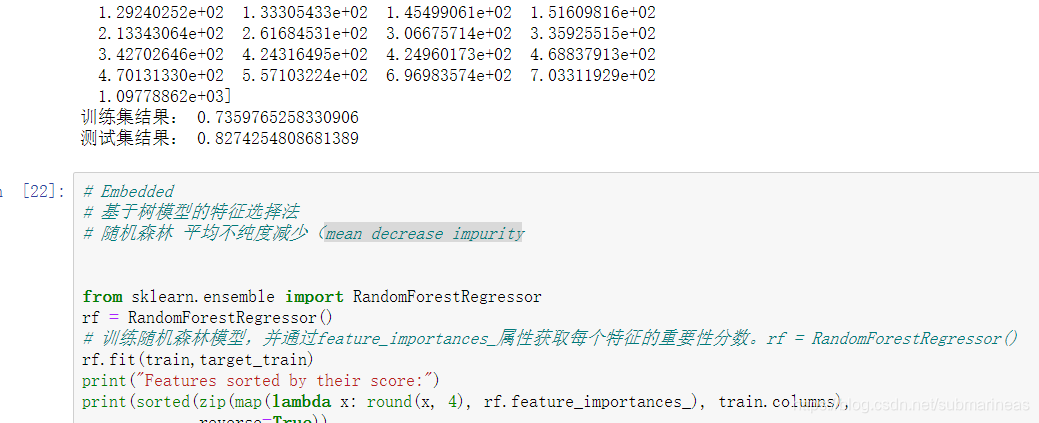
baseline
folds = KFold(n_splits=5, shuffle=True, random_state=2333)
oof_lgb = np.zeros(len(train))
predictions_lgb = np.zeros(len(test))
feature_importance_df = pd.DataFrame()
#target=new_target.copy()
for fold_, (trn_idx, val_idx) in enumerate(folds.split(train.values, target.values)):
print("fold {}".format(fold_))
tag_name = ['communityName','plate','region']
train['tradeMoney']=target
train_csv = train.iloc[trn_idx]
val_csv = train.iloc[val_idx]
for tag in tag_name:
for op in ['mean','std']:
col_name =tag+'_'+op
tmp = train_csv.groupby(tag)['tradeMoney'].agg(op)
train_csv[col_name] = train_csv['communityName'].map(tmp)
val_csv[col_name] = val_csv['communityName'].map(tmp)
test[col_name] = test['communityName'].map(tmp)
train_csv=train_csv.drop(['tradeMoney'],axis=1) #利用drop方法将含有特定数值的列删除
val_csv=val_csv.drop(['tradeMoney'],axis=1) #利用drop方法将含有特定数值的列删除
trn_data = lgb.Dataset(train_csv, label=target.iloc[trn_idx], categorical_feature=categorical_feats)
val_data = lgb.Dataset(val_csv, label=target.iloc[val_idx], categorical_feature=categorical_feats)
num_round = 10000
clf = lgb.train(params, trn_data, num_round, valid_sets = [trn_data, val_data], verbose_eval=500, early_stopping_rounds = 200)
oof_lgb[val_idx] = clf.predict(val_csv, num_iteration=clf.best_iteration)
fold_importance_df = pd.DataFrame()
fold_importance_df["feature"] = train_csv.columns.values
fold_importance_df["importance"] = clf.feature_importance()
fold_importance_df["fold"] = fold_ + 1
feature_importance_df = pd.concat([feature_importance_df, fold_importance_df], axis=0)
predictions_lgb += clf.predict(test, num_iteration=clf.best_iteration) / folds.n_splits
print("CV Score: {:<8.5f}".format(r2_score(target, oof_lgb)))
结果为:
fold 0
Training until validation scores don't improve for 200 rounds
[500] training's rmse: 593.978 valid_1's rmse: 993.509
[1000] training's rmse: 535.469 valid_1's rmse: 986.922
Early stopping, best iteration is:
[862] training's rmse: 546.406 valid_1's rmse: 985.71
fold 1
Training until validation scores don't improve for 200 rounds
[500] training's rmse: 594.917 valid_1's rmse: 969.696
[1000] training's rmse: 535.662 valid_1's rmse: 957.752
Early stopping, best iteration is:
[899] training's rmse: 543.551 valid_1's rmse: 957.422
fold 2
Training until validation scores don't improve for 200 rounds
[500] training's rmse: 597.627 valid_1's rmse: 974.832
[1000] training's rmse: 539.764 valid_1's rmse: 959.752
Early stopping, best iteration is:
[1203] training's rmse: 526.1 valid_1's rmse: 958.835
fold 3
Training until validation scores don't improve for 200 rounds
[500] training's rmse: 601.53 valid_1's rmse: 989.852
[1000] training's rmse: 543.353 valid_1's rmse: 977.509
Early stopping, best iteration is:
[871] training's rmse: 553.599 valid_1's rmse: 976.778
fold 4
Training until validation scores don't improve for 200 rounds
[500] training's rmse: 593.636 valid_1's rmse: 1036.11
[1000] training's rmse: 535.398 valid_1's rmse: 1026.38
Early stopping, best iteration is:
[991] training's rmse: 536.132 valid_1's rmse: 1026.25
CV Score: 0.84548
然后我们还可以看lgb的特征贡献度:
cols = (feature_importance_df[["feature", "importance"]]
.groupby("feature")
.mean()
.sort_values(by="importance", ascending=False)[:1000].index)
best_features = feature_importance_df.loc[feature_importance_df.feature.isin(cols)]
plt.figure(figsize=(14,40))
sns.barplot(x="importance",
y="feature",
data=best_features.sort_values(by="importance",
ascending=False))
plt.title('LightGBM Features (avg over folds)')
plt.tight_layout()
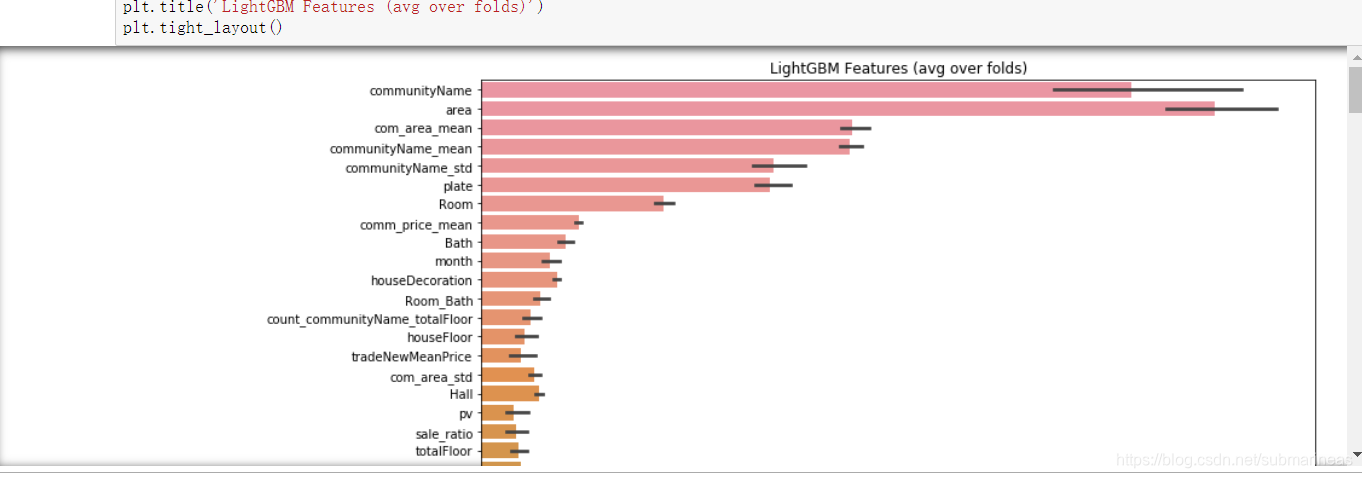
图片太长了,稍微截个图。
总结
这一篇博文比我之前任何一篇的时间周期都要长,因为是任务式的,可能有些生疏,但基本能看得过去。然后关于本次赛题,我感觉总结的东西也比较少。。。确实花的时间并不是很多,中途有各种各样的事情导致会停下做完主要的事情,所以这里就大致写写本篇的心得还有体会吧。
关于房价租金预测,寻常对异常值和缺失值的处理就不用说了,都是常规操作,但关于孤立森林我却是第一次听说,这里学习到了,以后异常值会考虑对目标数据做一些相关变化,然后就是特征工程的聚类和计算统计特征,我觉得算是将大样本缩小了,虽然可能对模型预测的准确率有所降低,但速度却大大提升,这个目前感觉利大于弊吧。最后,关于模型选型也可以看出来,如果我按原本的去训练的话,最终的score其实是0.89,但现在却是0.84,所以小了一些。嗯,目前先总结到这里,之后再说。