Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
目前的问题:
深度神经网络采用空间金字塔池模块或编码解码器结构进行语义分割。
空间金字塔池模块:可以对多尺度的上下文信息进行编码,通过过滤器或多倍速率和多个感受野的汇聚操作来探测输入的特征。
编码解码器:可以通过逐步恢复空间信息来捕捉更清晰的对象边界。
简述:
本文提出的模型DeepLabv3+扩展了DeepLabv3:
1.本文提出了一种新颖的编码器-解码器结构,它采用DeepLabv3作为一个强大的编码器模块和一个简单而有效的解码器模块。
2.DeepLabv3+中,可以通过卷积来任意控制提取编码器特征的分辨率,从而在精度和运行时间之间进行权衡,这在现有的编码器-解码器模型中是不可能的。
3.本文将Xception模型应用于分割任务中,并将深度可分的卷积应用于ASPP模块和解码器模块中,得到了一个更快、更强的编码器-解码器网络
方法:
1.具有洞卷积的编码器-解码器
1.1 洞卷积
见DeepLab-v2
1.2 深度可分离卷积
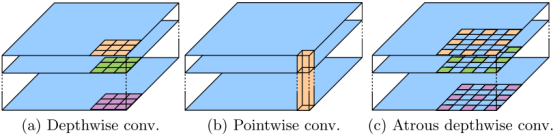
深度可分离卷积,将标准卷积分解为深度卷积(Depthwise conv)和点卷积(Pointwise conv),大大降低了计算复杂度,减少计算量。深度卷积是对每个输入通道独立地执行空间卷积,而点卷积是结合了深度卷积的输出,见下图。在本文中,采用了洞卷积的深度可分离卷积,在使性能没有太大的改变下,大大减少了计算复杂度,加快了运算速率。
1.3 DeepLabv3作为编码器
1.4目标解码器

可以看到,本文提出的DeepLabv3+框架通过采用编码器-解码器结构扩展了DeepLabv3。编码器模块通过在多个尺度应用洞卷积对多尺度上下文信息进行编码,而简单的解码器模块可以得到目标边界细化分割结果。既保证了分割的效果和边缘的完整,同时减少了计算复杂度。
2.修改后的Xception
当前Xception被提出并不断优化,本文在优化后的Xception的基础上在进行修改:
(1)对Xception的层数进行进一步加深,(2)所有max pooling都被depthwise separable convolution代替,(3)每3×3个深度c后增加额外的批量归一化和ReLU激活

实验:
以RES-101为Backbone,PASCAL VOC 2012 val 为数据集,mIOU为评价标准:
改变编码器底层提取特征的通道数进行试验:

改变解码器的结构进行试验:

train OS:训练期间使用的output stride。eval OS:计算期间使用的output stride。Decoder:采用所提出的解码器结构。MS:评估过程中的多尺度输入。Flip:添加左右翻转的输入。

ImageNet-1K验证集的单模型错误率:

试验结构(最后一行为失败结构):

