DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
本网络主要用于图像语义分割使用
问题:
DCNN的缺陷:本文特别考虑了DCNNs在语义图像分割中的三个应用挑战:
(1)降低特征分辨率;
(2)多尺度对象的存在;
(3)由于DCNN的不变性而降低定位精度。
本文将讨论这些挑战以及我们在DeepLab系统中克服这些挑战的方法。
相关工作:
1,提出并强调洞卷积(atrous convolution)的作用与实际应用操作,Atrous convolution可以精确地控制在深度卷积神经网络中计算特征响应的分辨率,它还允许在不增加参数数量或计算量的情况下,有效地扩大过滤器的视野,以结合更多的上下文信息。
2,本文提出了一种基于多尺度稳健分割的空间金字塔汇聚算法。ASPP使用多个采样率的过滤器和有效的视场来探测传入的卷积特征层,从而在多个尺度上捕获对象和图像上下文
3,本文结合DCNNs和概率图形模型的方法改进了对象边界的定位。DCNNs中常用的max-pooling和down-sampling的组合实现了不变性,但会影响定位精度。我们通过将最终DCNN层的响应与完全连接的条件随机场(CRF)相结合来克服这个问题,本文通过定性和定量地展示了该方法,以提高定位性能。

上图展示了deeplab框架的大致过程,backbone采用如VGG-16或ResNet-101,后采用洞卷积的方式下采用(从32x下降8x)。后用双线性插值阶段将特征映射扩展到原始图像分辨率,然后使用一个完全连接的CRF来细化分割结果并更好地捕获对象边界。
模型:
1.Atrous Convolution for Dense Feature Extraction and Field-of-View Enlargement(一种用于稠密特征提取和感受野放大的洞卷积)

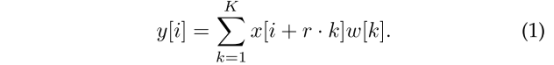
其中,r为步幅,其他同不同卷积步骤。由于洞卷积可以扩大感受野,所以较普通卷积相比可以提取到更为稠密的特征。下面两幅图的顶行为普通卷积,底行为洞卷积。


- Multiscale Image Representations using Atrous Spatial Pyramid Pooling(利用空间金字塔池化的多尺度图像表示)
下图中的ASPP网络结构,空间金字塔池化(ASPP)为了对中心像素(橙色)进行分类,ASPP利用多尺度特征,使用多个不同r的并行过滤器,其中不同的感受野以不同的颜色显示。

3.Structured Prediction with Fully-Connected Conditional Random Fields for Accurate Boundary Recovery(利用全连通条件随机场CRF进行结构预测,实现精确的边界恢复)
目前,增加方差和顶级节点的大接受域野只能产生平滑的响应,对边缘有损。并且,其score map是预测物体的存在和大致位置,但不能真正勾画出它们的边界。其中CRF的能量函数为:
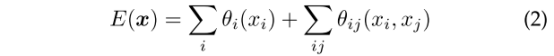
其中,
x为像素的标签赋值,P(xi)为DCNN计算的第i像素处的标签分配概率。
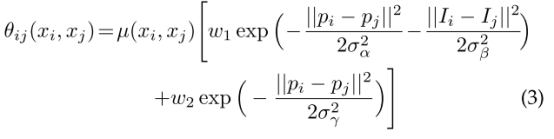
第一部分的目的是使得具有相似颜色和位置的像素具有相似的标签,第二个部分的目的是在强制平滑时只考虑空间邻近性。
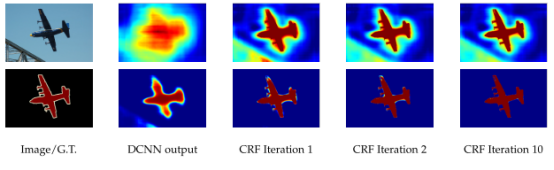
下图可以看出,随着全连接CRF的迭代次数增加,语义分割后的图像边缘有了很明显的改进。
实验:
1.PASCAL VOC 2012数据集(20个前景和1个背景类,像素级标签,训练集1464,验证集1449,测试集1456,扩充后的数据集训练集为10582张图片):
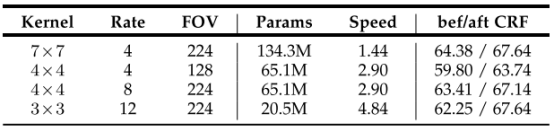
上表改变了kernel size 、r、以及是否加入CRF,以m IOU为评价标准,进行测试。
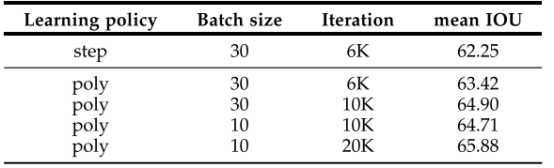
下表改变单步(step)和多步(poly)学习策略,batch size以及迭代次数,以m IOU为评价标准,进行测试。
其中,单步(step)学习为学习率为固定值,多步(poly)学习为学习率遵守下式,其中power=0.9:
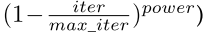
下图比较了加入洞卷积的普通网络(DeepLab-LargeFOV)和空间金字塔池化网络(DeepLab-ASPP)进行比较:


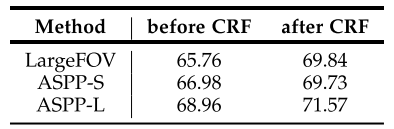

其中,ASPP-S为4个分支的r分别为2,4,8,12,ASPP-L为4个分支的r分别为6,12,18,24。MSC:采用多尺度输入与最大融合。COCO:模型在MS-COCO上预训练。Aug:通过随机调整输入来增强数据。
2.PASCAL-Context(59前景和一个背景类别,训练集和验证集包含4998和5105张图像)


3.PASCAL-Person-Part(PASCAL VOC 2010 额外的人物数据集,主要关注人的部分,它包含了更多的训练数据和大的对象尺度和人体姿态的变化。具体来说,数据集包含每个人的详细部分注释,例如眼睛、鼻子,我们将注释合并为头部、躯干、上肢/下肢和上肢/下肢,得到6个人物部分类和一个背景类。我们只使用那些包含人的图像进行训练(1716)和验证(1817))

4.Cityscapes(包涵50个不同城市收集的5000个图像的高质量像素级注释。使用19个语义标签(属于7大类别:地面、构造、对象、自然、天空、人、车辆)进行评估(不考虑空标签进行评估)。训练集、验证集和测试集分别包含2975,500和1525张图像)


