在B站上看到教程里面说值迭代和策略迭代是Truncated policy iteration的两个特殊情况,这里我想说下我的理解。
首先是概念:
-
action value,是state value v(s)、状态s、动作a的函数,表示了从state s出发,采取动作a可以获得多少return。action value的表现形式:

- 第一项表示了在状态s,采取动作a以后获得的reward的期望,这个是s和a的函数,和策略无关
- gamma是discounted rate是一个常数
- v(s’) 表示的是状态s’ 的state value
-
state value: v(s)指的是从状态s出发可以获得的return,可以使用action value和策略pi表示。
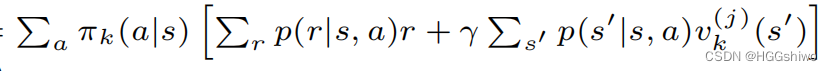
总结就是:
- action value只需要前一个状态的state value就可以算出来
- state value可以用action value和策略pi 算出来。

对于值迭代:
- 根据v(s)计算出了所有的action 对应的action value q(s)
- 根据q(s’)更新了一个v(s)
- 根据q(s’)选择了pi,直接选择q(s’)最大的那个action
- 继续1
下面是书上的算法:

可以看出书上省略了更新pi的步骤,而Loop中关键的一步:
其实可以看成两步:
- 先根据v算出了action value q, 就是r+gammaV(s’)
- 使用q更新了v,而这正是上面图中的1,2两步
下面是策略迭代:
- 第一步分为2小步
- 根据v计算出一个q
- 根据q和pi更新了v
- 返回1.1,直到v不变
- 根据q更新pi
- 返回1
看下书上的:

第二步的loop里面就是上面的第一步里面不断迭代更新v,第3步就是根据q更新pi,和上面的第二步相同。
总结:
- 值迭代的过程是: v->q->pi->v->q->pi->v->q->…,
- 策略迭代的过程是:v->q->v->q->v->q->pi->v->q->v->q->pi->…
也就是说:
- 值迭代是一次v->q就更新了策略pi,
- 策略迭代是v->q->v->q这样迭代了若干次,直到v收敛才更新pi,理论上需要迭代无数次,
- Truncated policy iteration指的是不需要更新到v收敛,v->q迭代若干次就更新pi。