TensorFlow代码实现:https://github.com/TheAbhiKumar/tensorflow-value-iteration-networks
原创文章,转载请标明出处:http://blog.csdn.net/ikerpeng/article/details/53784021
知乎同步发布:https://zhuanlan.zhihu.com/p/24478944
交流请加群:580043385
今天这个歪楼以下,插播今年NIPS的最佳论文,也是强化学习的一篇论文,叫做 Value iteration Network.
这一篇强化学习的论文是为了解决 强化学习当中泛化能力差的问题,为了解决这个问题,引入了一个 Learn to plan 的模块。

本文的最大创新:在一般性的策略(Policy representation)表示当中加入了一个 规划模块(Planing module)。作者认为加入这个模块的motivation是很自然的,因为决解一个空间的问题的时候都不是单纯的解决这个问题,而是要在这个空间当中去计划。
总结VIN的创新点,我觉得主要是以下的几个点:
1. 将奖励函数和转移函数也参数化,并且能够求导;
2. 引入了一个空间辅助策略的求解,使得policy更具有泛化能力;
3. 在策略的求解当中引入attention机制;
4. 将VI module的设计等价为一个CNN网络,且能够使用BP算法更新网络。
作者定义了一个MDP 空间M,这个空间由一系列的tuple构成,也就是一些列的 状态,动作,转移,奖励数据元组,M决定着我们的最终的策略。那么通过这个 MDP空间的数据M得到的一个策略 policy并不是一个具有很好的泛化能力的策略,因为策略局限在这个数据空间当中。因此,作者假设得到了未知的数据空间M‘,在这个空间当中存在最优的plan包含了M空间当中的最优化策略的重要信息。 其实这样的假设就好像是M仅仅是这个MDP空间当中的一部分的采样轨迹,加上M'像是对于这一个空间当中的轨迹的一个补充。
做了这样一个假设之后,作者用了一个比较巧妙的做法: 并不是去求解这一个空间,而是通过让在 M空间当中的policy能够同样解决M'空间当中的问题,以至于可以将M'空间当中的策略的解元素加入到M的策略当中。
为了简化这个问题,作者认为在数据空间M'当中的 奖励R'和转移概率P' 同样依赖于在M数据空间当中的观测(observations)(我觉得这样的假设也是合理的,因为R 和P是和 s 和a相关的)。在做了这样的假设之后,作者引入了两个函数fR和fP 分别用于的参数化 奖励R'和转移概率P'。函数fR为一个奖励函数映射:当输入的状态图,计算出对应的奖励值;例如,在接近于目标附近的状态得到的奖励值就比较高,而接近于障碍物的状态得到的奖励值就越低;fP 是一个状态转移的函数,是在状态下的确定性的转移动作。
我们假设已经得到了M'空间的数据,那么通过通过VI module都能够得到这个数据空间当中的值函数V'*(s),那么如何来使用这个结果勒?
基于这两点观察,作者巧妙的设计了VI网络:第一.,对于MDP空间的当中的所有的状态s,所得到的值函数V'*(s),那么M'空间当中的最优plan 的所有的信息就被编码到值函数当中;因此,当把这个值函数当作额外的信息加入到M空间的policy当中的时候,从policy当中就可以得到要得到M'空间当中的最优计划的完备的信息。 第二,对于值函数V'*(s)的求解实际上只是依赖于一个状态的子集。因为从状态s能够进行状态转移的状态实际上并不多(也就是临近的几个了)。因此,这个VI模块存在两个特点,一个是产生一个将所有的关于最优的plan 信息都编码的值函数V'*(s);另一个则是将产生一个attention机制,集中在可能的转移当中。于是在一般性的强化学习算法当中便可以加入一个plan 的模块。整体的形式如下:

接下来我们再来看看这个model的具体的实现细节,对于这个VI module,作者将它描述为:一种能够进行规划计算的可导的神经网络(a NN that encodes a differentable planing computation ) 。 因此,我们可以看出作者将它看作是一种的新的神经网络解构。那么,作者为什么会这样说叻? 主要是基于这样的观察:VI的每一次迭代都可以看作是将上一次迭代的值函数Vn 和奖励函R 经过卷积层以及 max-poling层(迭代更新实际上就是每一次找到一个最大的V值来更新当前值函数);因此,在每一个特征图当中实际上可以看作是一个具体的action对应的值函数的结果(也就是Q函数啦);有多少个动作就会对应多少张特征图(这是使用action有限的情况来理解,那我认为连续的action是可用通过一个特征向量来表示的)。那么卷积层当中的卷积和的参数正好对应于 状态的转移概率。如下图所示:
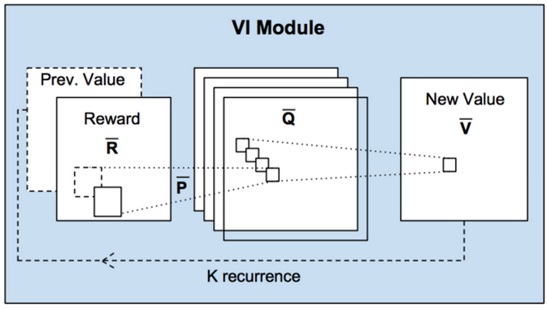
基于这样的观察,作者就提出了本文的VI Network,表达式为:并且在得到的结果当中,对不同通道的Q值进行 max-pooling操作。那我们来理解这个表达式,在表达式当中的l 表示的是各个动作action对应的R层,a其实对应于l; 累加当中的 表示邻近于这个位置的一个区域索引。W 就是网络的参数了,也就是一个卷积核,表示的是可以到周围的几个Q的概率;经过最后的 跨通道的Max-pooling 得到就是一次迭代后的值函数的值。于是这样这个网络具备了值迭代的功能,同时也能够像CNN一样通过BP算法来进行网络的更新。
那么在有了这样的结构之后,如何进行以及Attention模块的设计就是VI设计当中要完成的了。
下面通过一个实验进一步的理解这个网络解构:Grid walking的实验。
如下图所示,是一个28*28 的格子地图,在这个封闭的范围内 随机生成的黑色部分就是障碍物,而其余白色的地方就是能够行走的地方。实验当中,要解决的任务就是给定一个起点位置,需要智能体找到最优的路径到达目的地。(图中的蓝色线是专家样本,橘红为VIN得到的预测结果)
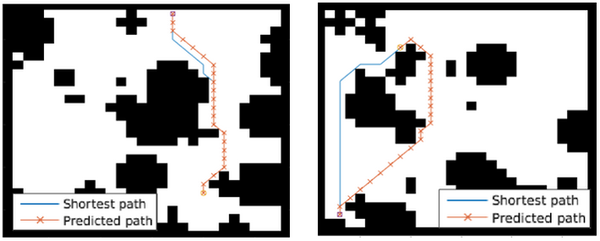
那么在这个实验当中,其实很多经典的算法都能够求解出一个比较好的解但是本文关注的是,通过VI模块之后,网络是否具备有plan的能力。 那么在设计网络的过程当中,这里的M'和真正的MDP空间一样,而函数是为了使得 输入的状态image能够map到一个合理的reward,也就是说,通过这个函数,对于接近于obstacles的位置得到的奖励就应该很小,而在没有障碍物或者是接近于Goal的位置得到的奖励就应该很高。对于函数fR fP 这里直接通过一个3*3 的卷积核进行表示,因为作者认为状态的转移是一种局部的转移。对于迭代的次数的K的选择适合 Grid的大小相关的;最后的Attention机制的设计,作者将其表示为,选出和输出状态具有相同s的Q ,把这个plan的结果作为一般的强化学习算法的输入(例如使用TRPO算法进行训练)。训练好了之后,在一些随机生成的样本上面进行测试(包括起始位置随机,目标位置随机以及障碍物位置随机等等,得到的结果是:VIN预测的准确率高于其余的算法;在越复杂的情况当中表现力就越优于一般的算法,并且具有更强的泛化能力。
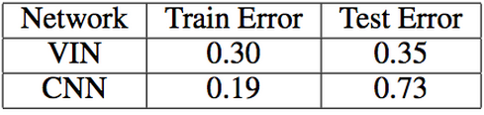 在将其同CNN,以及FCN网络的能力进行比较。分别在三种不同大小的Grid上面进行了比较,VIN网络的能力均超过了其余两种,越复杂的问题当中优势越明显。
在将其同CNN,以及FCN网络的能力进行比较。分别在三种不同大小的Grid上面进行了比较,VIN网络的能力均超过了其余两种,越复杂的问题当中优势越明显。

注文章当中的M‘就是原文当中的
iker Peng 2016年 12月21日