之前做了一个爬虫给自己的CSDN刷量,其实跟写一个简单的小爬虫差不多。在公司里,爬虫一般都跟nlp相关的业务息息相关,这次先爬取一下实习僧网站上的算法JD,为以后学习nlp相关的知识准备一下数据。
先在实习僧上搜索算法岗位,发现url有一定的规律性,后面的两个字段k就是key,p就是page,然后这就解决了遍历所有page的需求。
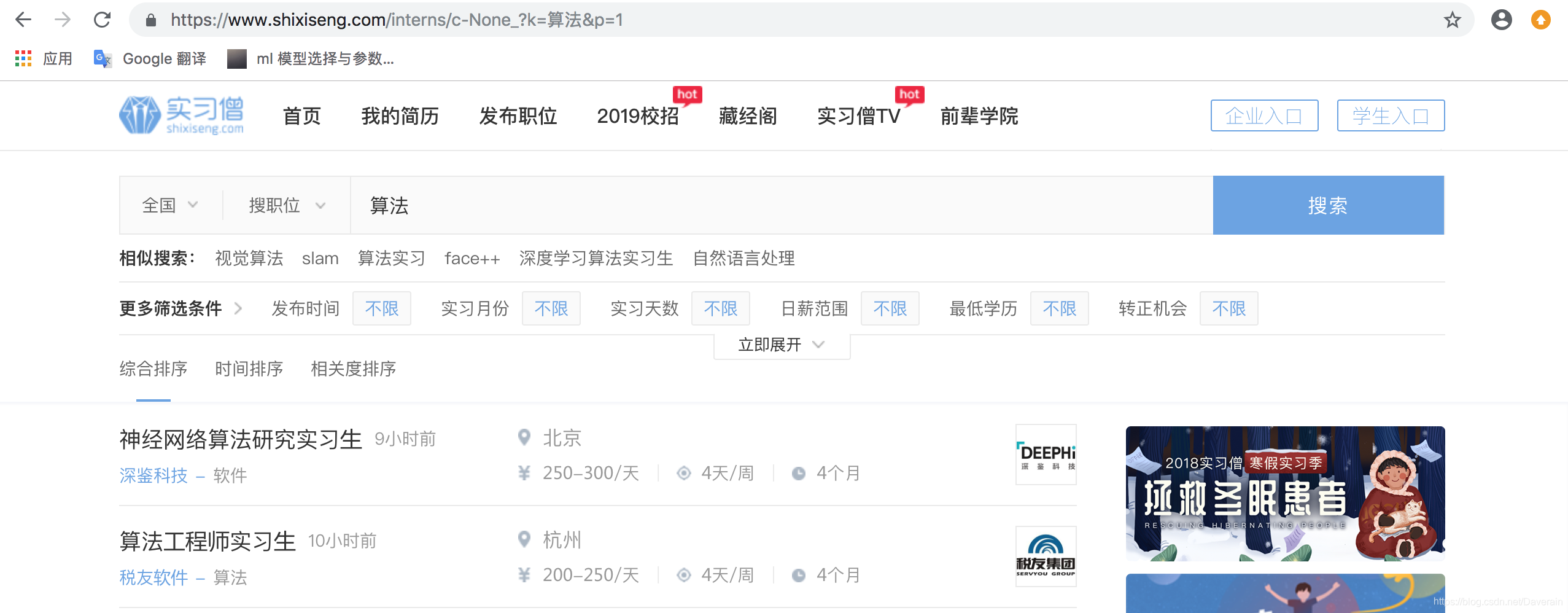
取得每个page的url之后,我们还需要知道这样几件事情:
1.从每个page解析出具体jd的url
2.进行jd详情页解析出jd内容和title
对于第一个问题,我们需要看一下前端代码,这个也很简单,打开前端页面,搜索“href”,或者搜索一些title上有的关键词,去找跳转的link在哪。

然后我们发现点这个link就可以跳转,跳转后的url是https://www.shixiseng.com/intern/inn_vfrzobup4ma4
跟前端页面有一些不同,仔细一看,原来是首页url+后面一部分url,加起来就好啦。
接下来我们去解决第二个问题,同样是看前端代码,然后用beautifulSoup把对应的标签解析出来就好了,这种时候一般装一个看前端代码的ide会方便很多,个人推荐Hbuilder。
这样,比如这些实习jd有100页,我们就可以写一个for循环100次,每次把page里面jd详情页的url拿出来,再进入这些url中把title和jd详情拿出来,写到本地,就万事大吉了。
具体代码如下:
'''
需要导入的包
'''
import requests
from bs4 import BeautifulSoup
import time
'''
write_to_local函数将爬取的jd写入本地
'''
def write_to_local(artile_title,all_page_data):
basic_path = '/Users/xxx/Desktop/sxsSpider/'
import datetime
cur=datetime.datetime.now()
batchtime = str(cur.year)+str(cur.month)+str(cur.day)+str(cur.hour)+str(cur.minute)+str(cur.second)+".txt"
output_path = basic_path + batchtime
output_file = open(output_path,'w')
output_file.write(all_page_data)
output_file.close()
'''
get_page_data函数拿到具体实习jd页面的title和职位描述信息
'''
def get_page_data(page_url):
page_web_data = requests.get(page_url)
soup = BeautifulSoup(page_web_data.text,'lxml')
artile_title = soup.title.get_text()
article_detail = soup.find_all('div', class_='job_detail')[0].get_text()
all_page_data = artile_title + '\n'+ article_detail
write_to_local(artile_title,all_page_data)
time.sleep(1)
print('sleep for 1s')
'''
get_one_page_data函数获取实习僧上指定页的实习jd,写入到本地
'''
def get_one_page_data(one_page_url):
url_front = 'https://www.shixiseng.com'
web_data = requests.get(one_page_url)
soup = BeautifulSoup(web_data.text,'lxml')
divs = soup.find_all('div', class_='name-box clearfix')
url_list = []
for div in divs:
label = div.find_all('a')
url_end = label[0].get('href')
url = url_front + url_end
url_list.append(url)
jd_num = len(url_list)
for i in range(jd_num):
get_page_data(url_list[i])
'''
get_all_jd_data函数获取实习僧上所有页面的jd,写入本地
'''
def get_all_jd_data(base_url,web_site_page_num):
for i in range(web_site_page_num):
page_num = str(i+1)
one_page_url = base_url + page_num
print('getting the data of page'+page_num)
get_one_page_data(one_page_url)
print('finished the data of page'+page_num)
'''
主函数
'''
base_url = 'https://www.shixiseng.com/interns/c-None_st-intern_?k=%E7%AE%97%E6%B3%95&p='
web_site_page_num = 87
get_all_jd_data(base_url,web_site_page_num)