一、引言:
作为一名大三的学生,找实习对于我们而言是迫在眉睫的。实习作为迈入工作的第一步,它的重要性不言而喻,一份好的实习很大程度上决定了我们以后的职业规划。
那么,一份好的实习应该考量哪些因素呢?对于我们计算机专业的学生而言现在的实习趋势是什么呢?
我从实习僧网站爬取了5000条全国互联网行业的职位信息(时间节点06/17),下面开始从职位、薪资、地点、时长四个维度进行分析。
二、数据提取与分析
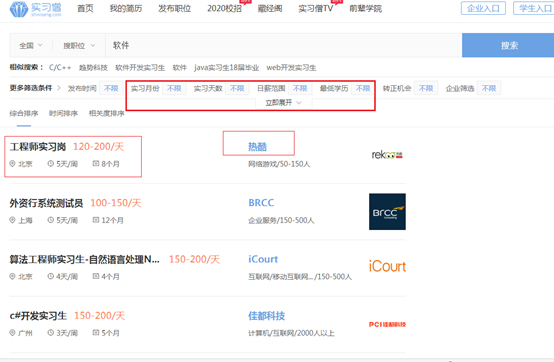
- 爬取的页面
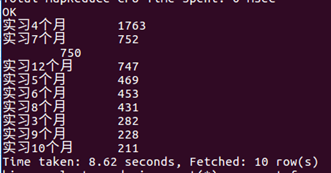
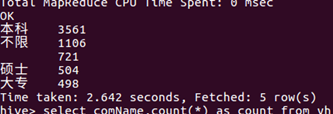
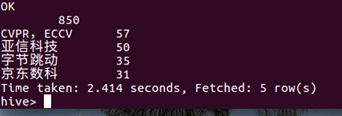
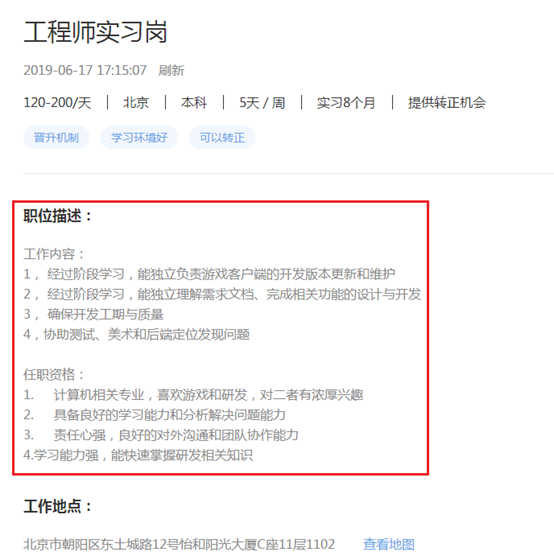
软件类实习中的实习月份需求、实习天数需求、实习岗位、公司名称、薪资范围 和 职业描述(这个需要在 点击实习名称 后 的页面中实现)
- 数据获取工具
主要工具:Python 3.6、Excel2016
涉及爬虫库:requests、Beautiful Soup
涉及反爬虫库:fontTools.ttLib
涉及可视化库:matplotlib、wordcloud、pyecharts
- 使用反爬虫手段对解析页面的数据进行清洗
爬虫是一段自动获取网站数据的程序,一些网站为了保护数据或者避免爬虫过多对服务器造成太大压力就使用了反爬虫技术,在我们所获取信息的实习僧网站就用了反爬虫技术。
- 部分代码
- 爬取结果展示

- 词云分析

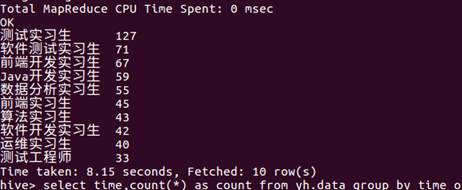
这次爬取的信息一共5000条,除去无用信息一共有4700+数据,可以看到所有岗位中最热门的当属软件测试,可以说软件工程的同学相对来说最容易找到实习。
紧随其后的则是前端,java,数据分析之类。
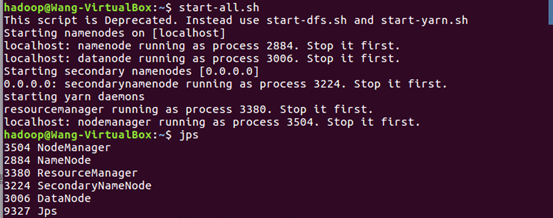
一.将爬虫大作业产生的csv文件上传到HDFS

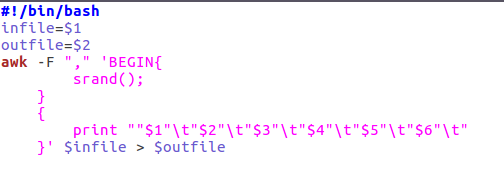
二.对CSV文件进行预处理生成无标题文本文件

三.把hdfs中的文本文件最终导入到数据仓库Hive中
启动数据库后开启hive —> 查看数据库是否传入—>在数据仓库中建表
service mysql start #启动mysql数据库


四.在Hive中查看并分析数据
查看全部信息验证是否上传成功:1 select * from yh.data limit 20(前20条)
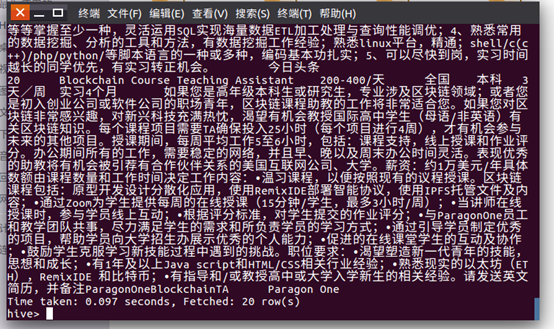
2:查看在HIVE中csv文档的工作名称前200条内容。

五.用Hive对爬虫大作业产生的进行数据分析,写一篇博客描述你的分析过程和分析结果。(10条以上的查询分析)
1.查看发布招工数量最多的城市。最终结论:北上广深还是名列前四,经济越发达的地区招实习生的数量也是比较多的,其中北京和上海的招实习生数量更是广州和深圳的2-3倍之多。
接着就是杭州、成都、南京等二线城市。虽然在