1.网页分析
1.1 url:https://www.shixiseng.com/interns?keyword=python&page=1&city=%E5%85%A8%E5%9B%BD&type=intern
1.2 分析网页内容:

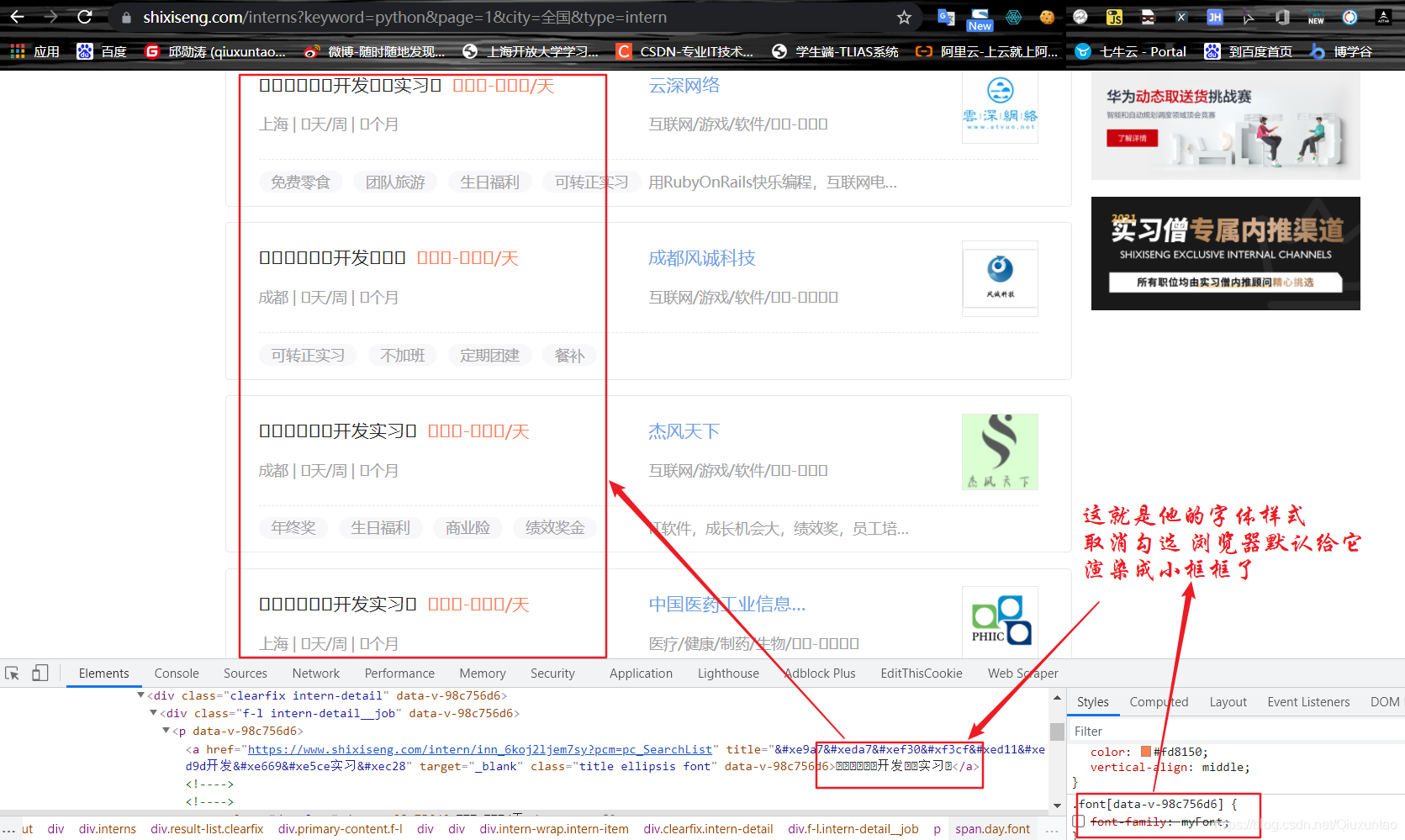
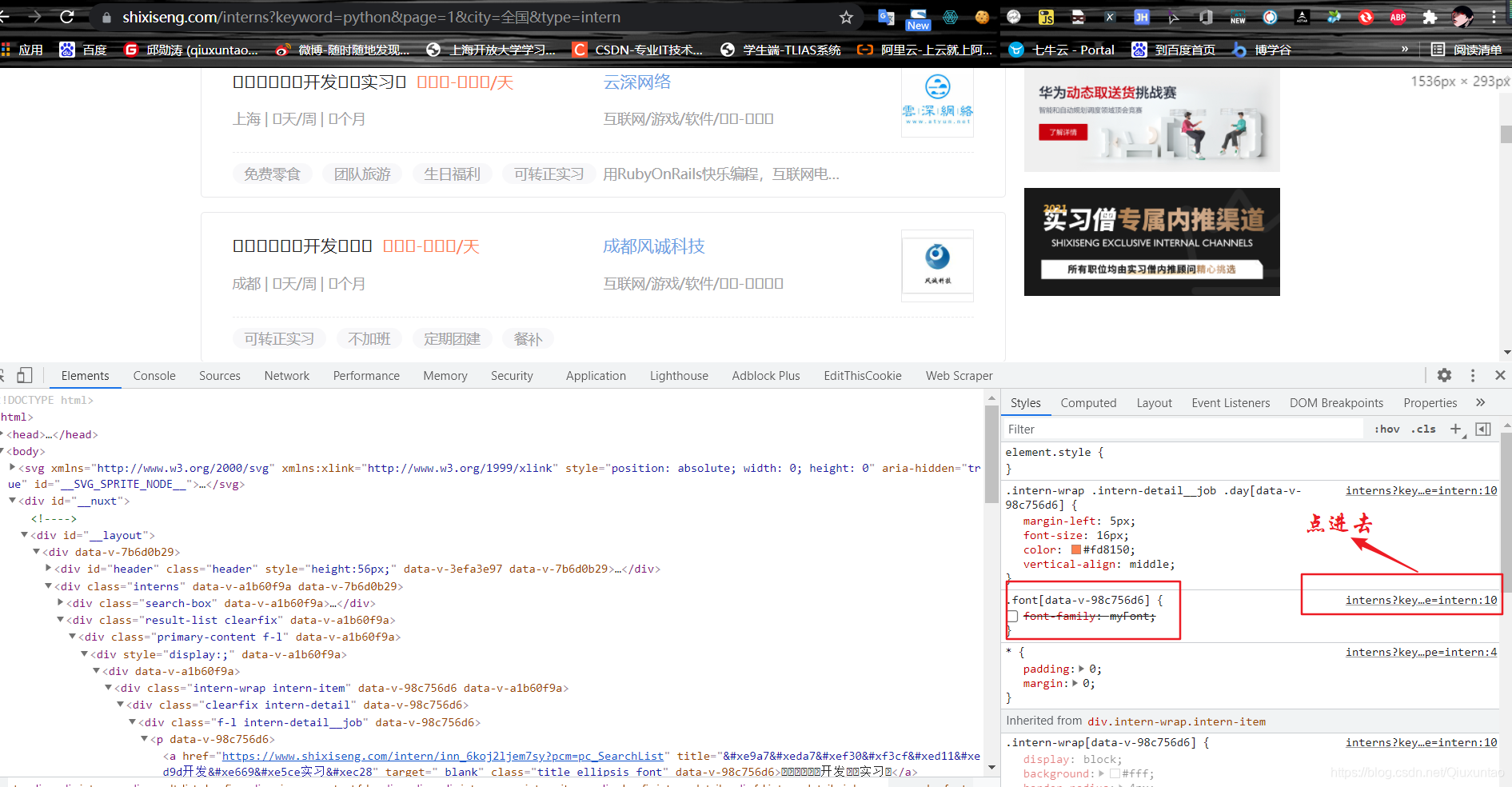
点进去的效果
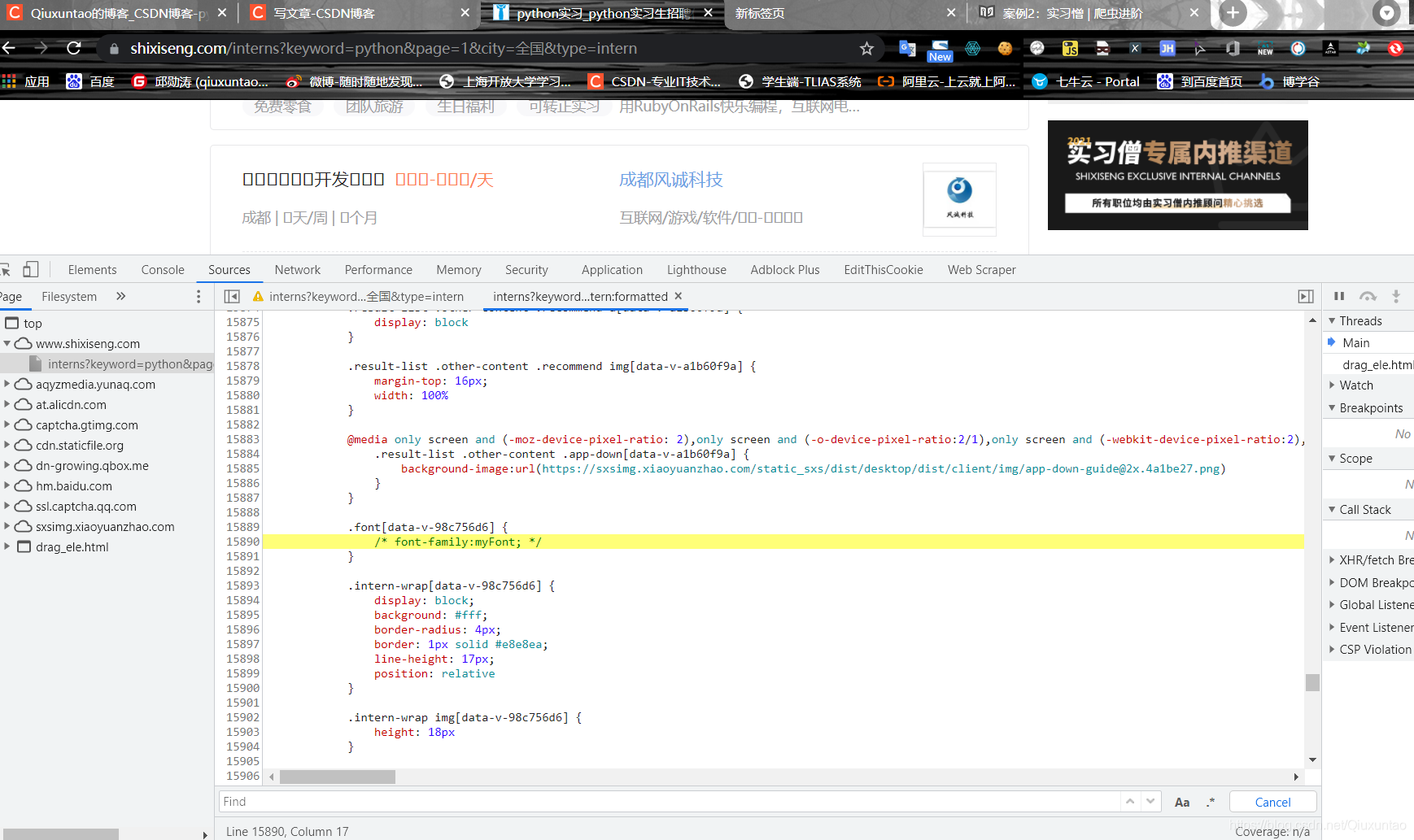
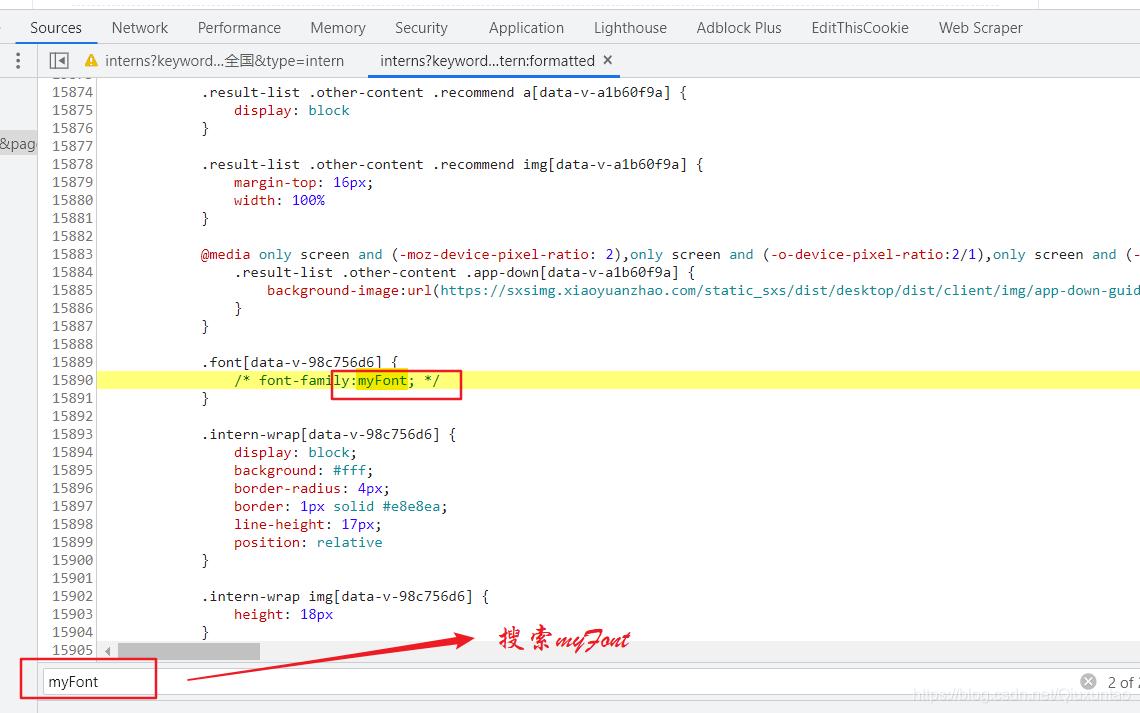
拼接这个网址可以下载一个文件:https://www.shixiseng.com/interns/iconfonts/file?rand=0.7558352854425494

得到一个file文件 修改文件路径为ttf 用软件fontcreator打开 发现就是里面对应的字体 找其对应关系
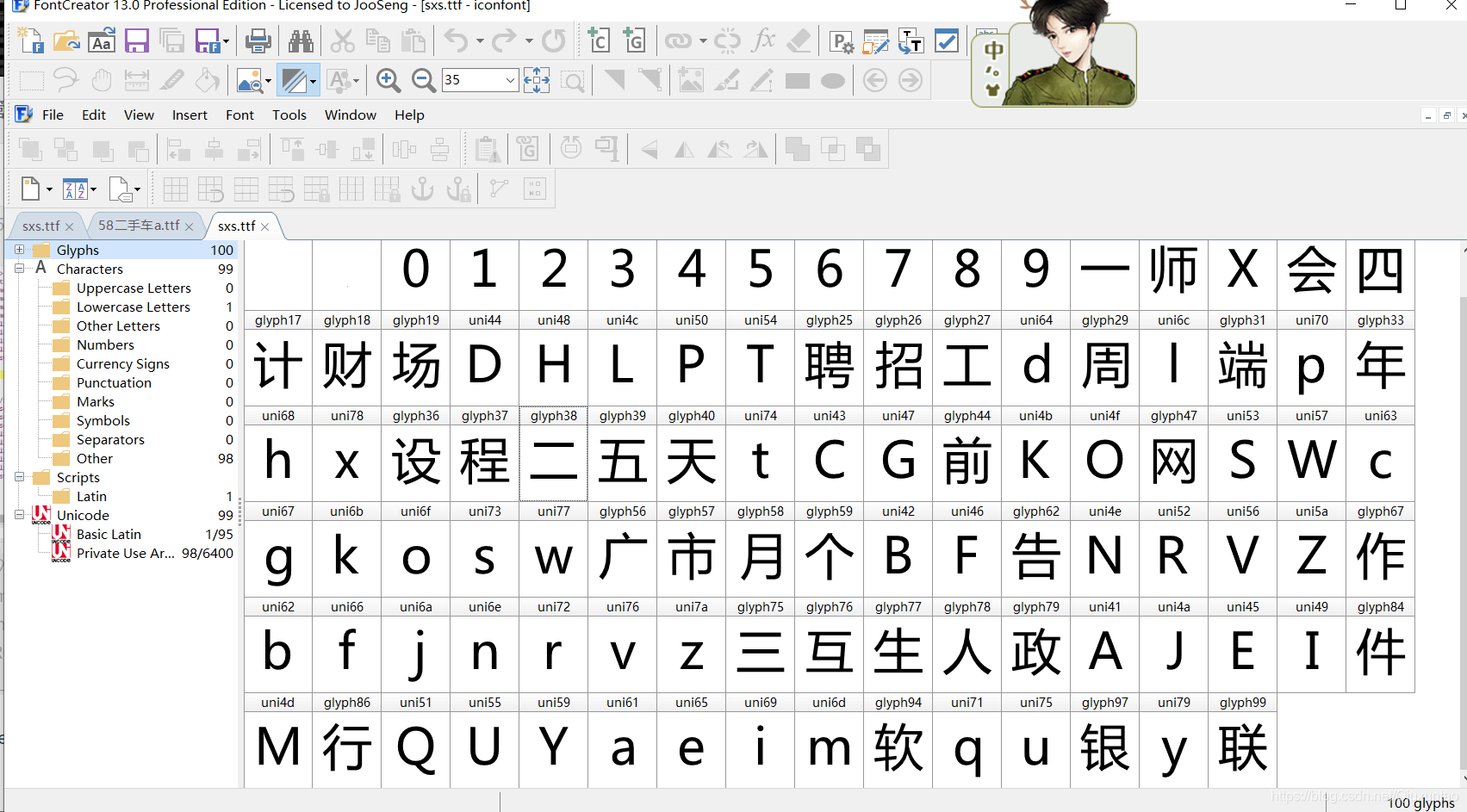
ttf文件转化成xml文件进行分析 cmap是关键 原来是unicode码
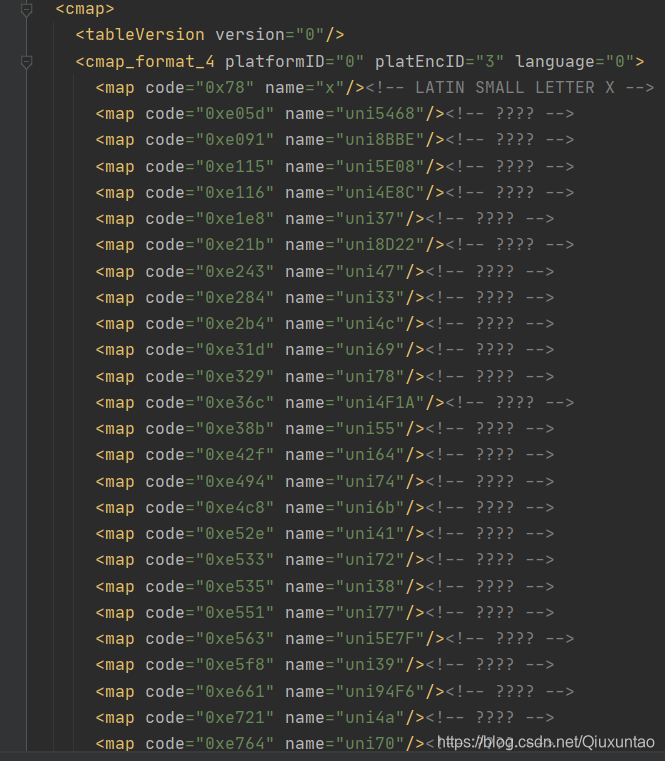
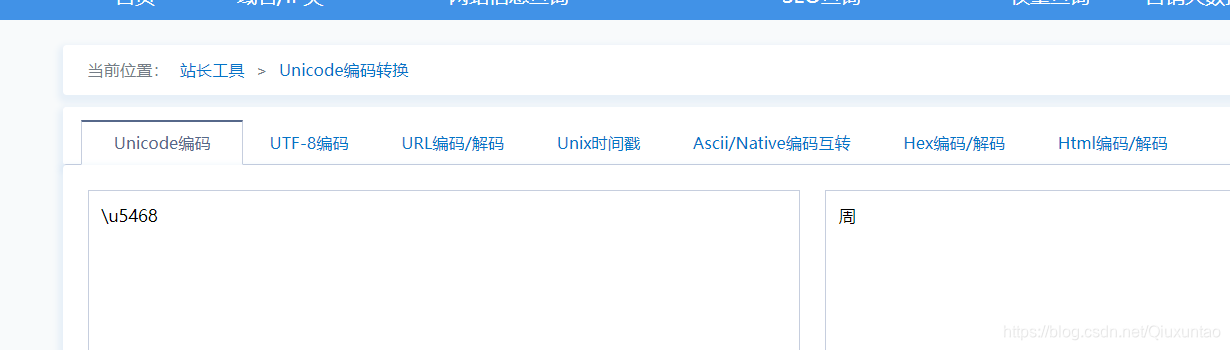
unicode解码 验证了只要把所有秘钥解出来就行了
2.完整代码
from fontTools.ttLib import TTFont
from lxml import etree
# 第1步:获取html,且存为html文件以便后面研究使用
# 第2步:下载html配套的ttf文件
# 第3步:提取ttf中摄影的数据
font = TTFont("./sxs.ttf")
cmap = font.get("cmap").getBestCmap()
# print(cmap)
ttf_dict = dict()
for k, v in cmap.items():
# print(k, v) # 原样数据
# print(hex(k), v) # 转换为十六进制
# print(v[3:])
if v[3:]:
# 1. 提取
# print(hex(k), "\\u00" + v[3:] if len(v[3:]) == 2 else "\\u" + v[3:])
# 2. 转换为真正的字,因为要转化为unicode解码格式 前面要加\u 后补四个数 没有这么多补零
content = "\\u00" + v[3:] if len(v[3:]) == 2 else "\\u" + v[3:]
# 打印unicode码
# print(content)
# 这是uincode解码解出unicode所代表的字
real_content = content.encode('utf-8').decode('unicode_escape')
# 打印十六进制和解出来的码
# print(hex(k), real_content)
# # 3. 替换k
k_hex = hex(k)
# 网页返回的字体是以&#x开头 ,换成以这个开头,下面代码就是直接替换
real_k = k_hex.replace("0x", "&#x")
# print(real_k, real_content)
# 4. 封装为字典
ttf_dict[real_k] = real_content
print("解析后:", ttf_dict)
# 第4步:对下载的实习憎文件(即HTML内容)进行替换
with open("sxs.html", "r",encoding="utf-8") as f:
html = f.read()
for k, v in ttf_dict.items():
html = html.replace(k, v)
# print("替换之后的HTML:")
# print(html)
# 第5步:使用xpath提取想要的数据
html = etree.HTML(html)
li_list = html.xpath("//div[@class='intern-wrap intern-item']")
# print(li_list)
for li in li_list:
title = "".join(li.xpath(".//div[@class='f-l intern-detail__job']//a/text()")[0].split())
price = "".join(li.xpath(".//div[@class='f-l intern-detail__job']//span[@class='day font']/text()")[0].split())
print(title, price)
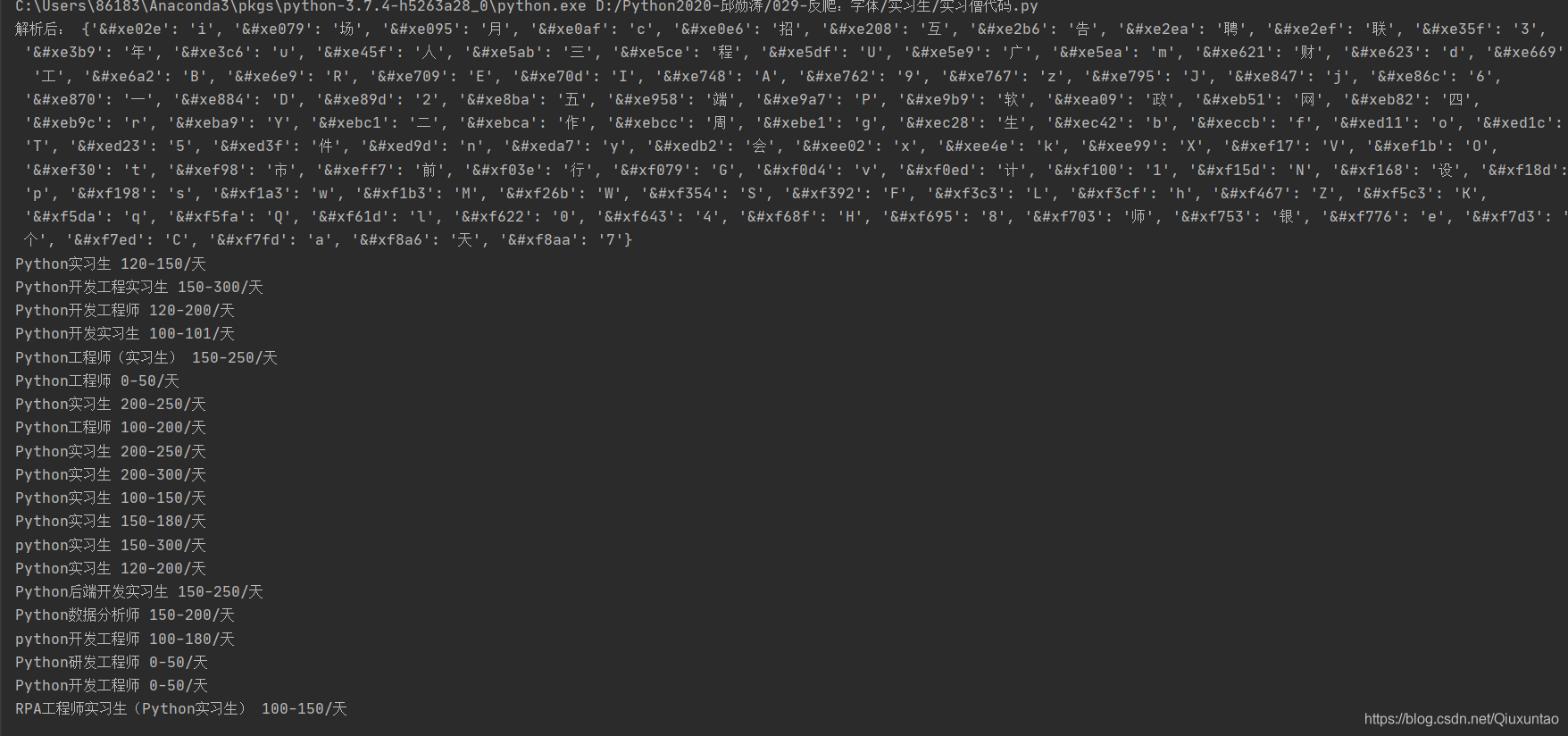
3.效果
4. 温馨提示
每次网页更新都会生成不一样的ttf文件,里面的密钥都会生成新的十六进制内容, 里面的内容每次都不一样