实验目的:
将计科18大类学生分成 3~4个类型。将其可视化显示出来。然后,根据18级物联网分流名单,计算物联1801、物联1802两个班的学生的学生类型占比,输出物联18两个班的学生类型分布饼图。
注:本次代码需要熟练掌握python对excel操作
数据表1:
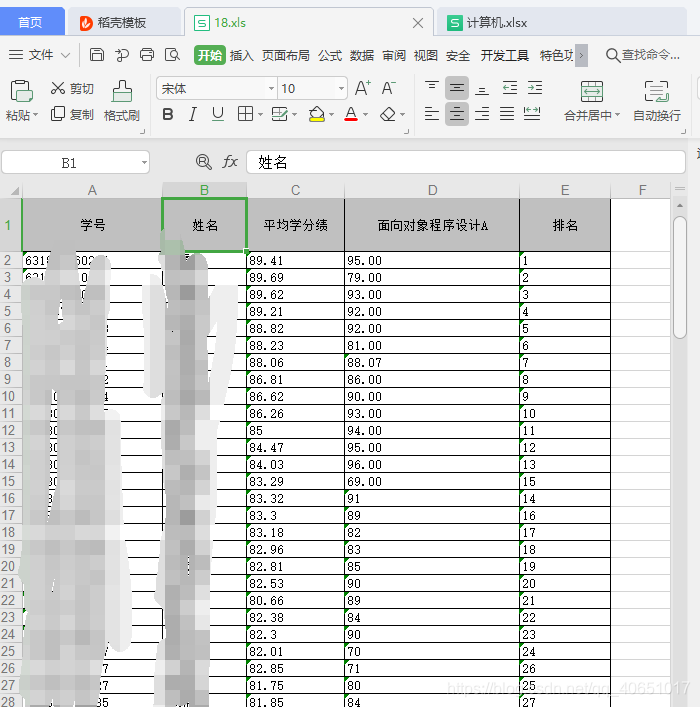
数据表2:
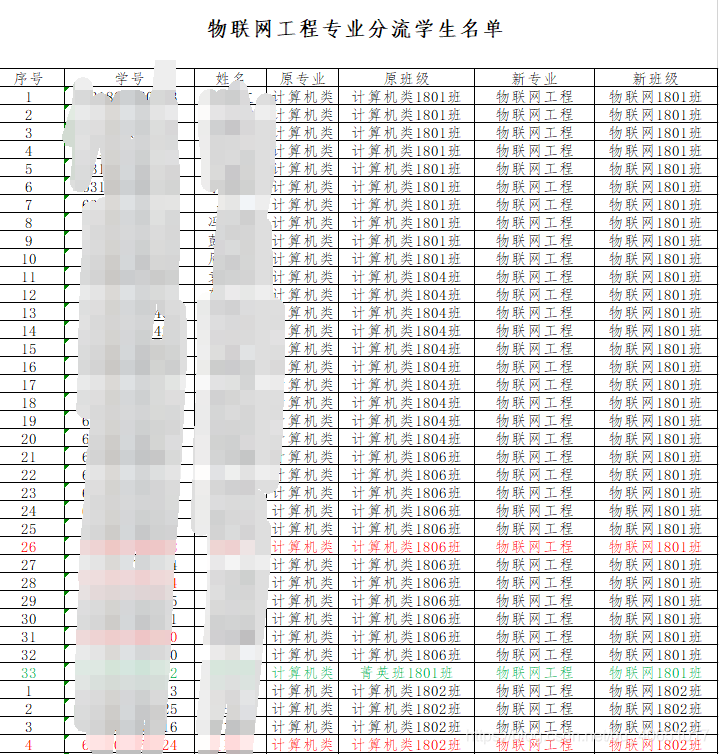
from sklearn import datasets
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
#导入
import pandas as pd
path=r'C:/Users/Administrator/Desktop/18.xls'
data=pd.read_excel(path,header=0)
data1=data.values[1:204,2:4]
x=data.values[1:204,2]
y=data.values[1:204,3]
model = KMeans(n_clusters=3)
#训练模型
model.fit(data1)
#选取行标为100的那条数据,进行预测
prddicted_label= model.predict([[75.88,77]])
all_predictions = model.predict(data1)
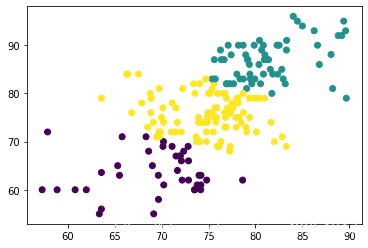
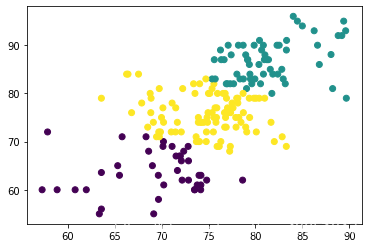
#打印出来对203条数据的聚类散点图
plt.scatter(x, y, c=all_predictions)
plt.show()
from sklearn import datasets
import matplotlib.pyplot as plt
import matplotlib.pyplot as plt1
from sklearn.cluster import KMeans
#导入
import pandas as pd
path=r'C:/Users/Administrator/Desktop/18.xls'
data=pd.read_excel(path,header=0)
data1=data.values[0:198,2:4]
#平均学分绩
x=data.values[0:198,2]
#面向对象成绩
y=data.values[0:198,3]
#这里已经知道了分4类,其他分类这里的参数需要调试
model = KMeans(n_clusters=3)
#训练模型
model.fit(data1)
#选取行标为100的那条数据,进行预测
prddicted_label= model.predict([[75.88,77]])
#预测全部203条数据
all_predictions = model.predict(data1)
#print(all_predictions)
a={}
aa=0
bb=0
cc=0
#print(a[data.values[3,0]])
for i in range(len(all_predictions)):
a[data.values[i,1]]=all_predictions[i]
if all_predictions[i] ==0:
aa+=1
if all_predictions[i] ==1:
bb+=1
if all_predictions[i] ==2:
cc+=1
#print(a[631807060214])
#print(aa)
aa1=aa/len(all_predictions)
bb1=bb/len(all_predictions)
cc1=cc/len(all_predictions)
print('\n')
values1=[aa1,bb1,cc1]
colors=['green','red','orange']
print("三类学生分布饼图")
plt1.pie(values1,autopct='%3.1f %%',colors=colors)
plt1.show()
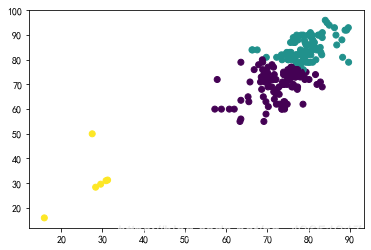
print("三类学生分布散点图")
plt.scatter(x, y, c=all_predictions)
plt.show()
path1=r'C:/Users/Administrator/Desktop/计算机.xlsx'
data2=pd.read_excel(path1,header=1)
#print(data2)
b=0
c=0
d=0
#记录字典没有索引值的个数
x=0
#print(data2.values[1,2])
#print(a[631807060214])
#print(len(data2))
for i in range(len(data2)):
e=data2.values[i,2]
#这里2通过名字来获取对应值;改为1表明通过学号来获取对应值
#print(e)
try:
if a[e]==0:
b=b+1
if a[e]==1:
c+=1
if a[e]==2:
d+=1
except:
x+=1
b1=b/(len(data2)-x)
c1=c/(len(data2)-x)
d1=d/(len(data2)-x)
#print(b)
print('\n')
values=[b1,c1,d1]
colors=['green','red','orange']
print('\n')
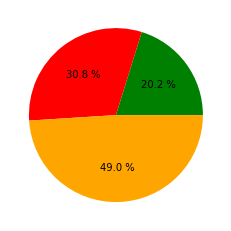
print("物联18两个班的学生类型分布饼图")
plt1.pie(values,autopct='%3.1f %%',colors=colors)
plt1.show()
#打印出来对203条数据的聚类散点图
三类学生分布饼图
三类学生分布散点图
物联18两个班的学生类型分布饼图
本次代码调试由于不知道问题在哪儿费了很多时间,最后将各个地方的值打印出来找到错误,调试成功。
