今天学习了一下逻辑回归,并且实现了对手写图片图集MNIST 的学习
读者可以根据代码做少聊修改便可以完成一个简单的数字识别器
逻辑回归
什么事逻辑回归?
逻辑回归和线性回归都是一种拟合方式,都是监督学习中的方式。
线性回归是给一个结果,我们来预测她的结果是什么,我们举的例子是房价
逻辑回归则不是,它是对于事物判断的可能性,即概率,我们举个例子:判断这个图片是不是一组手写数字
而监督学习会给我们一大堆已经标号的数据,【图A-是】【图B-不是】等等…我们通过机器学习可以让他判断这个是不是我们想要的图片(非卷积)
那么对于逻辑回归,它的样本公式和线性的不同: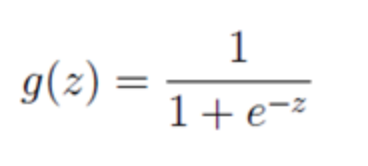
看得出来,随着z的不断变大,g的值趋近0
也因为这种特性,它的损失函数不再是MSE(方差),而是Cross Entropy(交叉熵),对于交叉熵的概念可以参考交叉熵解释。
这个在tf当中就是一句话:【softmax_cross_entropy_with_logits】
在逻辑回归模型中,我们最大化似然函数和最小化损失函数实际上是等价的,因此他的代价函数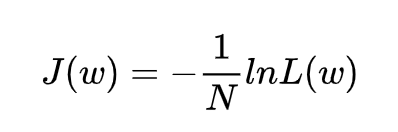
其中L(w)是似然函数: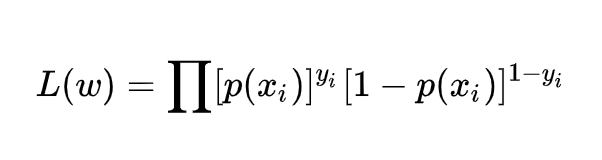
其中p(x)代表发生概率
那么对他使用梯度向下的方法 该怎么办呢?
梯度向下算法
还是老样子,其实我们求导之后选择变化最大的方向去优化即可
梯度下降是通过 J(w) 对 w 的一阶导数来找下降方向,并且以迭代的方式来更新参数,更新方式为,其中 k 为迭代次数:
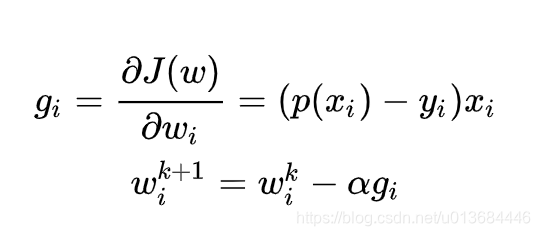
当然,在代码里我们tf也有库的封装去训练他,下面我们开始代码实现
代码实现
思路:首先我们还是老样子,获取数据集,点击这里进行下载:
train-images-idx3-ubyte.gz: training set images (9912422 bytes)
train-labels-idx1-ubyte.gz: training set labels (28881 bytes)
t10k-images-idx3-ubyte.gz: test set images (1648877 bytes)
t10k-labels-idx1-ubyte.gz: test set labels (4542 bytes)
引用这个训练集的方法,我放在和py文件同样目录下:
MNIST = input_data.read_data_sets("./", one_hot=True)
然后就要开始构建这个学习的函数了,由于这次我们使用了数据集,我们需要使用分批的形式来训练,这样可以快速达成训练目标,当然也要训练25次,这样提高模型精度
最后再使用测试集来完成测试,并绘制整个loss的波动图
learning_rate = 0.01 #设置学习速率
batch_size = 128 #批次数量
n_epochs = 25 #训练次数
#下面是初始化,一个分类器的W、b是784维向量,10个分类器就是784*10的矩阵
X = tf.placeholder(tf.float32, [batch_size, 784])
Y = tf.placeholder(tf.float32, [batch_size, 10])
w = tf.Variable(tf.random_normal(shape=[784,10], stddev=0.01), name="weights")
b = tf.Variable(tf.zeros([1, 10]), name="bias")
构建模型,很熟悉的模型,和线性回归类似即可,原因是通过训练集的训练,参数会变成合理的形式(向量化)
logits = tf.matmul(X, w) + b
之后构建交叉熵的损失函数,再加上一个优化器,不多说了,和线性回归一样的:
entropy = tf.nn.softmax_cross_entropy_with_logits(labels=Y, logits=logits)
loss = tf.reduce_mean(entropy)
optimizer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate).minimize(loss)
开始学习:
init = tf.global_variables_initializer()#初始化
with tf.Session() as sess:
sess.run(init)
n_batches = int(MNIST.train.num_examples/batch_size)#一批数量
for i in range(n_epochs):
for j in range(n_batches):
X_batch, Y_batch = MNIST.train.next_batch(batch_size)#去出这一批的训练集
loss_ = sess.run([optimizer, loss], feed_dict={ X: X_batch, Y: Y_batch})#去除的训练集丢进去训练
print("Loss of epochs[{0}] batch[{1}]: {2}".format(i, j, loss_))
然后加入测试集的代码,测试的原理是预测结果记录下来,再和标准答案比对,算出正确率即可:
with tf.Session() as sess:
sess.run(init)
n_batches = int(MNIST.test.num_examples/batch_size)
total_correct_preds = 0
for i in range(n_batches):
X_batch, Y_batch = MNIST.test.next_batch(batch_size)
preds = tf.nn.softmax(tf.matmul(X_batch, w) + b) #算预测结果
correct_preds = tf.equal(tf.argmax(preds, 1), tf.argmax(Y_batch, 1)) #判断预测结果和标准结果
accuracy = tf.reduce_sum(tf.cast(correct_preds, tf.float32))#先转化判断的字符类型,再降维求和,这样就得到了一大堆压缩后的判断结果
total_correct_preds += sess.run(accuracy) #之前都是公式,必须要run才有用,然后记录数量
print("Accuracy {0}".format(total_correct_preds/MNIST.test.num_examples))#判断正确率并输出
这样我们就得到了一个合格的模型,并且争取率一半都会到90%以上!
可是我们现在还需要把她的loss值输出出来,看看它收敛效果怎么样,以便之后改进数值调整
使用matplotlib.pyplot库来完成数据的可视化即可:
import matplotlib.pyplot as plt
cost_accum = []
...
with tf.Session() as sess:
sess.run(init)
n_batches = int(MNIST.train.num_examples/batch_size)
for i in range(n_epochs):
for j in range(n_batches):
X_batch, Y_batch = MNIST.train.next_batch(batch_size)
loss_ = sess.run([optimizer, loss], feed_dict={ X: X_batch, Y: Y_batch})
print("Loss of epochs[{0}] batch[{1}]: {2}".format(i, j, loss_))
cost_accum.append(loss_)#记录结果
...
#绘制图形
plt.plot(range(len(cost_accum)), cost_accum, 'r')
plt.title('Logic Regression Cost Curve')
plt.xlabel('epoch*batch')
plt.ylabel('loss')
plt.show()
最后完整代码如下:
#-*- coding:utf-8 -*-
import time
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
MNIST = input_data.read_data_sets("./", one_hot=True)
cost_accum = []
learning_rate = 0.01
batch_size = 128
n_epochs = 25
X = tf.placeholder(tf.float32, [batch_size, 784])
Y = tf.placeholder(tf.float32, [batch_size, 10])
w = tf.Variable(tf.random_normal(shape=[784,10], stddev=0.01), name="weights")
b = tf.Variable(tf.zeros([1, 10]), name="bias")
logits = tf.matmul(X, w) + b
entropy = tf.nn.softmax_cross_entropy_with_logits(labels=Y, logits=logits)
loss = tf.reduce_mean(entropy)
optimizer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate).minimize(loss)
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
n_batches = int(MNIST.train.num_examples/batch_size)
for i in range(n_epochs):
for j in range(n_batches):
X_batch, Y_batch = MNIST.train.next_batch(batch_size)
loss_ = sess.run([optimizer, loss], feed_dict={ X: X_batch, Y: Y_batch})
print("Loss of epochs[{0}] batch[{1}]: {2}".format(i, j, loss_))
cost_accum.append(loss_)
n_batches = int(MNIST.test.num_examples/batch_size)
total_correct_preds = 0
for i in range(n_batches):
X_batch, Y_batch = MNIST.test.next_batch(batch_size)
preds = tf.nn.softmax(tf.matmul(X_batch, w) + b) #算预测结果
correct_preds = tf.equal(tf.argmax(preds, 1), tf.argmax(Y_batch, 1)) #判断预测结果和标准结果
accuracy = tf.reduce_sum(tf.cast(correct_preds, tf.float32))#先转化判断的字符类型,再降维求和,这样就得到了一大堆压缩后的判断结果
total_correct_preds += sess.run(accuracy) #之前都是公式,必须要run才有用,然后记录数量
print("Accuracy {0}".format(total_correct_preds/MNIST.test.num_examples))#判断正确率并输出
plt.plot(range(len(cost_accum)), cost_accum, 'r')
plt.title('Logic Regression Cost Curve')
plt.xlabel('epoch*batch')
plt.ylabel('loss')
print('show')
plt.show()
顺利的话,你将得到这样的结果:
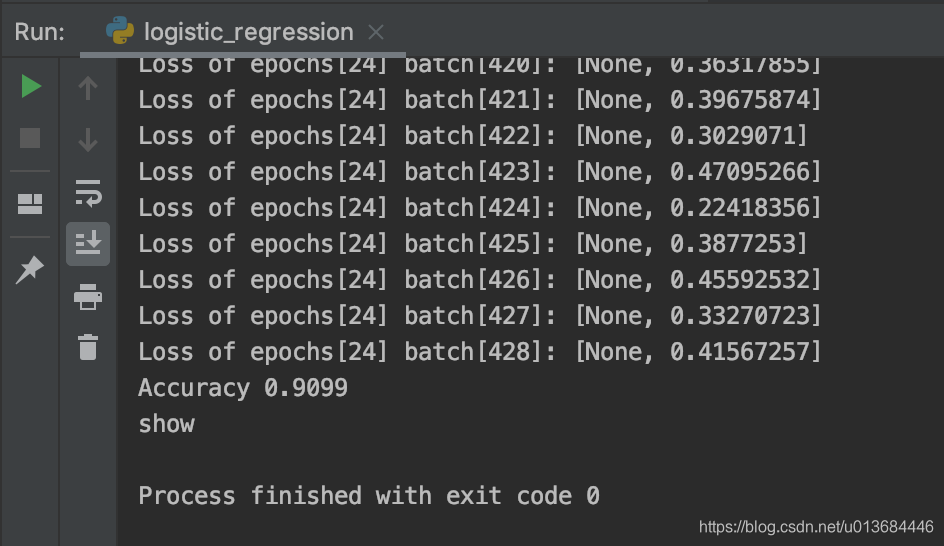
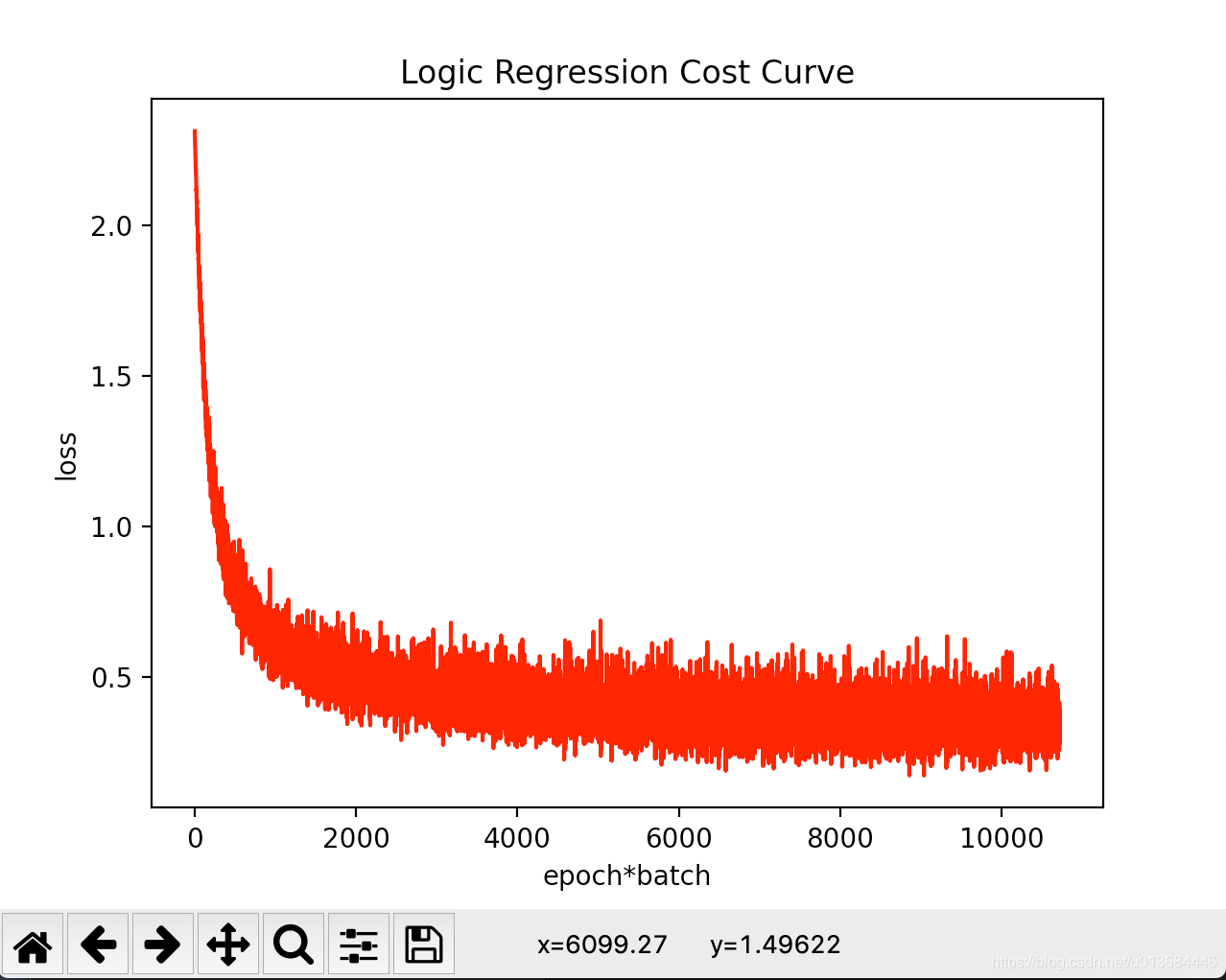
可以看出模型在前期快速收敛,而在后期的loss一直在波动,但是误差值不超过0.7,整个函数完成收敛。
此外我们将优化器变成【AdamOptimizer】可以得到结果如下:
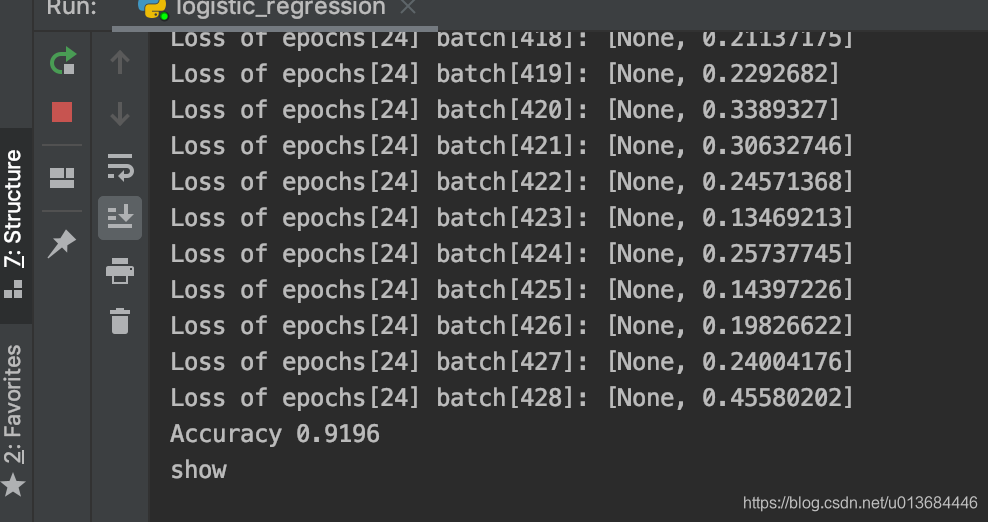
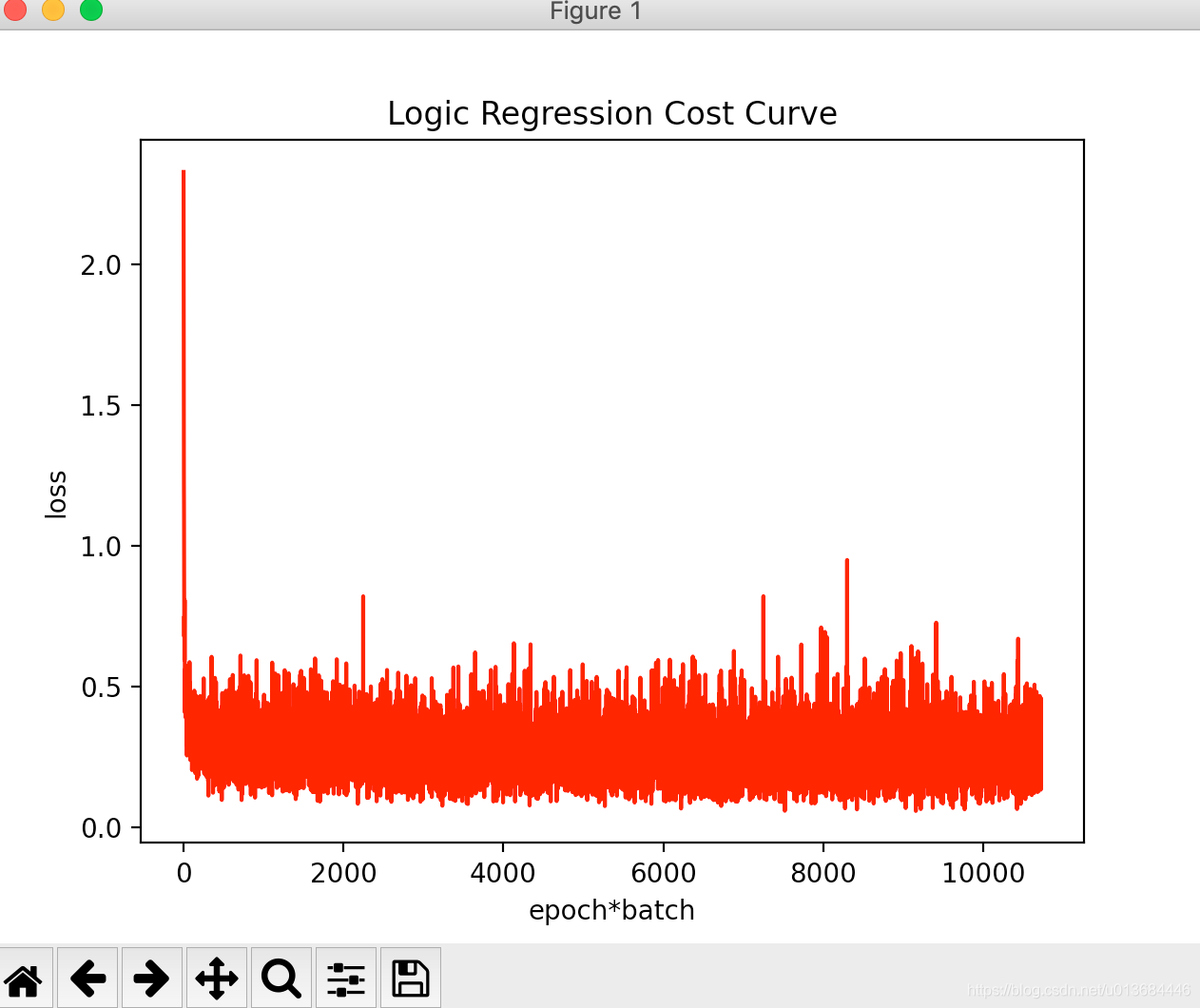
可以明显看出,收敛速度变快了,但是还是有部分loss毛刺严重,这也在另一个角度诠释了两个算法的优势劣势。
如何优化尾部这么大的波动呢?那就要开始构建神经网络了,这样才可以合理提高预测的准确度,下一节浅层神经网络。
