转载:https://cloud.tencent.com/developer/article/1178368
seaborn针对分类型的数据有专门的可视化函数,这些函数可大致分为三种:
- 分类数据散点图:swarmplot(), stripplot()
- 分类数据的分布图: boxplot(), violinplot()
- 分类数据的统计估算图 : barplot(), pointplot()
import numpy as np import pandas as pd import matplotlib as mpl import matplotlib.pyplot as plt import seaborn as sns sns.set(style="whitegrid", color_codes=True) np.random.seed(sum(map(ord, "categorical"))) #下载三个数据集 titanic = sns.load_dataset("titanic") tips = sns.load_dataset("tips") #panda DataFrame结构 iris = sns.load_dataset("iris")
#分类数据散点图:stripplot();x是分类特征day,y是目标变量,连续值 sns.stripplot(x="day",y="total_bill",data=tips)
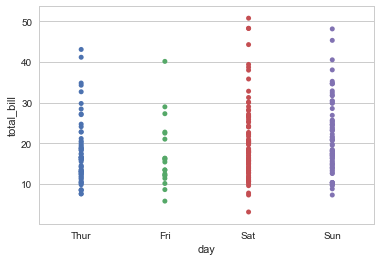
横坐标是分类数据,一些数据点上会互相重叠,不便于观察,一个简单的解决办法是加入 jitter 参数,调整横坐标位置:
sns.stripplot(x="day", y="total_bill", data=tips, jitter=True)
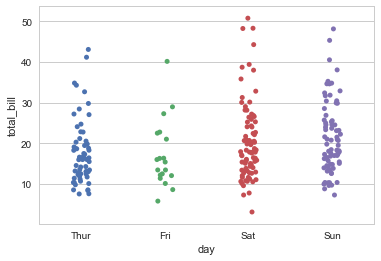
#分类数据散点图:swarmplot(),这个函数的好处就是所有的点都不会重叠,这样可以很清晰的观察到数据的分布 sns.swarmplot(x="day", y="total_bill", data=tips)

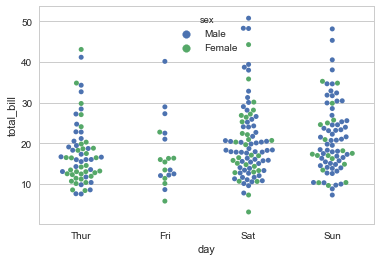
通过 hue 参数加入另一个嵌套的分类变量,而且嵌套的分类变量可以以不同的颜色区别
sns.swarmplot(x="day", y="total_bill", hue="sex", data=tips)
seaborn 会尝试推断出分类变量的顺序。数据是 pandas 的分类数据类型,那么就是使用默认的分类数据顺序,如果是其他的数据类型,字符串类型的类别将按照它们在DataFrame中显示的顺序进行绘制,但是数组类别将被排序:
sns.swarmplot(x="size", y="total_bill", data=tips)

将分类变量放在垂直轴上是非常有用的(当类别名称相对较长或有很多类别),可以使用 orient 关键字强制定向,但通常可以互换x和y的变量的数据类型来完成:
sns.swarmplot(x="total_bill", y="day", hue="time", data=tips)

分类数据分布图:
箱型图:箱型图可以直观观察到数据的四分位分布(1/4分位,中位数,3/4分位,以及四分位距),这种可视化对于在机器学习的预处理阶段(尤其是发现数据异常离散值)十分有效。
sns.boxplot(x="day", y="total_bill", hue="time", data=tips)