课设简介
人工智能课程设计大作业(大三上选修,考了94分)
主题:对亚马逊商城衣服,鞋,珠宝的评论数据集进行数据分析并可视化
数据集说明
数据集来源为亚马逊产品数据(网站数据集包含来自亚马逊的产品评论和元数据,包括 1996年5月至2014 年 7 月的 1.428 亿条评论)的一部分,具体为服装、鞋子和珠宝部分(一共278,677 条评论,45.1MB),网址为:亚马逊审查数据 (ucsd.edu),所用数据如下图:
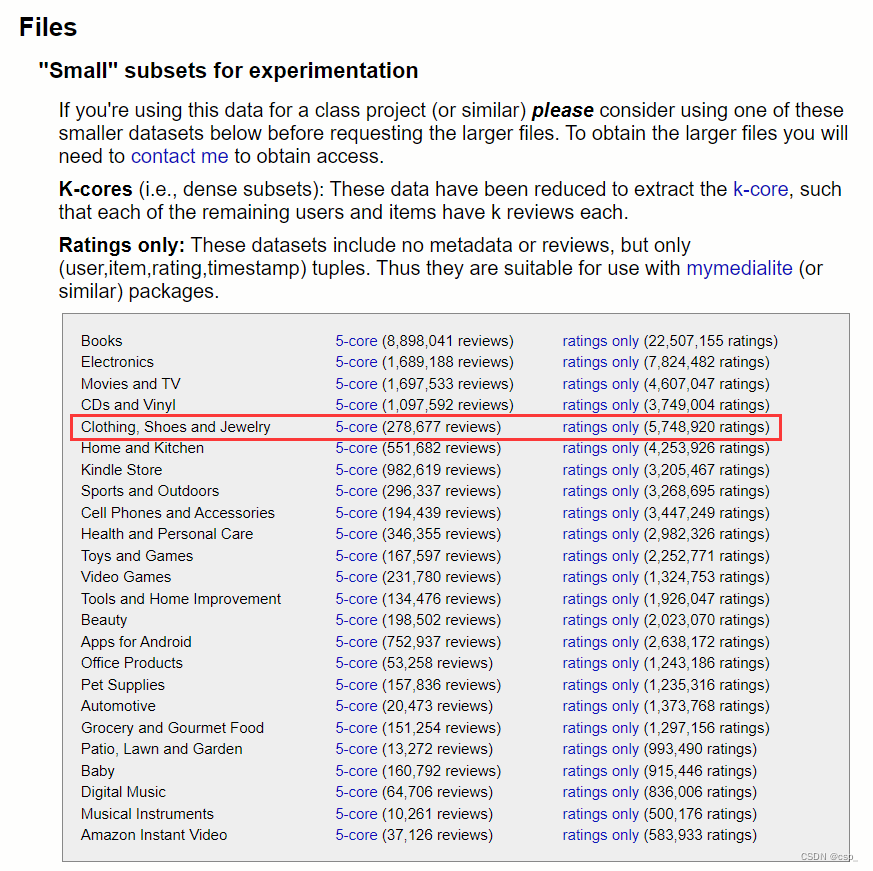
数据集要下用于实验的"小"子集(本次实验为45.1MB),对于以G计算的较大数据,下载速度会很慢,还可能突然网速为0,另一方面,数据处理时间过长,不适合编译器的处理,所以我选取的样本是:“Small” subsets for experimentation
评论数据集的信息:
1产品编号asin - ID of the product, e.g. 0000013714
2评价认可度helpful - helpfulness rating of the review, e.g. 2/3
3产品评分overall - rating of the product
4产品评价reviewText - text of the review
5评论时间reviewTime - time of the review (raw)
6评论者编号reviewerID - ID of the reviewer, e.g. A2SUAM1J3GNN3B
7评论者名字reviewerName - name of the reviewer
8评论的概要summary - summary of the review
9发表评论的时间unixReviewTime - time of the review (unix time)
数据集的一个评论样例:
{
"reviewerID": "A2SUAM1J3GNN3B",
"asin": "0000013714",
"reviewerName": "J. McDonald",
"helpful": [2, 3],
"reviewText": "I bought this for my husband who plays the piano. He is having a wonderful time playing these old hymns. The music is at times hard to read because we think the book was published for singing from more than playing from. Great purchase though!",
"overall": 5.0,
"summary": "Heavenly Highway Hymns",
"unixReviewTime": 1252800000,
"reviewTime": "09 13, 2009"
}
例如,我这里reviews_merged.json的前3条信息如下(共278677条信息):
{
"reviewerID": "A1KLRMWW2FWPL4", "asin": "0000031887", "reviewerName": "Amazon Customer \"cameramom\"", "helpful": [0, 0], "reviewText": "This is a great tutu and at a really great price. It doesn't look cheap at all. I'm so glad I looked on Amazon and found such an affordable tutu that isn't made poorly. A++", "overall": 5.0, "summary": "Great tutu- not cheaply made", "unixReviewTime": 1297468800, "reviewTime": "02 12, 2011"}
{
"reviewerID": "A2G5TCU2WDFZ65", "asin": "0000031887", "reviewerName": "Amazon Customer", "helpful": [0, 0], "reviewText": "I bought this for my 4 yr old daughter for dance class, she wore it today for the first time and the teacher thought it was adorable. I bought this to go with a light blue long sleeve leotard and was happy the colors matched up great. Price was very good too since some of these go for over $15.00 dollars.", "overall": 5.0, "summary": "Very Cute!!", "unixReviewTime": 1358553600, "reviewTime": "01 19, 2013"}
{
"reviewerID": "A1RLQXYNCMWRWN", "asin": "0000031887", "reviewerName": "Carola", "helpful": [0, 0], "reviewText": "What can I say... my daughters have it in orange, black, white and pink and I am thinking to buy for they the fuccia one. It is a very good way for exalt a dancer outfit: great colors, comfortable, looks great, easy to wear, durables and little girls love it. I think it is a great buy for costumer and play too.", "overall": 5.0, "summary": "I have buy more than one", "unixReviewTime": 1357257600, "reviewTime": "01 4, 2013"}
数据预处理
首先从json文件(reviews_merged.json)读取数据,数据集用相对路径方便一些,不然得每个.ipynb文件下面都复制一份
我在jupyter上跑的,首先导入一些数据分析的库:
%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pandas import DataFrame
import nltk
from sklearn.neighbors import NearestNeighbors
from sklearn.linear_model import LogisticRegression
from sklearn import neighbors
from scipy.spatial.distance import cosine
from sklearn.metrics import classification_report
from sklearn.metrics import accuracy_score
from sklearn.feature_selection import SelectKBest
from sklearn.feature_extraction.text import CountVectorizer, TfidfTransformer
import re
import string
from wordcloud import WordCloud, STOPWORDS
from sklearn.metrics import mean_squared_error
# 忽略了警告错误的输出
import warnings
warnings.filterwarnings("ignore")
因为直接在jupyter下用matplotlib画图会出现后台运行的exe文件,而网页上无法显示图片,所以需要在头文件上加上一行代码:%matplotlib inline,具体可看:
先介绍一下json文件:
- 任何支持的类型都可以通过 JSON 来表示,例如字符串、数字、对象、数组等。但是对象和数组是比较特殊且常用的两种类型
- 对象:对象在 JS 中是使用花括号包裹 {} 起来的内容,数据结构为
{key1:value1, key2:value2, ...}的键值对结构。在面向对象的语言中,key 为对象的属性,value 为对应的值。键名可以使用整数和字符串来表示。值的类型可以是任意类型 - 数组:数组在 JS 中是方括号 [] 包裹起来的内容,数据结构为
["java", "javascript", "vb", ...]的索引结构。在 JS 中,数组是一种比较特殊的数据类型,它也可以像对象那样使用键值对,但还是索引使用得多。同样,值的类型可以是任意类型
之后尝试用Pandas的read_json()读取文件,但是报错:ValueError: Trailing data,后来发现是 json 格式问题,需将文件里面的字典作为元素保存在列表中,把文件每一行看做一个完整的字典,然后在函数中修改参数pd.read_json('data.json',lines=True),lines 默认为 False ,设为 True 后可以按行读取 json 对象,借鉴博客:
Pandas read_json()时报错ValueError: Trailing data
# df = pd.read_csv('reviews.csv')
df = pd.read_json('reviews_merged.json',lines=True)
# 输出初始时数据
df
结果:
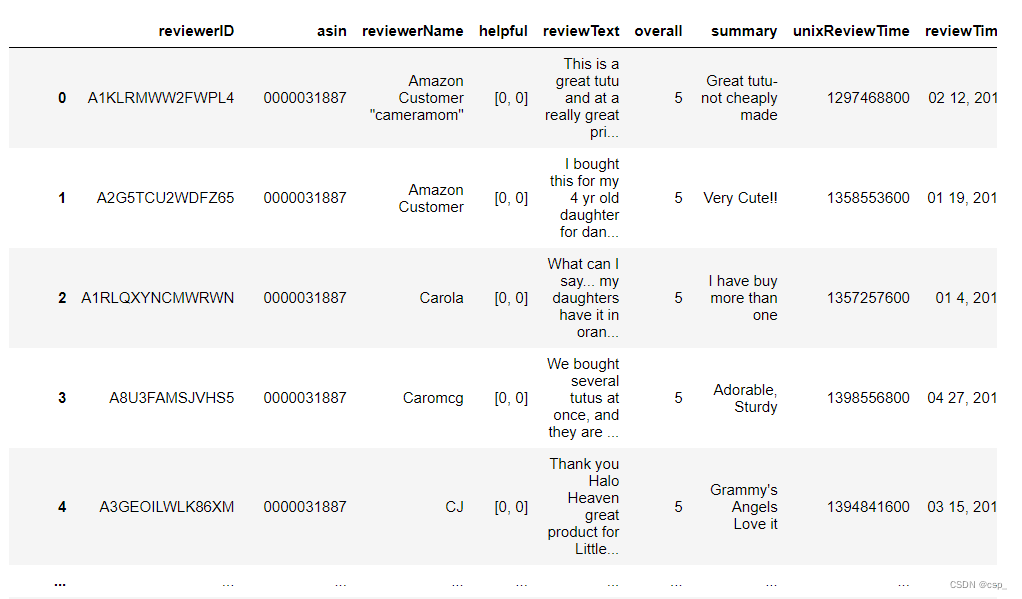
在这里说一下,Pandas DataFrame是带有标签轴(行和列)的二维大小可变的,可能是异构的表格数据结构,算术运算在行和列标签上对齐。可以将其视为Series对象的dict-like容器。它也是Pandas的主要数据结构,其用法可看:
pandas 入门:DataFrame的创建,读写,插入和删除
# 获取列索引
print(df.columns)
# 执行df.shape会返回一个元组,该元组的第一个元素代表行数,第二个元素代表列数
# 这就是这个数据的基本形状,也是数据的大小
print(df.shape)
结果:
Index(['reviewerID', 'asin', 'reviewerName', 'helpful', 'reviewText',
'overall', 'summary', 'unixReviewTime', 'reviewTime'],
dtype='object')
(278677, 9)
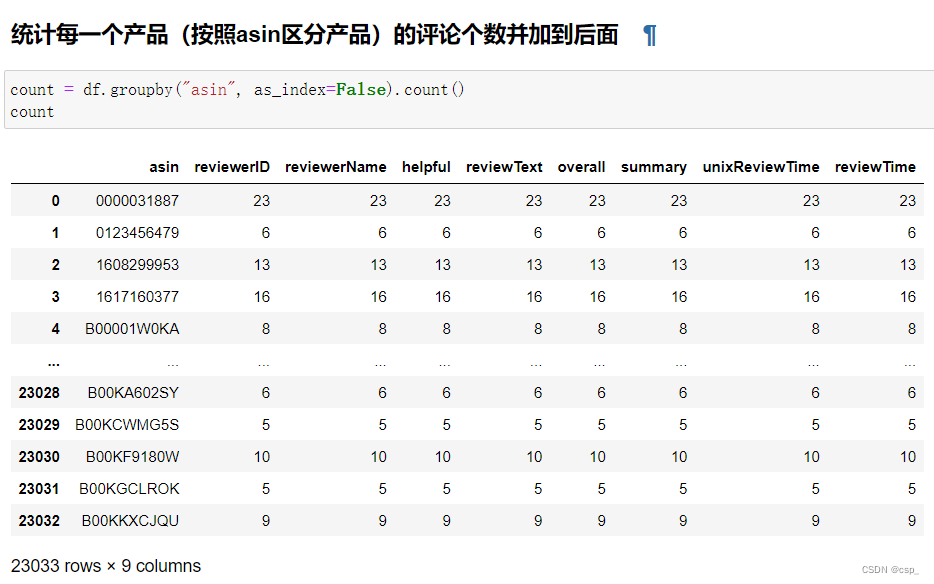
统计每一个产品(按照asin区分产品)的评论个数并加到后面:
count = df.groupby("asin", as_index=False).count()
# mean求均值,但在这里没有用到
mean = df.groupby("asin", as_index=False).mean()
# 将count连接在df后面
dfMerged = pd.merge(df, count, how='right', on=['asin'])
dfMerged
一些函数用法:
Pandas中groupby的参数as_index的True与False
结果:
reviewerID_x asin reviewerName_x helpful_x reviewText_x overall_x summary_x unixReviewTime_x reviewTime_x reviewerID_y reviewerName_y helpful_y reviewText_y overall_y summary_y unixReviewTime_y reviewTime_y
0 A1KLRMWW2FWPL4 0000031887 Amazon Customer "cameramom" [0, 0] This is a great tutu and at a really great pri... 5 Great tutu- not cheaply made 1297468800 02 12, 2011 23 23 23 23 23 23 23 23
1 A2G5TCU2WDFZ65 0000031887 Amazon Customer [0, 0] I bought this for my 4 yr old daughter for dan... 5 Very Cute!! 1358553600 01 19, 2013 23 23 23 23 23 23 23 23
...
当然如果我们输出中间结果count表格,可以看到其每一列信息都是一样的数字(即评论个数):
dfMerged最后增加3列信息:
dfMerged["totalReviewers"] = dfMerged["reviewerID_y"]
dfMerged["overallScore"] = dfMerged["overall_x"]
dfMerged["summaryReview"] = dfMerged["summary_x"]
结果:
reviewerID_x asin reviewerName_x helpful_x reviewText_x overall_x summary_x unixReviewTime_x reviewTime_x reviewerID_y reviewerName_y helpful_y reviewText_y overall_y summary_y unixReviewTime_y reviewTime_y totalReviewers overallScore summaryReview
0 A1KLRMWW2FWPL4 0000031887 Amazon Customer "cameramom" [0, 0] This is a great tutu and at a really great pri... 5 Great tutu- not cheaply made 1297468800 02 12, 2011 23 23 23 23 23 23 23 23 23 5 Great tutu- not cheaply made
1 A2G5TCU2WDFZ65 0000031887 Amazon Customer [0, 0] I bought this for my 4 yr old daughter for dan... 5 Very Cute!! 1358553600 01 19, 2013 23 23 23 23 23 23 23 23 23 5 Very Cute!!
...
把dfMerged按照totalReviewers排序(递减)并选择评论数超过100条的产品存入dfCount:
dfMerged = dfMerged.sort_values(by='totalReviewers', ascending=False)
dfCount = dfMerged[dfMerged.totalReviewers >= 100]
dfCount
结果:
reviewerID_x asin reviewerName_x helpful_x reviewText_x overall_x summary_x unixReviewTime_x reviewTime_x reviewerID_y reviewerName_y helpful_y reviewText_y overall_y summary_y unixReviewTime_y reviewTime_y totalReviewers overallScore summaryReview
161700 A205ZO9KZY2ZD2 B005LERHD8 Winnie [0, 0] I was expecting it to be more of a gold tint w... 4 It's ok 1357776000 01 10, 2013 441 441 441 441 441 441 441 441 441 4 It's ok
161269 A1HFSY6W8LJNJM B005LERHD8 Alicia7tommy "Alicia Andrews" [0, 0] The owl necklace is really cute but made real ... 4 Really Cute 1343001600 07 23, 2012 441 441 441 441 441 441 441 441 441 4 Really Cute
...
对每个产品求其评分overall的均值:
首先看一下df:
df
结果:
reviewerID asin reviewerName helpful reviewText overall summary unixReviewTime reviewTime
0 A1KLRMWW2FWPL4 0000031887 Amazon Customer "cameramom" [0, 0] This is a great tutu and at a really great pri... 5 Great tutu- not cheaply made 1297468800 02 12, 2011
1 A2G5TCU2WDFZ65 0000031887 Amazon Customer [0, 0] I bought this for my 4 yr old daughter for dan... 5 Very Cute!! 1358553600 01 19, 2013
...
之后求均值(仅保留可以取均值的那些列)到 dfProductReview:
dfProductReview = df.groupby("asin", as_index=False).mean()
dfProductReview
结果:
asin overall unixReviewTime
0 0000031887 4.608696 1.370064e+09
1 0123456479 4.166667 1.382947e+09
...
把评论的概要summary按照asin分组提取出来到ProductReviewSummary,并保存到ProductReviewSummary.csv文件中:
ProductReviewSummary = dfCount.groupby("asin")["summaryReview"].apply(list)
ProductReviewSummary = pd.DataFrame(ProductReviewSummary)
ProductReviewSummary.to_csv("ProductReviewSummary.csv")
ProductReviewSummary
结果:
asin summaryReview
B000072UMJ [Love it, Weird sizing on the tag..., Great Sh...
B0000ANHST [It's a carhartt what more can you say, Nice, ...
...
从ProductReviewSummary读出summary到df3,后面接上含有均值信息的dfProductReview,之后把无关列unixReviewTime去掉(也就是保留'asin','summaryReview','overall'这3列)到df3:
df3 = pd.read_csv("ProductReviewSummary.csv")
df3 = pd.merge(df3, dfProductReview, on="asin", how='inner')
df3 = df3[['asin','summaryReview','overall']]
df3
结果:
asin summaryReview overall
0 B000072UMJ ['Love it', 'Weird sizing on the tag...', 'Gre... 4.594595
1 B0000ANHST ["It's a carhartt what more can you say", 'Nic... 4.487179
...
对评论列进行文本清理
定义文本清理函数cleanReviews:
#用于文本清理的函数
#匹配以a-z开头的字符串
regEx = re.compile('[^a-z]+')
def cleanReviews(reviewText):
reviewText = reviewText.lower()
#删除空格
reviewText = regEx.sub(' ', reviewText).strip()
return reviewText
re.sub (pattern, replacement, string)将所有出现的 pattern 替换为提供的字符串中的 replacement。 这个方法的行为类似于 Python 字符串方法 str.sub,但是使用正则表达式来匹配模式,具体可看:
Python学习,python的re模块,正则表达式用法详解,正则表达式中括号的用法
重置索引并删除重复行(可看:(Python)Pandas reset_index()用法总结):
df3["summaryClean"] = df3["summaryReview"].apply(cleanReviews)
#Pandas-去除重复项函数drop_duplicates()
df3 = df3.drop_duplicates(['overall'], keep='last')
#重置索引时,将旧索引添加为列,并使用新的顺序索引
df3 = df3.reset_index()
df3
结果:
index asin summaryReview overall summaryClean
0 0 B0000ANHST ["It's a carhartt what more can you say", 'Nic... 4.487179 it s a carhartt what more can you say nice hea...
1 1 B0000C321X ['NIce fit, nice wash', 'nice', 'nada mejor', ... 4.263415 nice fit nice wash nice nada mejor levi s orig...
...
文本特征提取
从df3中提取清洗后的评论summaryClean放入reviews,之后用sklearn的CountVectorizer进行文本特征提取,对于每一个训练文本,其只考虑每种词汇在该训练文本中出现的频率:
reviews = df3["summaryClean"]
# max_features:对所有关键词的term frequency进行降序排序,只取前max_features个作为关键词集
# 停用词设为'english',这类词是可以完全忽略掉,不做统计的
countVector = CountVectorizer(max_features = 300, stop_words='english')
transformedReviews = countVector.fit_transform(reviews)
dfReviews = DataFrame(transformedReviews.A, columns=countVector.get_feature_names())
dfReviews = dfReviews.astype(int)
dfReviews
同样我们注意到有些单词对情感分类是毫无意义的,这类词有个名字,叫“Stop_Word”(停用词),这类词是可以完全忽略掉不做统计的,显然忽略掉这些词,词频记录的存储空间能够得到优化,而且构建速度也更快
在csdn上关于stop_words的介绍很模糊,可在stackoverflow找到一些见解(可看:scikit learn classifies stopwords)
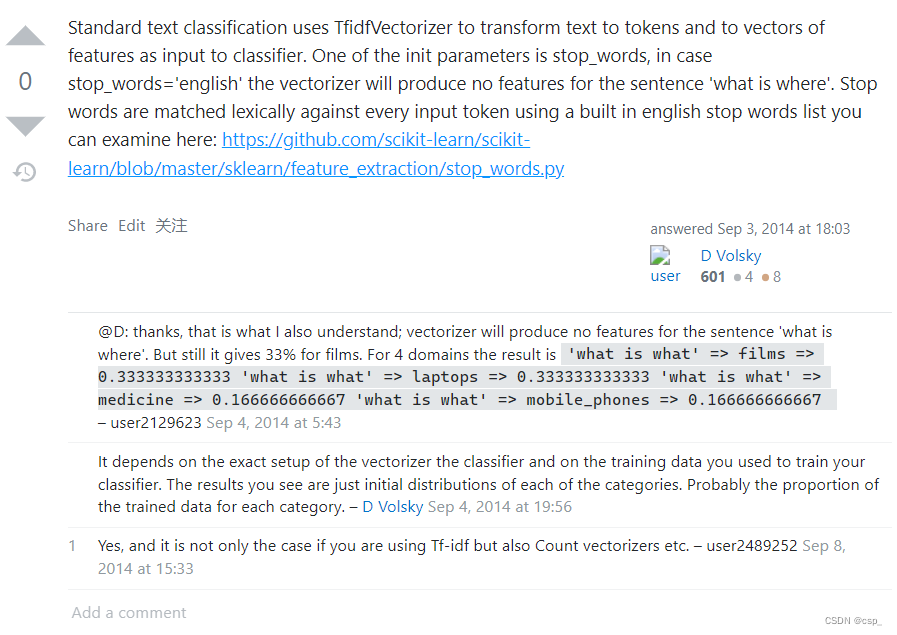
还有一些很有用的博客:
【SKLEARN】使用CountVector类来提取词频特征,并计算其TF-IDF特征(含可执行代码)
结果:
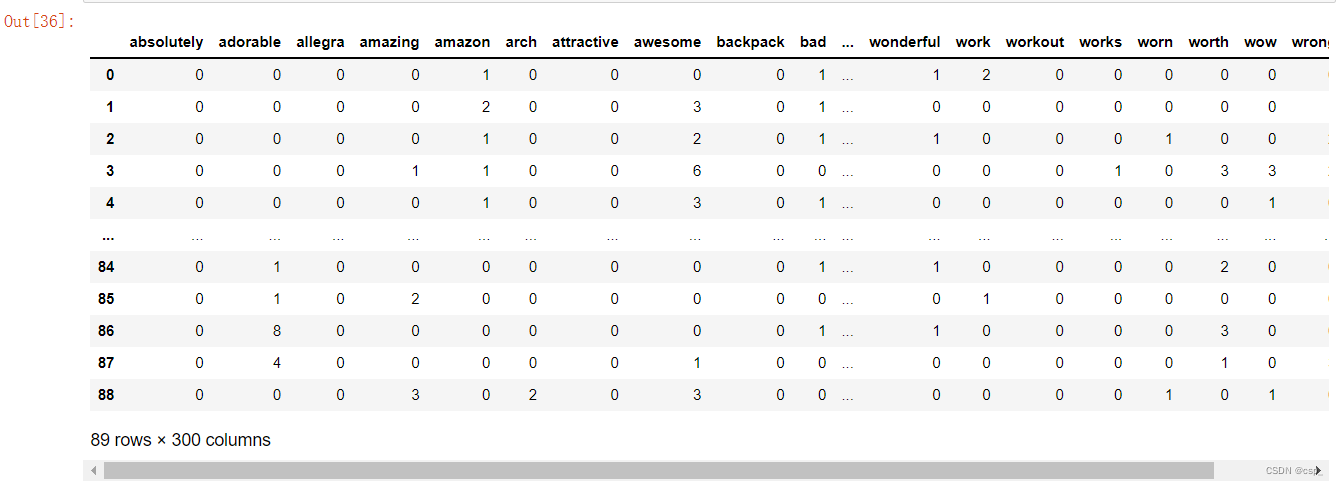
把dfReviews保存至dfReviews.csv:
# 保存
dfReviews.to_csv("dfReviews.csv")
KNN分类器寻找相似产品
创建数据集和测试集:
# 创建一个名为X的数据集
X = np.array(dfReviews)
# 创建数据集和测试集
tpercent = 0.9
tsize = int(np.floor(tpercent * len(dfReviews)))
dfReviews_train = X[:tsize]
dfReviews_test = X[tsize:]
#数据集和测试集的长度
lentrain = len(dfReviews_train)
lentest = len(dfReviews_test)
print(lentrain)
print(lentest)
结果:
80
9
之后用k最近邻算法(据说是最简单的机器学习算法QAQ)查找最相关的产品
k最近邻算法可看博客:knn scikit_Scikit学习-KNN学习
当然阅读国外介绍也可以,比国内详细很多,在这里说一下,国外的自成体系,如果要详细研究,一定要亲自读外文(sklearn.impute.KNNImputer):
记得老师上课讲了一下,有中英文2个机器学习网站(scikit-learn)是常用的,一定要多看:
1:scikit-learn Machine Learning in Python
2:scikit-learn (sklearn) 官方文档中文版
代码:
neighbor = NearestNeighbors(n_neighbors=3, algorithm='ball_tree').fit(dfReviews_train)
# 为了在对象X中找到每个点的k邻域,需要在对象X上调用kneighbors()函数
distances, indices = neighbor.kneighbors(dfReviews_train)
# 查找最相关的产品
for i in range(lentest):
a = neighbor.kneighbors([dfReviews_test[i]])
related_product_list = a[1]
first_related_product = [item[0] for item in related_product_list]
first_related_product = str(first_related_product).strip('[]')
first_related_product = int(first_related_product)
second_related_product = [item[1] for item in related_product_list]
second_related_product = str(second_related_product).strip('[]')
second_related_product = int(second_related_product)
print ("Based on product reviews, for ", df3["asin"][lentrain + i] ," average rating is ",df3["overall"][lentrain + i])
print ("The first similar product is ", df3["asin"][first_related_product] ," average rating is ",df3["overall"][first_related_product])
print ("The second similar product is ", df3["asin"][second_related_product] ," average rating is ",df3["overall"][second_related_product])
print ("-----------------------------------------------------------")
结果:
Based on product reviews, for B008RUOCJU average rating is 3.973684210526316
The first similar product is B007WAEBPQ average rating is 4.333333333333333
The second similar product is B004R1II48 average rating is 4.055555555555555
-----------------------------------------------------------
Based on product reviews, for B008WYDP1C average rating is 4.257028112449799
The first similar product is B007WA3K4Y average rating is 4.209424083769633
The second similar product is B0083S18LQ average rating is 3.9565217391304346
-----------------------------------------------------------
Based on product reviews, for B008X0EW44 average rating is 3.874125874125874
The first similar product is B007WAEBPQ average rating is 4.333333333333333
The second similar product is B0083S18LQ average rating is 3.9565217391304346
-----------------------------------------------------------
Based on product reviews, for B009DNWFD0 average rating is 3.8446601941747574
The first similar product is B0053XF2U2 average rating is 3.8684210526315788
The second similar product is B004R1II48 average rating is 4.055555555555555
-----------------------------------------------------------
Based on product reviews, for B009ZDEXQK average rating is 4.7254901960784315
The first similar product is B000EIJG0I average rating is 4.594594594594595
The second similar product is B001Q5QLP6 average rating is 4.673913043478261
-----------------------------------------------------------
Based on product reviews, for B00BNB3A0W average rating is 3.4414414414414414
The first similar product is B004Z1CZDK average rating is 3.1923076923076925
The second similar product is B0053XF2U2 average rating is 3.8684210526315788
-----------------------------------------------------------
Based on product reviews, for B00CIBCJ62 average rating is 4.2164179104477615
The first similar product is B004R1II48 average rating is 4.055555555555555
The second similar product is B007WAEBPQ average rating is 4.333333333333333
-----------------------------------------------------------
Based on product reviews, for B00CKGB85I average rating is 4.066666666666666
The first similar product is B004R1II48 average rating is 4.055555555555555
The second similar product is B0074T7TY0 average rating is 4.255474452554744
-----------------------------------------------------------
Based on product reviews, for B00CN47GXA average rating is 3.4634146341463414
The first similar product is B007WAU1VY average rating is 3.551470588235294
The second similar product is B007WAEBPQ average rating is 4.333333333333333
-----------------------------------------------------------
Based on product reviews, for B00D1MR8YU average rating is 3.83739837398374
The first similar product is B004R1II48 average rating is 4.055555555555555
The second similar product is B0053XF2U2 average rating is 3.8684210526315788
-----------------------------------------------------------
Based on product reviews, for B00DMWQK0W average rating is 4.298076923076923
The first similar product is B0078FXHNM average rating is 4.26056338028169
The second similar product is B007WAEBPQ average rating is 4.333333333333333
-----------------------------------------------------------
Based on product reviews, for B00DMWQOYY average rating is 4.119718309859155
The first similar product is B0067GUM2W average rating is 4.174863387978142
The second similar product is B0078FXHNM average rating is 4.26056338028169
-----------------------------------------------------------
Based on product reviews, for B00DNQIIE8 average rating is 4.228758169934641
The first similar product is B0078FXHNM average rating is 4.26056338028169
The second similar product is B0067GUM2W average rating is 4.174863387978142
-----------------------------------------------------------
Based on product reviews, for B00DQYNS3I average rating is 4.526315789473684
The first similar product is B003YBHF82 average rating is 4.21
The second similar product is B000FH4JJQ average rating is 4.536363636363636
-----------------------------------------------------------
按照格式打印数据:
# 按照格式打印数据
# print ("Based on product reviews, for ", df3["asin"][260] ," average rating is ",df3["overall"][260])
print ("The first similar product is ", df3["asin"][first_related_product] ," average rating is ",df3["overall"][first_related_product])
print ("The second similar product is ", df3["asin"][second_related_product] ," average rating is ",df3["overall"][second_related_product])
print ("-----------------------------------------------------------")
结果:
The first similar product is B003YBHF82 average rating is 4.21
The second similar product is B000FH4JJQ average rating is 4.536363636363636
-----------------------------------------------------------
预测评分:
df5_train_target = df3["overall"][:lentrain]
df5_test_target = df3["overall"][lentrain:lentrain+lentest]
df5_train_target = df5_train_target.astype(int)
df5_test_target = df5_test_target.astype(int)
n_neighbors = 3
knnclf = neighbors.KNeighborsClassifier(n_neighbors, weights='distance')
knnclf.fit(dfReviews_train, df5_train_target)
knnpreds_test = knnclf.predict(dfReviews_test)
print(classification_report(df5_test_target, knnpreds_test))
结果:
precision recall f1-score support
3 1.00 1.00 1.00 3
4 1.00 1.00 1.00 6
avg / total 1.00 1.00 1.00 9
模型的准确性:
print (accuracy_score(df5_test_target, knnpreds_test))
print(mean_squared_error(df5_test_target, knnpreds_test))
结果:
1.0
0.0
基于聚类的词关联
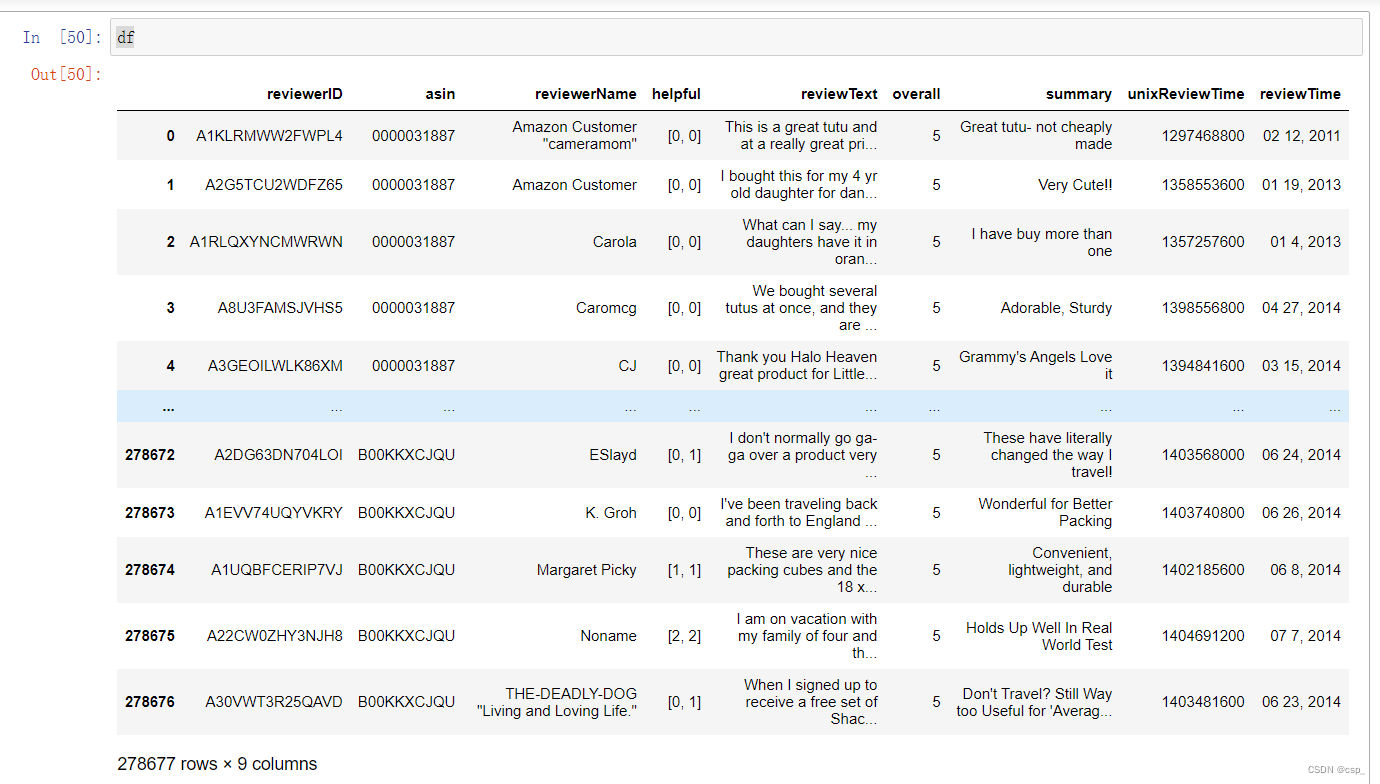
先看一下df:
df
结果:
之后按照评分归类评论:
cluster = df.groupby("overall")["summary"].apply(list)
cluster
结果:
overall
1 [Never GOT IT...., DO NOT BUY IF YOU EVER WANT...
2 [too short, I'm glad i bought back up straps, ...
3 [Came apart in 2weeks!, Arrived with a defect,...
4 [It's ok, Good, Practically Perfect in every w...
5 [Great tutu- not cheaply made, Very Cute!!, I...
Name: summary, dtype: object
把聚类后的数据转换为Dataframe型:
可参考:dataframe数据标准化处理_pandas用法及数据预处理实例
cluster = pd.DataFrame(cluster)
cluster
结果:

保存到cluster.csv,把数据从cluster.csv导入cluster1并清洗数据:
cluster.to_csv("cluster.csv")
cluster1 = pd.read_csv("cluster.csv")
cluster1["summaryClean"] = cluster1["summary"].apply(cleanReviews)
cluster1
结果:

可视化每个分数组的单词云:
stopwords = set(STOPWORDS)
def show_wordcloud(data, title = None):
wordcloud = WordCloud(
background_color='white',
stopwords=stopwords,
max_words=500,
max_font_size=30,
scale=3,
random_state=1 # chosen at random by flipping a coin; it was heads
).generate(str(data))
fig = plt.figure(1, figsize=(8, 8))
plt.axis('off')
if title:
fig.suptitle(title, fontsize=20)
fig.subplots_adjust(top=2.3)
plt.imshow(wordcloud)
plt.show()
注意:为了展示不同分数评论的云图,需要使汉字在图表中显示,需要加上#coding:utf-8并用matplotlib.use('qt4agg') 来指定默认字体,用matplotlib.rcParams['axes.unicode_minus'] = False来解决负号’-'显示为方块的问题,否则会报错
#coding:utf-8
import matplotlib
matplotlib.use('qt4agg')
#指定默认字体
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
matplotlib.rcParams['font.family']='sans-serif'
#解决负号'-'显示为方块的问题
matplotlib.rcParams['axes.unicode_minus'] = False
之后展示不同分数评论的云图:
show_wordcloud(cluster1["summaryClean"][0], title = "1分的评论")

show_wordcloud(cluster1["summaryClean"][1] , title = "2分的评论")
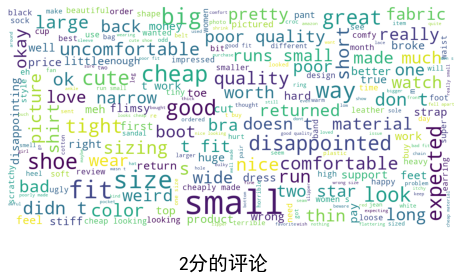
show_wordcloud(cluster1["summaryClean"][2], title = "3分的评论")
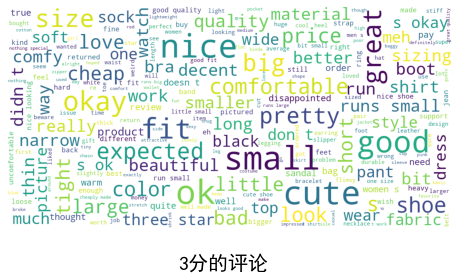
show_wordcloud(cluster1["summaryClean"][3], title = "4分的评论")

show_wordcloud(cluster1["summaryClean"][4], title = "5分的评论")

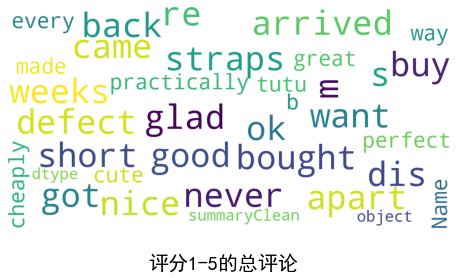
show_wordcloud(cluster1["summaryClean"][:], title = "评分1-5的总评论")