文章目录
论文链接
Arabic Dialect Identification with a Few Labeled Examples Using Generative Adversarial Networks
摘要
考虑到在处理阿拉伯方言(DA)变化时引入的挑战和复杂性,基于Transformer的模型,例如BERT,在处理DA识别任务方面优于其他模型。然而,要对这些模型进行微调,需要大量的语料库。为一些阿拉伯语方言课程获取大量高质量的示例是具有挑战性和耗时的。
在这篇文章中,我们讨论阿拉伯语方言识别任务。
我们扩展了基于Transformer的模型(ARBERT和MARBERT)使用 半监督生成对抗网络(SS-GAN)在生成对抗设置中使用未分类数据。我们的模型能够为阿拉伯语方言样本 生成高质量的嵌入,并帮助模型更好地泛化下游分类任务。
实验结果表明,在标记样本较少的情况下,该模型具有更好的性能和更快的收敛速度。
1.contribution
在本文中,我们扩展了基于bert的模型[ARBERT和MARBERT (Abdul-Mageed等人,2021a)],使用半监督生成对抗网络(SS-GAN) (Salimans等人,2016) 在生成对抗设置中使用未分类数据。这种设置利用了一组容易获得的未标记数据,在给定几个标记示例的情况下,可以更好地对方言识别任务进行泛化。半监督学习与广告网络以前被用于一些任务和语言,但据我们所知,它还没有被用于阿拉伯语方言识别。
这项工作的 贡献 是:
-
在ARBERT和MARBERT模型上采用GAN (Goodfellow et al., 2014)的半监督设置。这大大减少了数据处理识别任务对大型数据集的需求。我们的模型使用非常小的训练数据集胜过基于bert的模型。
-
我们利用扩展的GAN模型,在非常小的训练数据集上研究方言语音的分类。训练集从4个不同的阿拉伯数据集中采样:QADI (Abdelali等人,2021)、NADI 2021 (Abdul-Mageed等人,2021b)、ArSar- casm (Bashmal和AlZeer, 2021)和AOC (Zaidan和callson - burch, 2011)。样本大小从整个训练数据集的0.01%到10%不等。
-
我们应用了一个两阶段的设置,训练GAN扩展模型的一些时代,然后进行第二阶段的基于bert的模型训练。这些早期GAN时代提高了基于bert的模型收敛速度和性能结果。在相同的epoch数下,2阶段实验优于基于bert的模型。
Adopted Model
3.1 Motivation
半监督生成对抗网络(SS-GAN) (Salimans等人,2016)可以在半监督设置中作为额外的信息来源。SS-GAN可以捕获训练样例的特征,并生成与真实训练样例几乎无法区分的相似样例。
3.2 Model Architecture
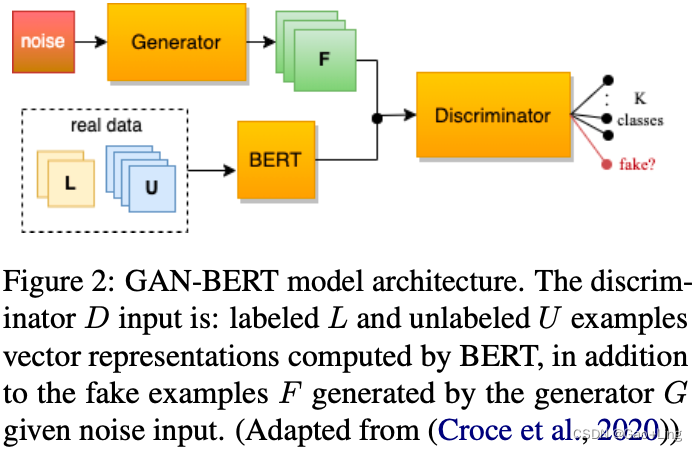
我们的工作主要基于GAN-BERT模型(Croce et al., 2020),该模型从SS-GAN的角度丰富了BERT微调过程。半监督GAN (SS-GAN) (Salimans等人,2016)是一种生成式对抗网络(Goodfellow等人,2014),以多类分类器作为其判别器。它不是学习区分两个类(真实的和假的),而是学习区分K+1个类,其中K是训练数据集中的类数,加上1是生成器生成的假示例。生成器的输入是一个随机噪声向量,生成器的目标是生成的fake examples,这些样本与真实的数据集示例无法区分。
在这项工作中,我们使用SS-GAN扩展了基于bert的模型。我们使用在阿拉伯数据集上预训练的基于bert的模型,即ARBERT和MARBERT (Abdul-Mageed et al., 2021a),并通过在SS-GAN层之外添加任务特定层来适应微调,以实现半监督学习。
Discriminator有3个输入:
- fake examples generated by the Generator (x*)
生成器生成的假示例(x*) - real unlabeled examples (x)
真实的未标记示例(x) - real labeled training examples (x, y), with y denoting the label for the given example x.
真实的标记训练示例(x, y),其中y表示给定示例x的标签。
总结:
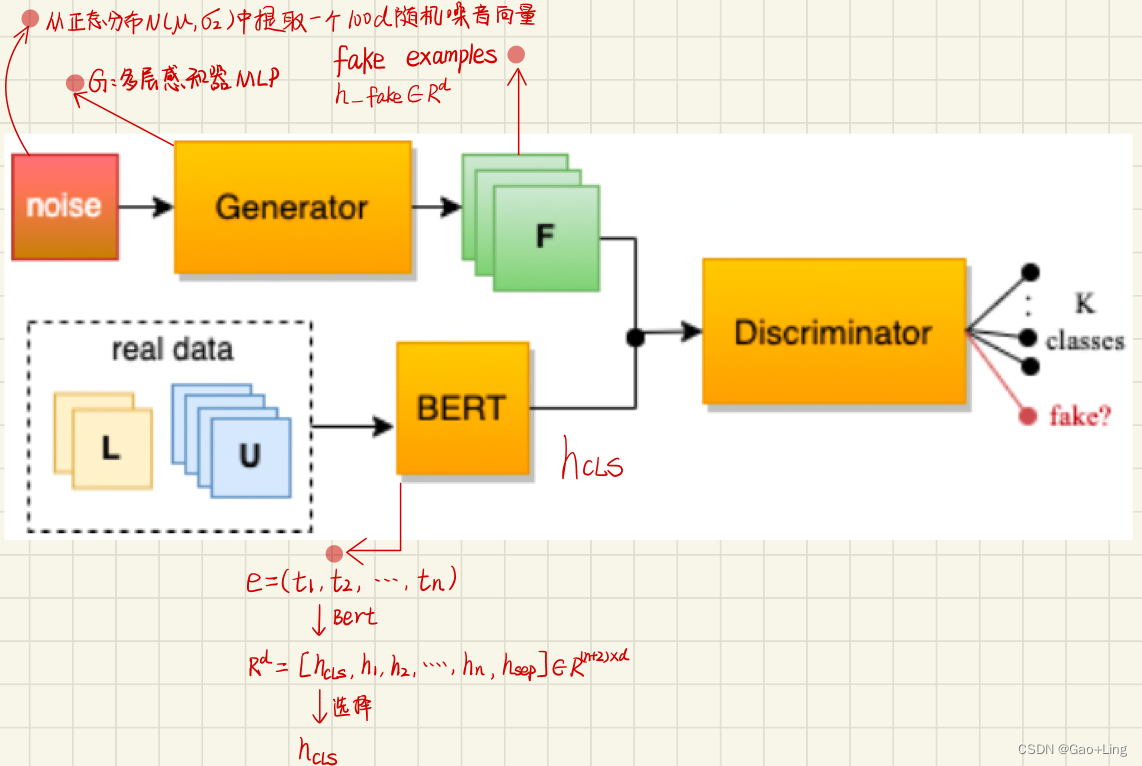
- Generator 路:
- input:从正态分布N(μ,σ2)中提取的
一个100维随机噪声向量 - output:一个向量
h_fake ∈ R^d - 生成器G是一个多层感知器(MLP)
- input:从正态分布N(μ,σ2)中提取的
- BERT 路:
- input example:
e = (t_1,t_2,,..,t_n) - BERT模型的输出:n+2向量表示:
R^d[ (h_CLS,h_1,h_2,…,h_SEP) ] - 正如(Devlin et al., 2019)所建议的,
h_CLS ∈ R^d被用于识别任务的例句嵌入。
- input example:
- Discriminator 路:
- input:Generator 路 和 BERT 路的output:记为:
h_∗ = {h_fake, h_CLS} ∈ R^d - 鉴别器G是另一个多层感知器(MLP),它的最后一层是一个输出k+1个对数向量的softmax层
真实分布中的真实例子分为(1,…, k)类,而生成的假样本被分类到额外的k1类。
- input:Generator 路 和 BERT 路的output:记为:
- 注释:
- 当更新Discriminator时,基于bert的模型权重也被改变,以便同时考虑标记和未标记的例子,以更好地微调它们的内部表示。
- 在评估时,生成器被丢弃,同时保留模型的其余部分,这意味着与标准的基于bert的模型相比,在推理时间上没有额外的成本。
Experimental Results
Semi-Supervised Setting: GAN-MARBERT and GAN-ARBERT
我们使用macro-F1 score作为模型的评估指标。宏观f1分数是方言识别任务的标准评价指标。
如第3节所讨论的,我们用生成对抗设置扩展基于BERT的模型。生成器G是一个具有单个隐藏层的MLP,该隐藏层由泄漏的relu函数激活。生成器G的输入是从正态分布N(0,1)中提取的随机噪声向量。生成器G的输出是一个768维的向量,表示假生成的示例。鉴别器D是另一个类似的MLP,具有用于最终方言分类的最终softmax层。在G和D的隐藏层之后,我们使用0.2的dropout率。
我们选择了表现最好的基于bert的预训练模型作为每个数据集的基础模型,如(Abdul-Mageed et al., 2021a)所述。对于QADI、NADI和AOC,选择的基本模型是MARBERT。而ArSarcasm的基本模式是ARBERT。
Two-Stages Setup: Using a BERT-based model after the GAN-BERT
在这个设置中,我们评估一个2-Stages的设置。
- 第一阶段是使用GAN扩展对基于BERT的模型进行5个epoch的训练。
- 在第二阶段,消除GAN模块,并对基于BERT的模型进行另外5次训练。
使用更小的训练集样本,与单独的基于bert的模型相比,第一阶段提高了整体模型结果的性能。
实验结果如图4所示。在这两种设置中,我们使用相同的lr = 2e-5和sequence length = 40。对于QADI和AOC数据集,我们使用了0.01%、0.02%和0.05%的注释样本。对于NADI和ArSarcasm,我们分别使用了训练数据集的1%、2%和5%。
Conclusion
阿拉伯语方言识别任务的主要挑战之一是高质量标记示例的稀缺性。本文通过采用对抗性训练来实现半监督学习来解决这个问题。它将这种方法应用于两个基于BERT的模型,即MARBERT和ARBERT。实验结果表明,GAN扩展提高了基于bert的模型的性能。
本文还介绍了一种两阶段的设置,即对带有GAN成分扩展的基本模型进行5个epoch的训练,然后去掉GAN成分,单独训练基础模型进行5个epoch的训练。采用的方法使用非常小的训练集,可以帮助基础模型更好地泛化和更快地收敛,并且在推理时间上没有额外的成本。
在基于bert的模型之上添加SS-GAN模块,给出了一些标记的数据集示例,从经验上显示了性能的增强和更快的收敛,这验证了我们的假设。